Orion-Lite is a vision-only autonomous driving model that distills the reasoning capabilities of a 7B-parameter Vision-Language-Action (VLA) teacher into a compact 0.1B-parameter transformer decoder. It achieves a new SOTA Driving Score of 80.6 on the Bench2Drive benchmark, surpassing its teacher while being 3x faster in system-wide inference.
TL;DR
Orion-Lite proves that you don't need a massive 7B-parameter LLM behind the wheel to drive complex routes. By distilling the latent "reasoning" of a heavy VLA (Vision-Language-Action) teacher into a tiny 0.1B transformer, researchers achieved a 3x system speedup and a SOTA Driving Score of 80.6, actually outperforming the original teacher in complex closed-loop scenarios.
Problem & Motivation: The "LLM Bottleneck" in EB-AD
The current trend in End-to-End Autonomous Driving (E2E-AD) is to plug in a Large Language Model (LLM) to handle "causal reasoning." While models like ORION and DriveVLM show impressive results, they are computationally bloated for real-time vehicles.
- Memory: Running a 7B model requires ~31GB of GPU RAM, which is excessive for edge deployment.
- Latency: The "Chain-of-Thought" (CoT) approach is too slow for reactive maneuvers where every millisecond counts.
- The Extraction Paradox: Many VLA models end up using the LLM merely as a high-dimensional feature extractor. The authors asked: If the LLM is just a feature extractor, can we replace it with something 100x smaller?
Methodology: The Art of Latent Mimicry
The researchers introduced Orion-Lite, which replaces the Vicuna-1.5 (7B) LLM with a 6-layer Transformer Decoder (0.1B).
1. Feature Mimic Loss
Instead of predicting text tokens, the student model aims to replicate the latent planning tokens () generated by the teacher's LLM. They found that simple L1 Regression worked best because it preserves the spatial geometry of the planning space better than KL-Divergence, which requires distorting the features through a Softmax layer.
2. Joint Supervision
The model isn't just a copycat. It is trained using a dual-objective:
- Distillation: Follow the teacher's "thought" process (Latent Mimic).
- Ground Truth (GT): Follow the actual expert trajectories, supervised by collision, boundary, and regression losses.
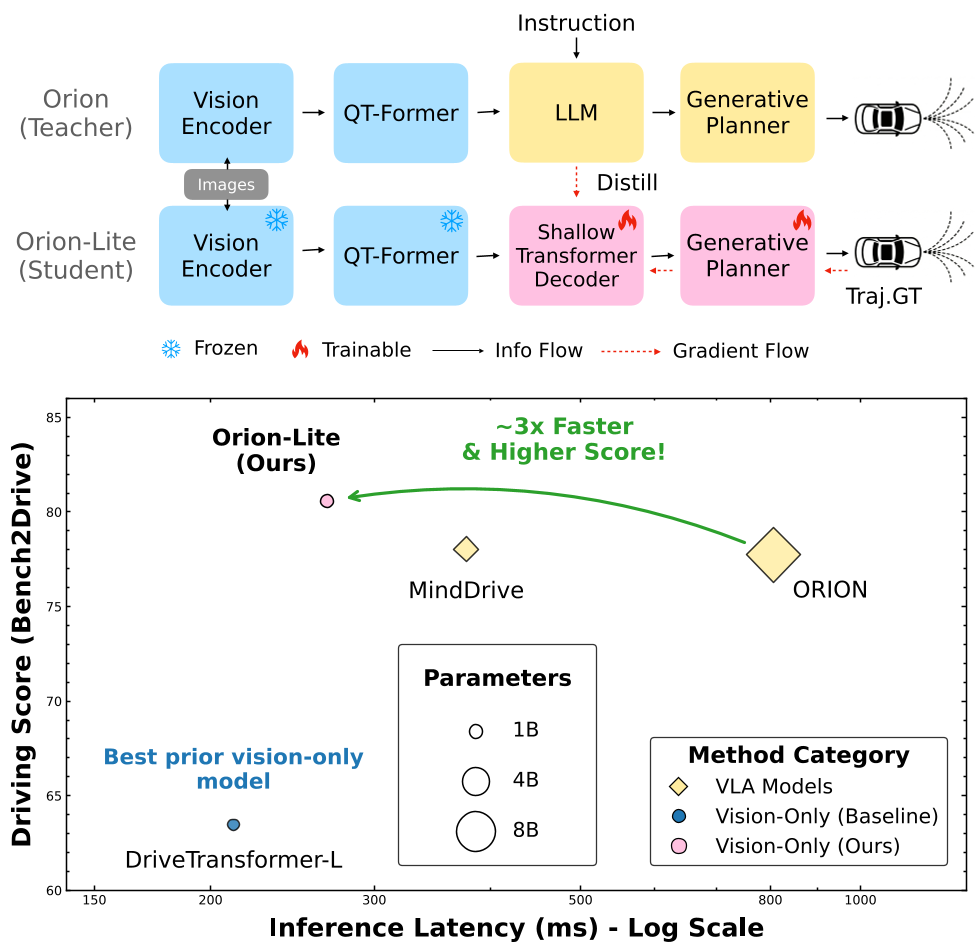 Figure 1: The framework uses the teacher's intermediate states to guide a lightweight student, resulting in higher efficiency and better scores.
Figure 1: The framework uses the teacher's intermediate states to guide a lightweight student, resulting in higher efficiency and better scores.
Experiments & Results: Surpassing the Teacher
The results on the Bench2Drive benchmark (comprising 44 interactive scenarios and 220 routes) were startling.
- Performance: Orion-Lite achieved a Driving Score (DS) of 80.6, beating the teacher ORION (77.7) and other heavyweights like MindDrive (78.0).
- Efficiency: The reasoning module itself saw a 150x speedup, and GPU memory usage plummeted from 31GB to 8GB.
- Robustness: Qualitative analysis shows that the student model is actually more decisive. While the teacher LLM often "hesitates" behind obstacles (leading to timeouts or collisions), the distilled student executes smoother overtaking and merging maneuvers.
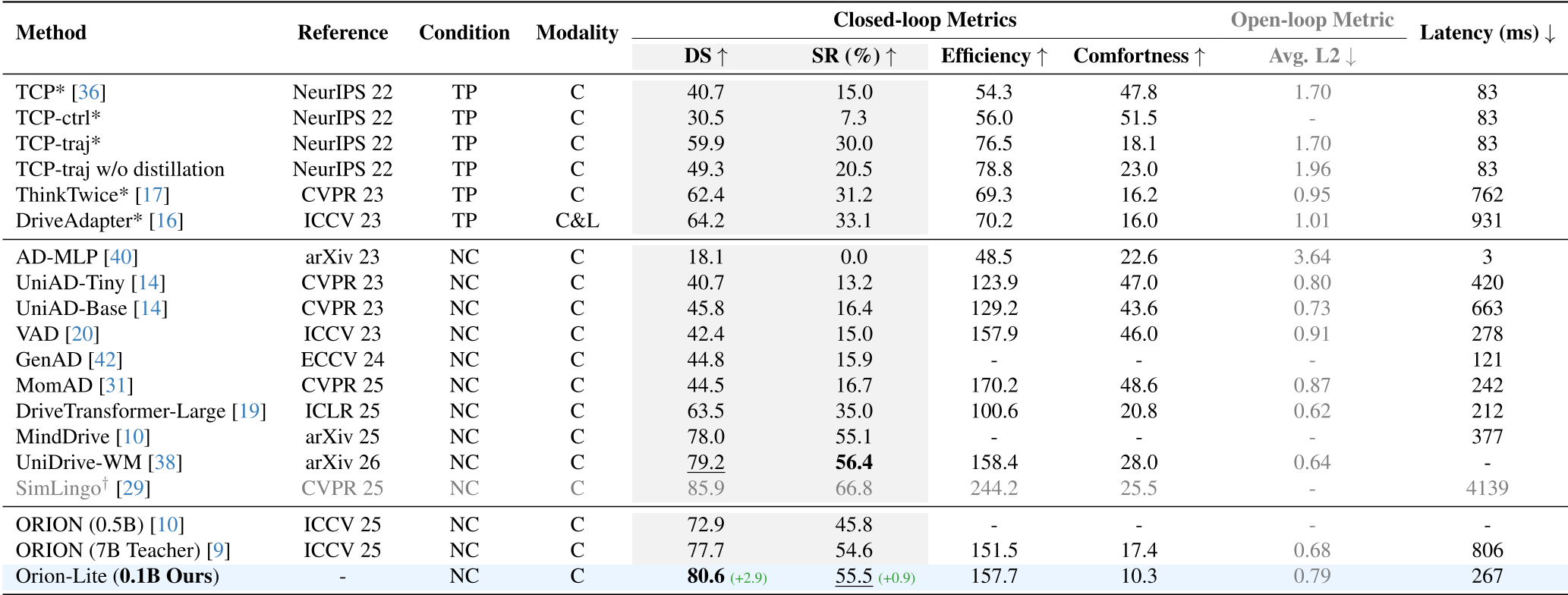 Table 1: Orion-Lite sets a new SOTA while significantly reducing latency (lower is better).
Table 1: Orion-Lite sets a new SOTA while significantly reducing latency (lower is better).
Why does the Student beat the Teacher?
The authors suggest that the LLM's latent embeddings act as "soft labels." This provides a regularizing effect that prevents the student from overfitting to "hard" ground-truth trajectories, allowing it to generalize better to unseen, interactive scenarios in a closed-loop environment.
 Figure 2: Visualizing successful maneuvers by the student model (bottom) compared to the teacher's failures (top) in interactive traffic.
Figure 2: Visualizing successful maneuvers by the student model (bottom) compared to the teacher's failures (top) in interactive traffic.
Critical Insight & Conclusion
This paper serves as a "reality check" for the VLA trend. It indicates that the causal reasoning captured by massive LLMs for driving is "dense" enough to be distilled into much smaller structures.
Future Work: The primary bottleneck is now the Vision Encoder (EVA-02-L). While the reasoning part is tiny, the "eyes" of the model remain heavy. The next frontier will likely involve distilling the vision backbone itself without losing the spatial-temporal awareness required for SOTA performance.
Takeaway: For reactive end-to-end planning, massive LLMs are excellent teachers, but they might be oversized for the actual task of driving.