OneSearch-V2 is a generative search framework for e-commerce that enhances item retrieval by integrating latent reasoning and self-distillation. It utilizes a thought-augmented query understanding module and a novel Token-Position Marginal Advantage (TPMA-GRPO) reinforcement learning mechanism to achieve SOTA performance (+3.98% CTR, +3.45% GMV) on the Kuaishou Mall platform.
Executive Summary
TL;DR: OneSearch-V2 marks a significant evolution in Generative Retrieval (GR) by proving that large language model (LLM) reasoning capabilities can be distilled directly into a search model's parameters. By using a "keyword-based Chain-of-Thought (CoT)" and an asymmetric self-distillation pipeline, the system captures deep user intent and complex query semantics without adding a single millisecond to online inference latency.
Background: Deployed at scale within Kuaishou Technology, OneSearch-V2 is a state-of-the-art industrial implementation that replaces traditional multi-stage retrieval/ranking pipelines with a unified generative framework, pushing the boundaries of how e-commerce platforms handle long-tail and ambiguous queries.
Problem & Motivation: The "Shallow Matching" Trap
Current Generative Retrieval models represent items as Semantic IDs (SIDs). While efficient, they often overfit to historical user logs. This leads to two critical failures:
- Semantic Blindness: A query like "relieve fatigue, no supplements" might incorrectly retrieve vitamins because of high historical co-occurrence, failing to "reason" through the negation.
- The Inference Bottleneck: While LLMs can solve these via Chain-of-Thought (CoT), generating 100+ tokens of "thought" for every search query is too slow for real-time systems.
OneSearch-V2 asks: Can we give a model the "intuition" provided by reasoning without making it "speak" its thoughts?
Methodology: The Core Innovations
1. Keyword-based CoT & Intent Calibration
Rather than verbose sentences, the authors extract Keyword-based CoTs (Intent, Category, Attribute, Topic). This condenses the "logic" of a search into a high-density semantic anchor.
2. Reasoning-Internalized Self-Distillation
This is the "magic" of OneSearch-V2.
- Teacher: Receives the query + the Keyword-based CoTs.
- Student: Receives only the query.
- Alignment: The student is trained to match the teacher's output logit distribution. Since they share the same weights (Self-Distillation), the model learns to "internalize" the information provided by the keywords.
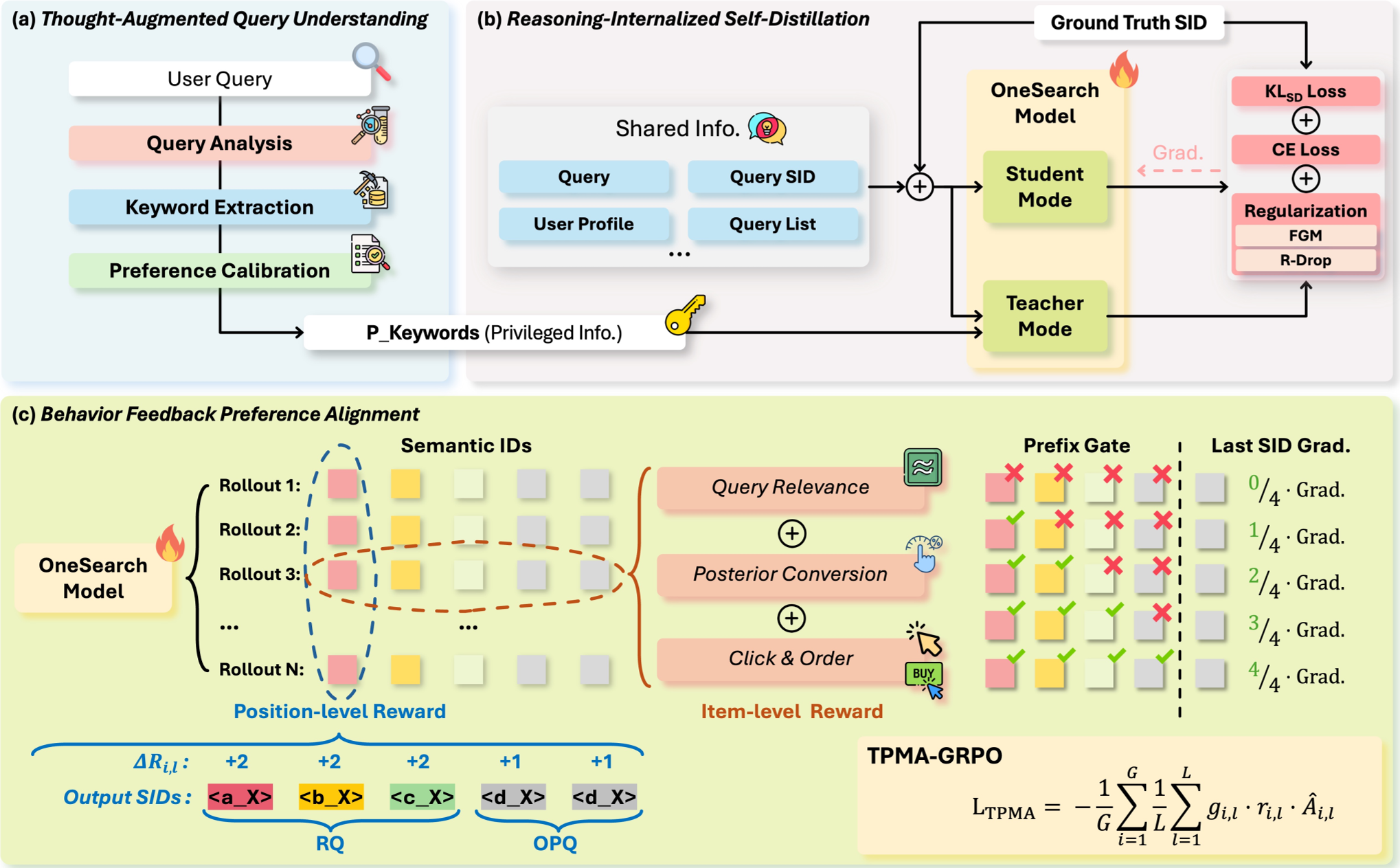
3. TPMA-GRPO: Hierarchical Credit Assignment
Standard Reinforcement Learning (RL) treats all tokens in a sequence equally. However, SIDs are hierarchical (Coarse Category $ o$ Fine Attribute). OneSearch-V2 introduces Token-Position Marginal Advantage (TPMA):
- Prefix Gating: If the first token (category) is wrong, the gradient for subsequent tokens is zeroed out.
- Positional Weighting: Early tokens (structural features) are given higher optimization priority.
Experiments & Results
The impact was immediate across Kuaishou's massive user base:
- Conversion: Buyer conversion rate climbed by 3.05%, and GMV increased by 3.45%.
- Robustness: Long-tail queries (the hardest to solve) saw the highest CTR gains (+5.37%), proving the reasoning module's effectiveness.
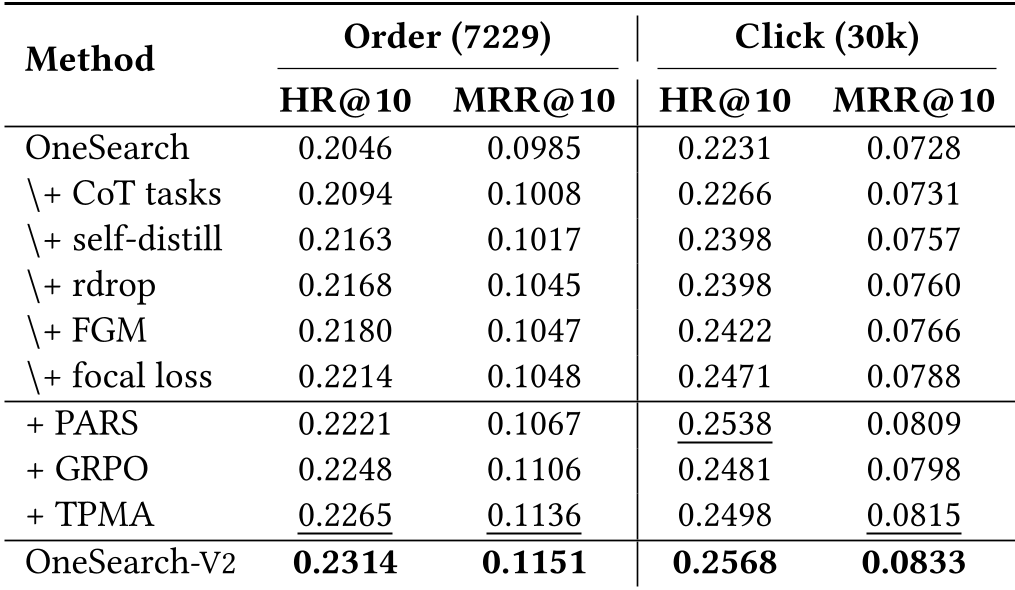
The ablation studies confirmed that Self-Distillation (S)—the distilled model running without keywords—actually outperformed the Teacher (T) model running with keywords in some scenarios, suggesting that the distillation process regularizes and strengthens the model's internal latent space.
Critical Analysis & Conclusion
Takeaway: OneSearch-V2 successfully bridges the gap between the "system 2" (slow, deliberate) reasoning of LLMs and the "system 1" (fast, intuitive) requirements of industrial search.
Limitations: Despite its success, the system still relies on a three-stage SFT/RL training pipeline which can be complex to maintain. Future work in "Agentic Search" might seek to simplify this into a more continuous online learning loop.
Future Outlook: The concept of "Internalizing Reasoning" is a powerful paradigm shift. We should expect similar techniques to move into Computer Vision and Robotics, where real-time "intuition" is required for complex decision-making.