本文推出了 OpenSpatial,一个旨在提升多模态大模型(MLLM)空间智能的开源数据引擎。该引擎采用 3D 框(3D Bounding Box)为核心表征,通过自动化 3D 提升(3D Lifting)技术构建了包含 300 万个样本的 OpenSpatial-3M 数据集,显著提升了模型在空间度量、关系推理及多视图一致性等任务上的 SOTA 表现。
TL;DR
尽管当前的 GPT-4 或 InternVL 等多模态模型在图像描述上已经炉火纯青,但一旦涉及“这两个椅子之间隔了多少米?”或“从另一个视角看,杯子在碗的哪一边?”这类 3D 空间问题时,往往会表现出严重的空间近视(Spatial Myopia)。本文介绍的 OpenSpatial 是一个开源的“数据引擎”,它通过将 2D 图像“提升”到 3D 空间,构建了 300 万量级的 OpenSpatial-3M 数据集。实验证明,该方法能让主流开源模型在空间推理任务上实现最高 19% 的相对性能提升。
1. 痛点:为什么 MLLM 是“空间文盲”?
目前大多数视觉语言模型(VLM)是在 2D 图像-文本对上训练的。它们学习的是像素间的统计相关性,而不是真实的物理世界几何结构。这种维度缺失导致了两个系统性障碍:
- 缺乏 3D 一致性:模型无法理解不同视角下同一个物体的对应关系。
- 黑盒生产管线:目前性能较好的空间数据集(如 SenseNova-SI)往往只发布静态数据,其生成引擎并不透明,研究者无法通过调整参数来探究“究竟是什么数据特征提升了空间智能”。
2. 核心直觉:以 3D Box 为锚点
OpenSpatial 的核心 Insight 在于:放弃简单的 2D 全局描述,转向以 3D 定向边界框(OBB)为核心的结构化表征。
通过 OBB,引擎为场景中的每个物体建立了一个全球坐标系下的“身份证明”。无论相机如何移动,物体的长宽高、物理位置和朝向都是恒定的。这种**视角不变性(Viewpoint-invariant)**是模型从“看图像”进化到“感知空间”的关键。
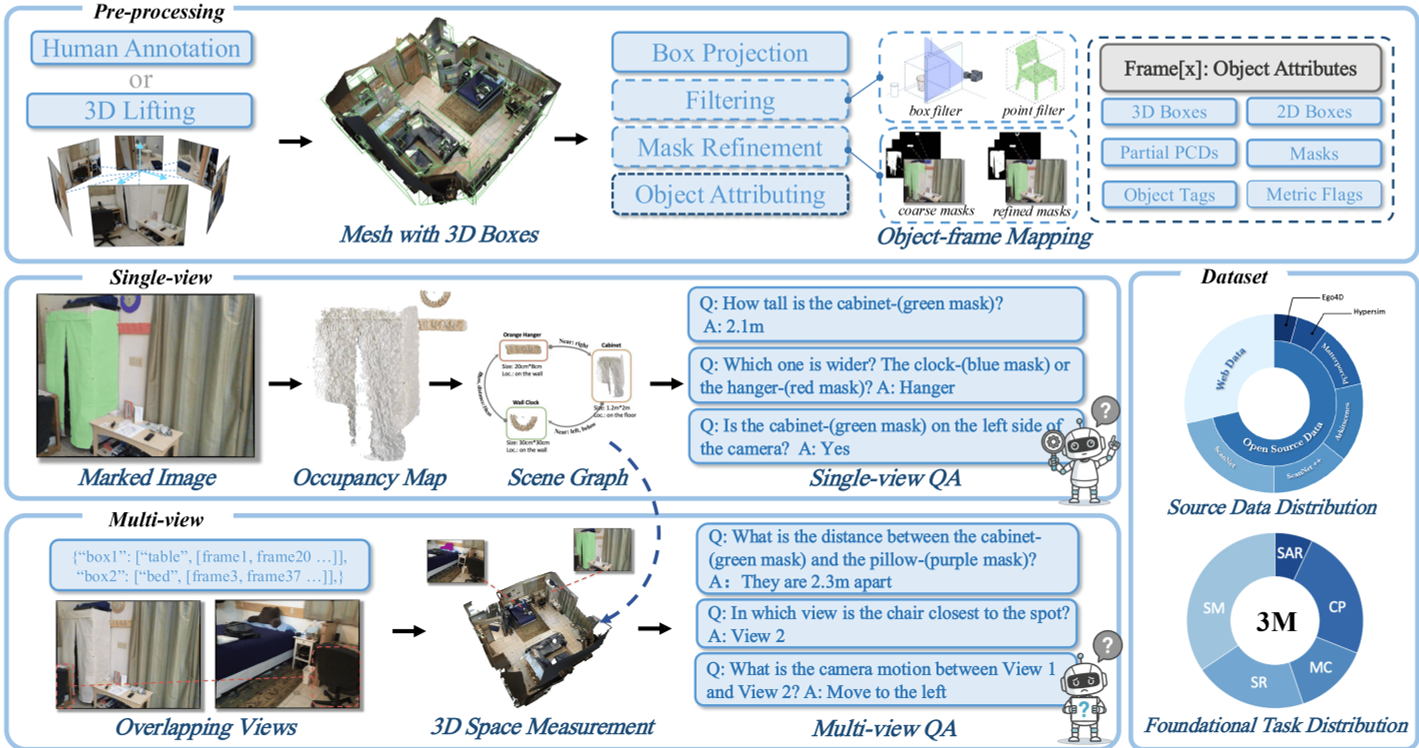 图 1:OpenSpatial 的数据处理流程:从 3D 框生成到属性提取,再到场景图驱动的 QA 合成
图 1:OpenSpatial 的数据处理流程:从 3D 框生成到属性提取,再到场景图驱动的 QA 合成
3. 方法论:OpenSpatial 是如何炼成的?
OpenSpatial 的工作流分为三个阶段:
- 3D Lifting(3D 提升):针对缺乏深度信息的互联网视频,引擎利用分割模型(SAM)和多视图几何,自动将 2D 目标提升为 3D 框,避免了昂贵的人工标注。
- 属性中心化映射:通过深度校验(Depth-based validation),剔除掉那些虽然在视野内但被完全遮挡的“假阳性”框,解决模型幻觉的基础数据问题。
- 五大任务层次:
- 空间度量 (SM):回答绝对尺寸和距离。
- 空间关系 (SR):判断物体间的拓扑位置。
- 相机感知 (CP):理解相机的位姿变化。
- 多视图一致性 (MC):跨视角重识别关键点或物体。
- 场景推理 (SAR):进行路径规划和高阶逻辑推理。
 图 2:OpenSpatialCover 的五个核心任务维度及其子任务示例
图 2:OpenSpatialCover 的五个核心任务维度及其子任务示例
4. 实验战绩:全线突破 SOTA
OpenSpatial 在多个极具挑战性的 Benchmark 上刷新了纪录。
| 模型基座 | 3D 平均分 | BLINK (空间感知) | MMSI (多图空间) | | :--- | :---: | :---: | :---: | | Qwen3-VL-8B (Baseline) | 56.7 | 66.1 | 28.1 | | OpenSpatial-Qwen3-8B | 62.1 (+5.4) | 68.2 | 41.9 (+13.8) |
深度分析 (Ablation Study): 实验显示,单纯堆叠数据量(Scaling)虽然有用,但任务多样性对空间智能的增益更为显著。如图 5 所示,引入“相机感知(CP)”任务能直接带动模型理解视角变化,而“空间度量(SM)”则赋予了模型类似卷尺的定量能力。
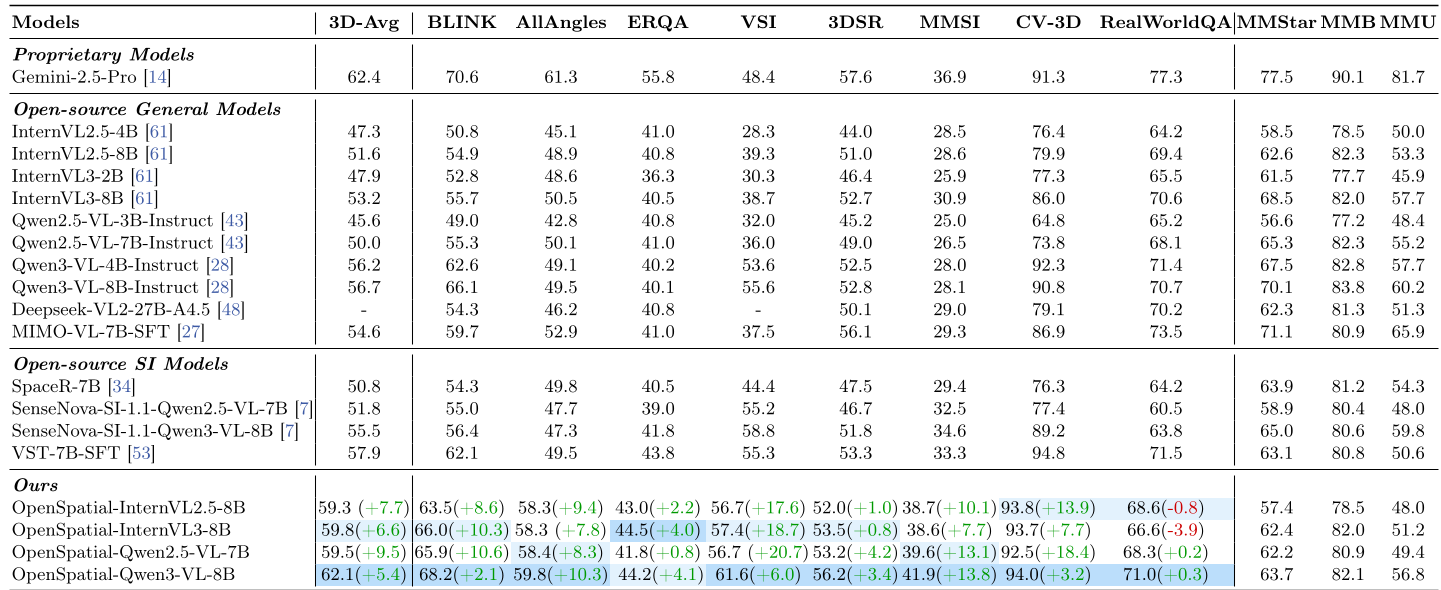 图 3:OpenSpatial 在各主流基准上的性能表现,蓝色括号内为相较于基线的提升
图 3:OpenSpatial 在各主流基准上的性能表现,蓝色括号内为相较于基线的提升
5. 局限性与展望
尽管在室内和受限场景下表现优异,OpenSpatial 在极端户外环境和复杂桌面微观场景下的提升仍有边际效应。作者指出,未来的方向是将此引擎扩展至更大规模的野外(Wild)视频数据,并与强化学习(RL)结合,让模型在模拟器中通过交互来完善其空间认知。
总结
OpenSpatial 的真正价值不在于那 300 万条数据,而在于它开源了一套可复现的、以几何原理为指导的生产管线。这为具身智能(Embodied AI)领域中的视觉感知从 2D 向 3D 跃迁提供了坚实的底层支撑。