本文提出了 Orion-Lite,一种高效的纯视觉端到端自动驾驶模型。通过将 7B 参数的 VLA (Vision-Language-Action) 老师模型 ORION 的潜层推理能力蒸馏到仅 0.1B 参数的轻量级 Transformer 解码器中,该方法在 Bench2Drive 闭环评测中取得了 80.6 的 Driving Score,刷新了 SOTA 纪录。
核心速览 (Executive Summary)
- TL;DR:Orion-Lite 通过一种极简的“特征模拟”蒸馏策略,将 70 亿参数大模型(LLM)驱动的自动驾驶能力,完美压缩到一个仅 1 亿参数的轻量级 Transformer 中。
- 背景定位:在自动驾驶领域,VLA(视觉-语言-动作)模型虽强,但臃肿。本文是典型的“以小博大”,证明了高效的视觉推理架构在复杂的闭环交互(Closed-loop)场景下,性能上限远未被触达。
痛点与动机 (Problem & Motivation)
当前的端到端自动驾驶(E2E-AD)正处在“规模化”的十字路口。集成 LLM 的模型(如 ORION, DriveVLM)能理解复杂的交通语义,但代价是:
- 推理延迟:LLM 自回归生成或处理海量 token 导致毫秒级的延迟,对时速 60km/h 以上的车辆是致命的。
- 资源瓶颈:31GB 以上的显存需求让车载嵌入式平台望而却步。
- 价值错位:在实际驾驶中,我们往往只需要 LLM 的“决策意图”特征,而不是它的文本输出能力。
作者的 Insight 非常明确:LLM 在 VLA 模型中本质上扮演了一个“过度参数化的特征提取器”。既然如此,我们是否可以只“借”它的意图,而不要它的身躯?
方法论详解 (Methodology)
1. 架构简化:从 LLM 到 Shallow Decoder
Orion-Lite 移除了所有文本 Prompt 和 7B 的词表层,代之以一个 6 层的标准 Transformer Decoder。
- 输入:由冻结的 Vision Encoder (EVA-02-L) 和时空模块 (QT-Former) 生成的状态嵌入。
- 输出:经过投影后,对齐到老师模型的
planning tokens维度。
2. 核心蒸馏策略
这里的核心并非复杂的数学创新,而是 Feature Mimic Loss (L1 Regression)。 通过让学生模型直接预测老师模型 LLM 层的输出状态,学生模型“继承”了老师对复杂场景(如超车、汇入)的因果推理直觉。
3. 系统架构图
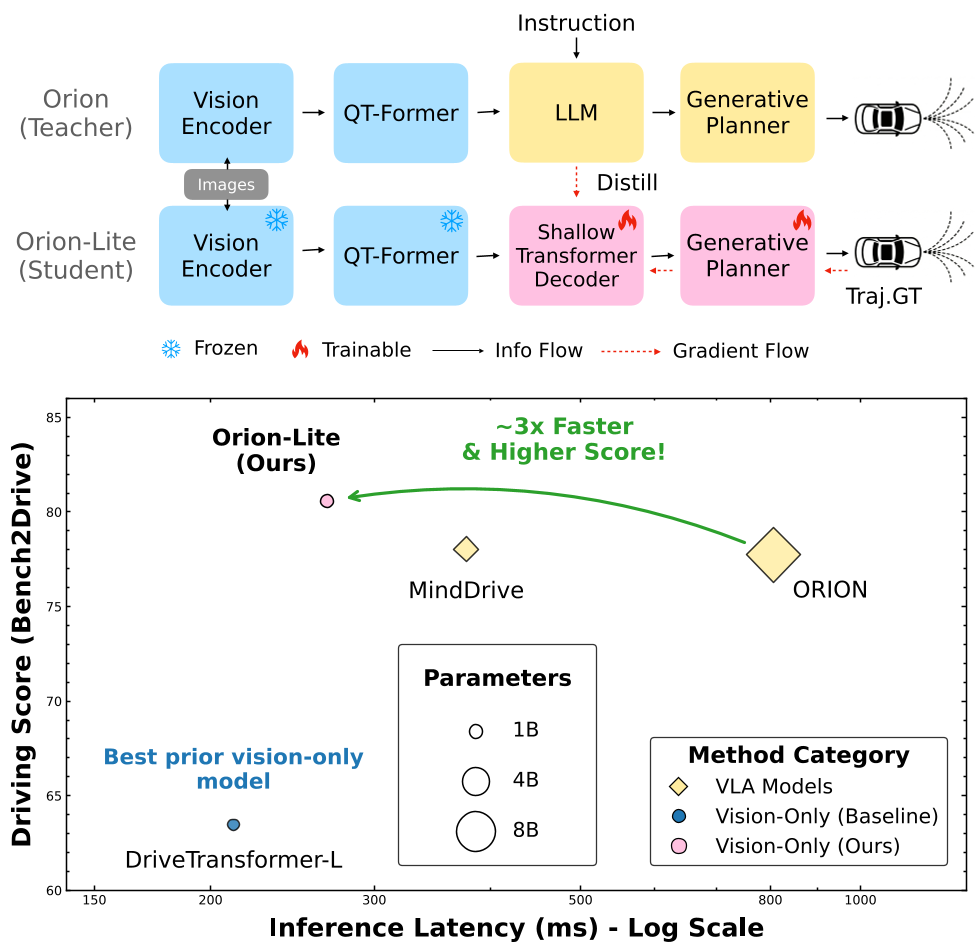 图 1: Orion-Lite 蒸馏框架:通过联合蒸馏与轨迹监督,实现对老师模型的超越。
图 1: Orion-Lite 蒸馏框架:通过联合蒸馏与轨迹监督,实现对老师模型的超越。
实验与结果 (Experiments & Results)
SOTA 战绩对比
在公认的高难度基准 Bench2Drive 上,Orion-Lite 展现了惊人的战斗力:
- Driving Score (DS): 80.6(老师模型为 77.7)。
- 推理延迟: 相比老师模型降低了 3 倍(推理模块自身提速 150x)。
- 显存需求: 从 31GB 直接切到 8GB。
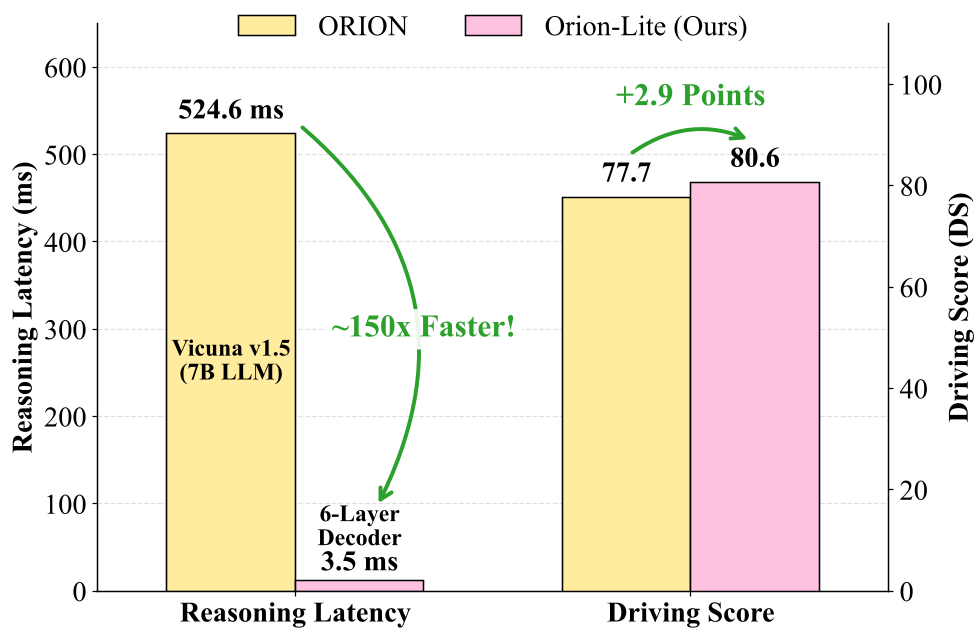 图 2: 延迟与性能的帕累托前沿提升(推理时间显著下降,DS 指数却向上攀升)。
图 2: 延迟与性能的帕累托前沿提升(推理时间显著下降,DS 指数却向上攀升)。
为什么学生能超越老师?
消融实验(Ablation Study)给出了启发性的结论:
- 正则化效应:LLM 的潜在特征充当了“软标签”,减少了对训练集硬轨迹的过拟合(见下表数据)。
- 空间意识:定性分析显示,老师模型(ORION)在障碍物后方汇入时常有犹豫,而 Orion-Lite 的空间感知更果断。
 图 3: 在超车与规避障碍物场景中,Orion-Lite (下排) 表现出比老师 (上排) 更平滑、更确定的规划路径。
图 3: 在超车与规避障碍物场景中,Orion-Lite (下排) 表现出比老师 (上排) 更平滑、更确定的规划路径。
深度洞察与总结 (Critical Analysis & Conclusion)
Takeaway: Orion-Lite 的成功预示着自动驾驶的一个新阶段——推理特征化。我们不再需要在推断时运行整个 LLM,只需要在训练阶段利用其“世界知识”来塑造轻量级模型的特征空间。
局限性 (Limitations):
- Vision Encoder 依然沉重:虽然推理层变快了,但 EVA-02-L 仍是计算重心,未来需要对视觉骨干网络进行类似蒸馏。
- 基准单一:目前仅在 Bench2Drive (CARLA 模拟) 验证,在真实物理世界的泛化能力有待观察。
寄语: 如果你正在苦恼如何将千亿参数的驾驶大模型塞进车载芯片,Orion-Lite 提供了一个明确的样板:不要蒸馏它的文字,要蒸馏它的灵魂(Latent Features)。