本文提出了 OneSearch-V2,一个应用于快手电商搜索的高性能生成式检索(Generative Retrieval)框架。该框架通过引入潜在推理增强和自蒸馏技术,实现了端到端直接生成商品 Semantic IDs (SIDs),在不增加推理延迟的前提下,显著提升了复杂长尾查询的理解能力和个性化匹配精度。
TL;DR
快手技术团队推出的 OneSearch-V2 彻底打破了工业级搜索中“深度推理必有高延迟”的魔咒。通过 关键词级 CoT (Chain-of-Thought) 构建逻辑模板,并利用独特的 自蒸馏技术 将这些逻辑“内化”到模型权重中,V2 版本在不增加任何线上推理开销的情况下,实现了 3.98% 的点击率增长,尤其在处理复杂长尾需求时表现惊人。
1. 背景:搜索系统的“极速”与“深思”之争
目前的生成式检索(Generative Retrieval, GR)已经成为搜索领域的前沿范式。它直接根据用户 Query 生成商品的 Semantic ID (SID)。然而,工业场景面临三重挑战:
- Query 复杂性:比如“室内健身器材”,模型需要推导出跑步机、哑铃等具体类目词。
- 推理延迟:LLM 虽强,但生成一段显式的推理过程(CoT)太慢。
- 奖励偏见:单纯拟合历史点击日志会让模型陷入“信息茧房”,忽略真正的新增意图。
2. 核心架构:三位一体的改进
OneSearch-V2 由三个核心模块构成,分别解决了“懂、记、调”的问题。
2.1 思想增强的 Query 理解 (Thought-Augmented Understanding)
不再强制模型生硬地匹配字符串,而是引入 Keyword-based CoT。
- 逻辑流:意图分析 细类目识别 显式属性提取 潜在主题推荐。
- 价值:将逻辑链压缩为极高信息密度的“关键词组”,这些关键词在训练阶段作为“上帝视角”输入,引导模型学习潜在路径。
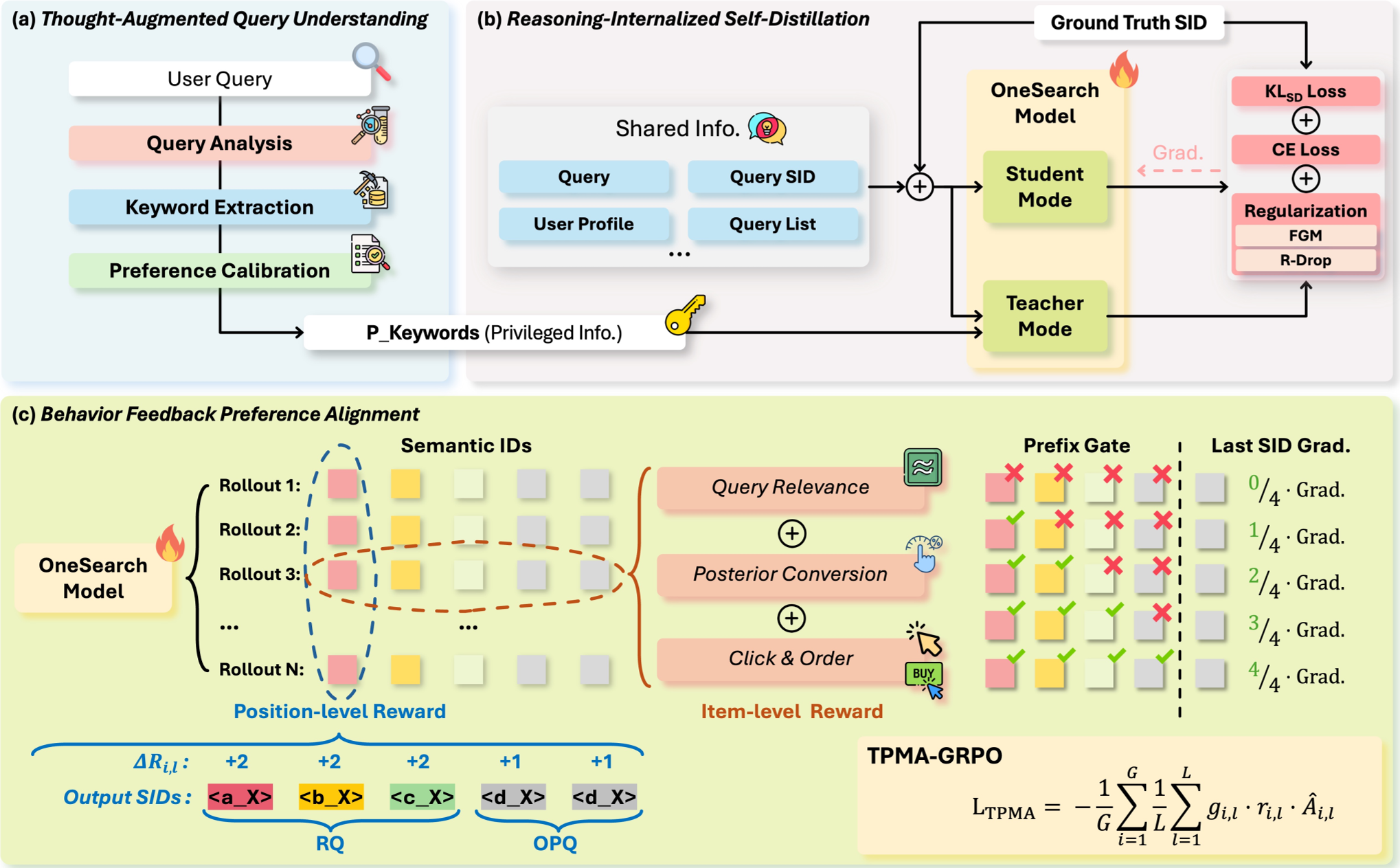 图 1:OneSearch-V2 总体架构,包含 Query 理解、自蒸馏训练与偏好对齐三部分。
图 1:OneSearch-V2 总体架构,包含 Query 理解、自蒸馏训练与偏好对齐三部分。
2.2 思维内化:自蒸馏的“无感推理”
这是 OneSearch-V2 最具洞察力的设计。为了让模型在没有关键词输入的线上环境也能“举一反三”,作者设计了 信息不对称自蒸馏:
- 教师路径:输入为 [Query + 关键词 CoT],输出 SID。
- 学生路径:输入仅为 [Query],输出 SID。
- 内化过程:通过 KL 散度约束,让学生强制模拟教师的分布。为了防止表现不稳定,作者还加入了 R-Drop (预测一致性) 和 FGM (对抗鲁棒性)。
2.3 偏好对齐:TPMA-GRPO 机制
针对 SID 的 由粗到精 (Coarse-to-fine) 结构,传统的 RL 算法对所有位置一视同仁是不科学的。
- TPMA (Token-Position Marginal Advantage):给前几个代表大类目的 Token 赋予更高的权重,并设计了“前缀门控”,如果前面的类目错了,后面的属性渐进梯度将被抑制。
3. 实验战绩:全线突破
在快手真实的电商直播间和货架搜索场景中,OneSearch-V2 对不同规模的模型(BART, GPT-2, Qwen-0.6B)均展现出强大的普适性。
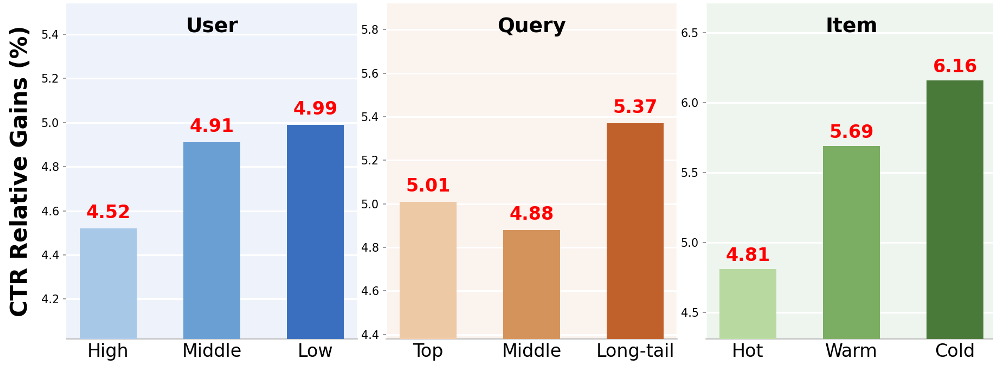 图 2:OneSearch-V2 在冷启动商品和长尾 Query 上的 CTR 提升显著高于热门品类。
图 2:OneSearch-V2 在冷启动商品和长尾 Query 上的 CTR 提升显著高于热门品类。
关键数据亮点:
- 全量提升:订单量增加 2.11%,GMV 增加 3.45%。
- 长尾拯救者:长尾 Query 的点击率提升幅度(+5.37%)远超头部(+5.01%)。
- 生态利好:冷启动(新发布)商品的点击率大幅提升 6.16%,缓解了电商系统长期存在的“马太效应”。
4. 深度洞察:为什么不直接做 Latent Token?
很多人会问,为什么不用 Coconut 等方法生成的“潜在向量”?OneSearch-V2 的消融实验给了答案:
- 监督粒度:自蒸馏提供了逐位置的概率分布对齐,而向量对齐(L1 Loss)往往只监督单一节点,损失了语义迁移的细腻度。
- 架构纯净度:自蒸馏无需更改模型结构,现有推理引擎直接兼容,这对大规模工业部署至关重要。
5. 局限与未来
尽管 OneSearch-V2 表现卓越,但在多模型融合(如视频、直播与商品的统一 ID 化)和实时干预策略上仍有优化空间。作者也提到,未来的方向是迈向 Agentic Search,即系统能根据用户反馈实时更新模型行为。
总结:OneSearch-V2 证明了推理能力可以被“压缩”进模型权重。对于追求极致性能又受限于 CPU/GPU 算力的搜索团队,这种“内化推理”的范式无疑是一剂良方。