OmniWeaving is a unified video generation framework that integrates multimodal comprehension and generation through an MLLM-coupled Diffusion Transformer. It achieves SOTA performance among open-source models by supporting free-form interleaved text, image, and video inputs while introducing the "Reasoning-Augmented" generation paradigm.
TL;DR
OmniWeaving is a powerhouse unified video generation framework that "weaves" together text, multiple images, and video clips into a single spatio-temporal narrative. By coupling a Multimodal Large Language Model (MLLM) with a Diffusion Transformer (MMDiT), it moves beyond simple rendering to intelligent reasoning, effectively inferring user intent from ambiguous prompts. It sets a new open-source standard on the newly released IntelligentVBench.
The "Fragmented" Crisis in Video AI
While the industry is buzzing about "General World Models," the open-source reality is far more fragmented. Most current models are specialized "one-trick ponies": a model that excels at Text-to-Video (T2V) often sucks at Image-to-Video (I2V) or Video-to-Video (V2V) editing.
The core missing ingredient? Abstract Reasoning. Humans don't just want a girl running; they want "a girl reunited with her long-lost dog," a prompt that requires the AI to think about the emotional arc and causal sequence before generating pixels. Prior open-source work lacks this cognitive layer, treating inputs as rigid templates rather than semantic instructions.
Methodology: The "Comprehend-then-Generate" Pipeline
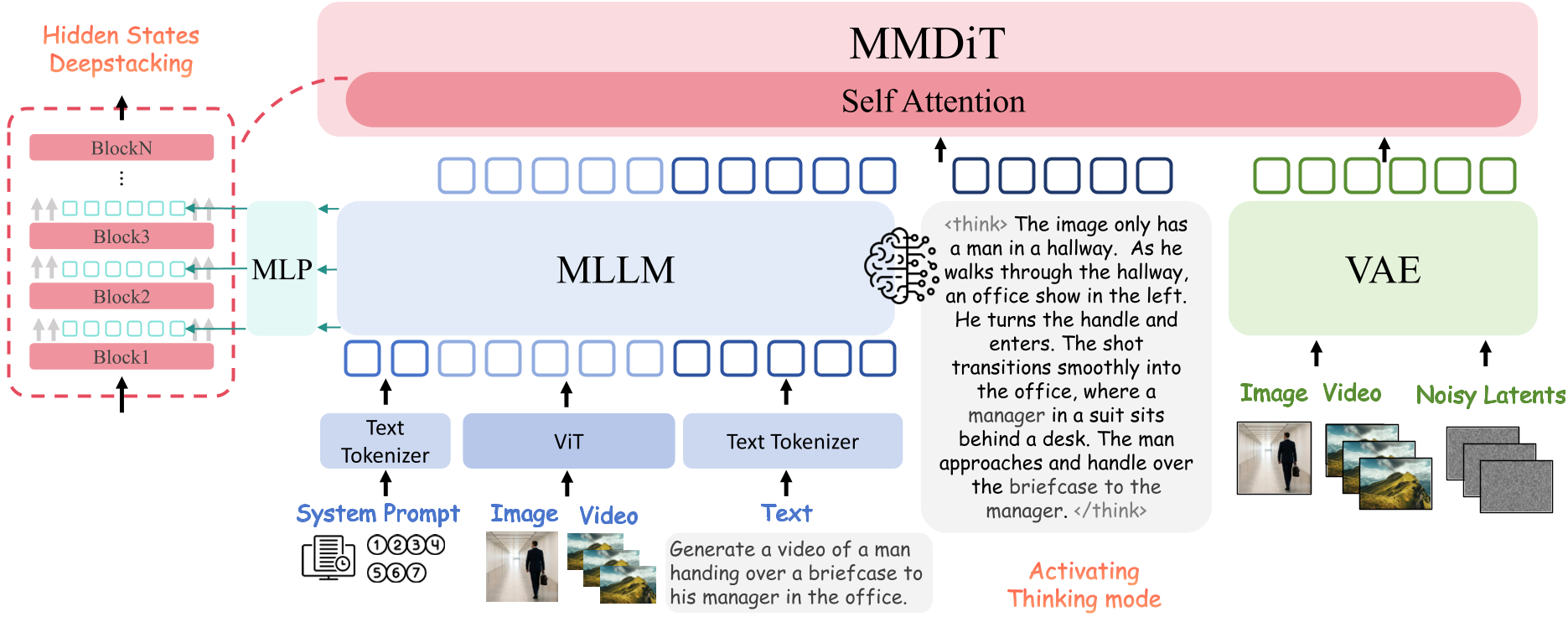
OmniWeaving's architecture is a sophisticated bridge between understanding and creation. It consists of three pillars:
- MLLM Semantic Parser (Qwen2.5-VL): Acts as the brain, projecting free-form multimodal inputs into a high-level semantic space.
- Activating "Thinking Mode": Instead of passing raw features, the MLLM is encouraged to generate intermediate reasoning chains (e.g., describing the physics and motion flow) before the diffusion process starts.
- DeepStacking mechanism: Unlike models that only use the last layer of an LLM, OmniWeaving stacks features from multiple layers (e.g., layers 8, 16, and 24) to capture both fine-grained details and high-level abstractions.
IntelligentVBench: A Higher Bar for Evaluation
The researchers correctly identified that current benchmarks like VBench are too simple (mostly single-shot). They introduced IntelligentVBench, which focuses on:
- Implicit I2V: Causal deduction from ambiguous text.
- Interpolative DI2V: Generating complex motion between two distant key-frames.
- Compositional MI2V: Merging several disparate subjects (from different images) into one scene.
- TIV2V: The hardest task—modifying a video using both text and reference images simultaneously.

Experiments & Results: Reasoning Matters
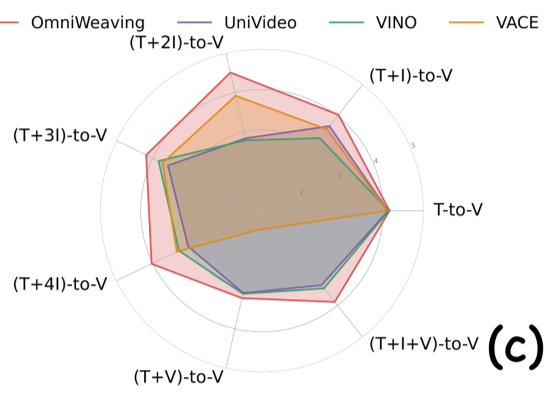
The results prove that "thinking" works. In the Implicit I2V task, activating the MLLM's thinking mode raised the Instruction Following (IF) score from 4.05 to 4.33, allowing OmniWeaving to surpass specialized models like Wan2.2.
In Compositional Multi-Image-to-Video, the model demonstrated an uncanny ability to maintain identity consistency across multiple subjects—a feat where rival unified models like VINO and UniVideo often failed by "merging" characters or ignoring background constraints.
Critical Insight & Potential
OmniWeaving’s most significant contribution isn't just a unified model; it's the data construction pipeline. By using a dual "output-first" and "input-first" strategy—leveraging VLMs to label real-world videos and using high-end models to synthesize missing task-specific data—they solved the scarcity problem of interleaved training pairs.
Limitations: The model still lags behind proprietary titans like Seedance-2.0 in raw resolution and modality diversity (e.g., it currently lacks integrated audio generation).
Future Outlook
The team envisions a future where video models are fully "omni-modal," handling synchronized audio-visual content with even more complex interleaved sequences. OmniWeaving is a massive leap toward the "GPT-4o moment" for video generation in the open-source community.