The paper introduces OmniVTA, a hierarchical visuo-tactile world-model framework for contact-rich robotic manipulation. It leverages the new OmniViTac dataset—comprising 21,000+ trajectories across 86 tasks—to produce a predictive visuo-tactile world model and a 60Hz reflexive controller, achieving SOTA performance in tasks like wiping, assembly, and cutting.
TL;DR
OmniVTA is a breakthrough framework that gives robots a "sense of touch" with foresight. By combining a massive new dataset (OmniViTac) with a Visuo-Tactile World Model, the system doesn't just react to touch—it predicts how contact will evolve. This allows a dual-speed control system to perform delicate tasks like peeling, wiping, and assembly even under heavy external disturbances.
The "Blind Spot" in Current Robotics
While vision-based AI has seen explosive growth, robots remain surprisingly clumsy in "contact-rich" scenarios. If you try to assemble a tiny connector or wipe a surface while blindfolded, you rely on the physics of interaction—friction, shear, and resistance.
Existing methods fail because:
- Data Scarcity: We have millions of videos, but very few synchronized "vision + touch + action" datasets.
- Passive Integration: Most models treat tactile data like a late-arriving text notification—observed but not anticipated.
Methodology: Anticipation and Reflex
The core philosophy of OmniVTA is inspired by human neuroscience: our brains use internal models to predict the sensory consequences of our actions.
1. TactileVAE: Sensing the Continuous Surface
Instead of treating tactile images as raw pixels, OmniVTA uses an Implicit Neural Representation (INR). It treats the tactile sensor not as a grid, but as a continuous deformation field. This allows for high-frequency feature extraction without losing the nuanced geometry of contact.
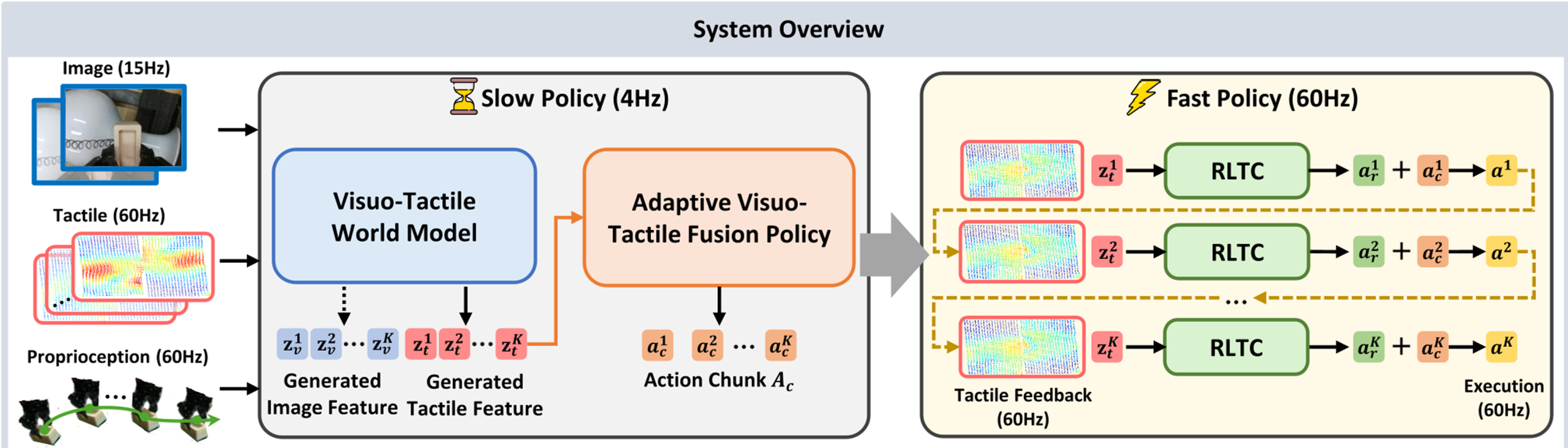
2. The Slow-Fast Hierarchy
The framework splits control into two loops:
- The Slow Policy (15Hz): Uses a World Model to imagine the immediate future. It asks: "If I move the knife this way, what will the force feel like in 100ms?"
- The Fast Policy (60Hz): A reflexive controller. It compares the observed touch to the predicted touch. If there's a discrepancy (e.g., the object slipped), it fires a corrective command instantly.
3. Adaptive Gating: When to Trust Touch?
OmniVTA introduces a Latent Tactile Differential (LTD) Encoder. By looking at the "delta" between current and predicted touch, the model decides how much to "weight" tactile info versus visual info. For example, during the "approach" phase of grasping, vision dominates. The moment contact is made, the gating mechanism pivots weight to tactile feedback.
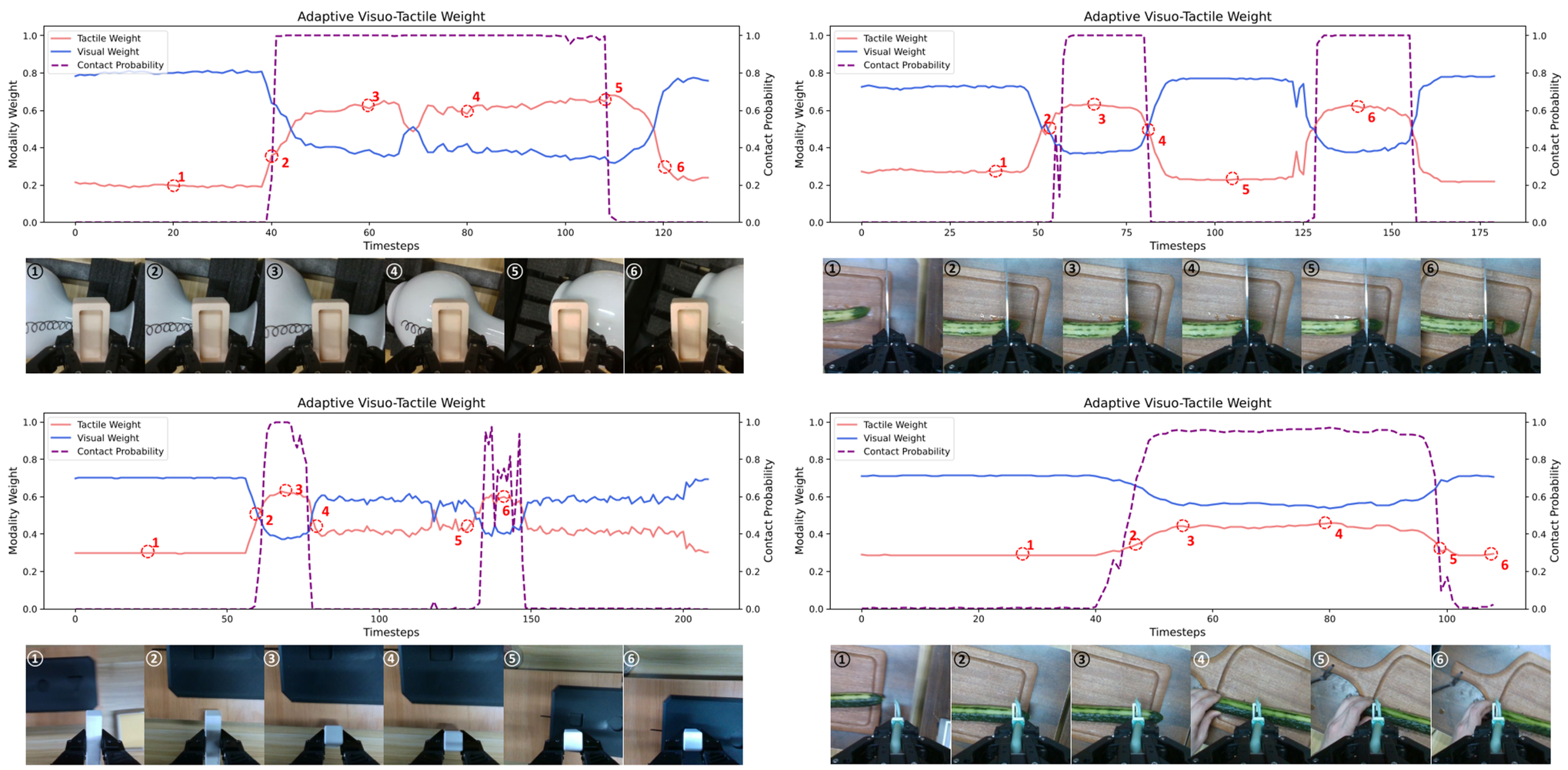
Experiments: Real-World Resilience
The authors put OmniVTA to the test across 86 tasks. The results were clear:
- Geometric Generalization: The robot learned to wipe surfaces at heights it had never seen during training.
- Tool Generalization: It could cut a cucumber using a completely different knife model, proving it learned the physics of cutting rather than just mimicking a trajectory.
- Disturbance Recovery: When an object was suddenly shoved mid-manipulation, OmniVTA's reflexive controller re-established contact within milliseconds, while standard Diffusion Policies typically failed.

Critical Insight & Future Work
The most profound takeaway from OmniVTA is the Effective Contact Ratio. The authors found that for tasks like in-hand adjustment, tactile sensors are active 67% of the time, whereas for cutting, it's only 27%. This data-driven realization suggests that future robotic "Foundation Models" must be asymmetrically multimodal—they need to be able to "tune in" and "tune out" of tactile signals based on the task phase.
While OmniVTA is a giant leap, it currently relies on high-end hardware like the Xense or GelSight sensors. The next frontier will be scaling this "predictive touch" to cheaper, more robust resistive or capacitive skins, bringing "reflexive" robots to every household.
Final Summary
OmniVTA demonstrates that for a robot to be truly "embodied," it must not only see and do but also anticipate. By bridging the gap between high-level planning and low-level reflexes, it sets a new standard for dexterous robotic manipulation.