本文提出了 OS-Themis,一个专为通用 GUI 智能体设计的可扩展多智能体批判(Critic)框架。通过将长轨迹分解为可验证的里程碑(Milestones)并引入严格的审计机制,该方法在 AndroidWorld 等多个平台上达到了 SOTA 性能,显著提升了强化学习(RL)训练的奖励质量。
TL;DR
在数字世界中导航的 GUI 智能体(GUI Agents)正面临从“模仿学习”向“强化学习(RL)”跨越的关键期。然而,RL 的成功极度依赖精准的奖励函数。本文提出的 OS-Themis 框架,通过多智能体协作完成了从“单次判断”到“结构化审计”的范式转移,在 AndroidWorld 上实现了 10.3% 的显著性能提升,为智能体的自我进化提供了高效、稳健的“数字裁判”。
背景定位:奖励函数的“虚假繁荣”
当前的 GUI 智能体在处理复杂的跨 App 任务(如:在特定软件中编辑文档并保存)时,经常会出现“看似在做,实则失败”的情况。传统的 LLM-as-a-judge 往往盯着最后几个截图看(Last-K),容易丢失上下文;或者全局扫视,导致关键的失败细节(如未点击保存、大小写错误)被淹没在冗长的正确操作中。这种**证据稀释(Evidence Dilution)**现象产生的错误正向奖励,会直接误导 RL 的训练方向。
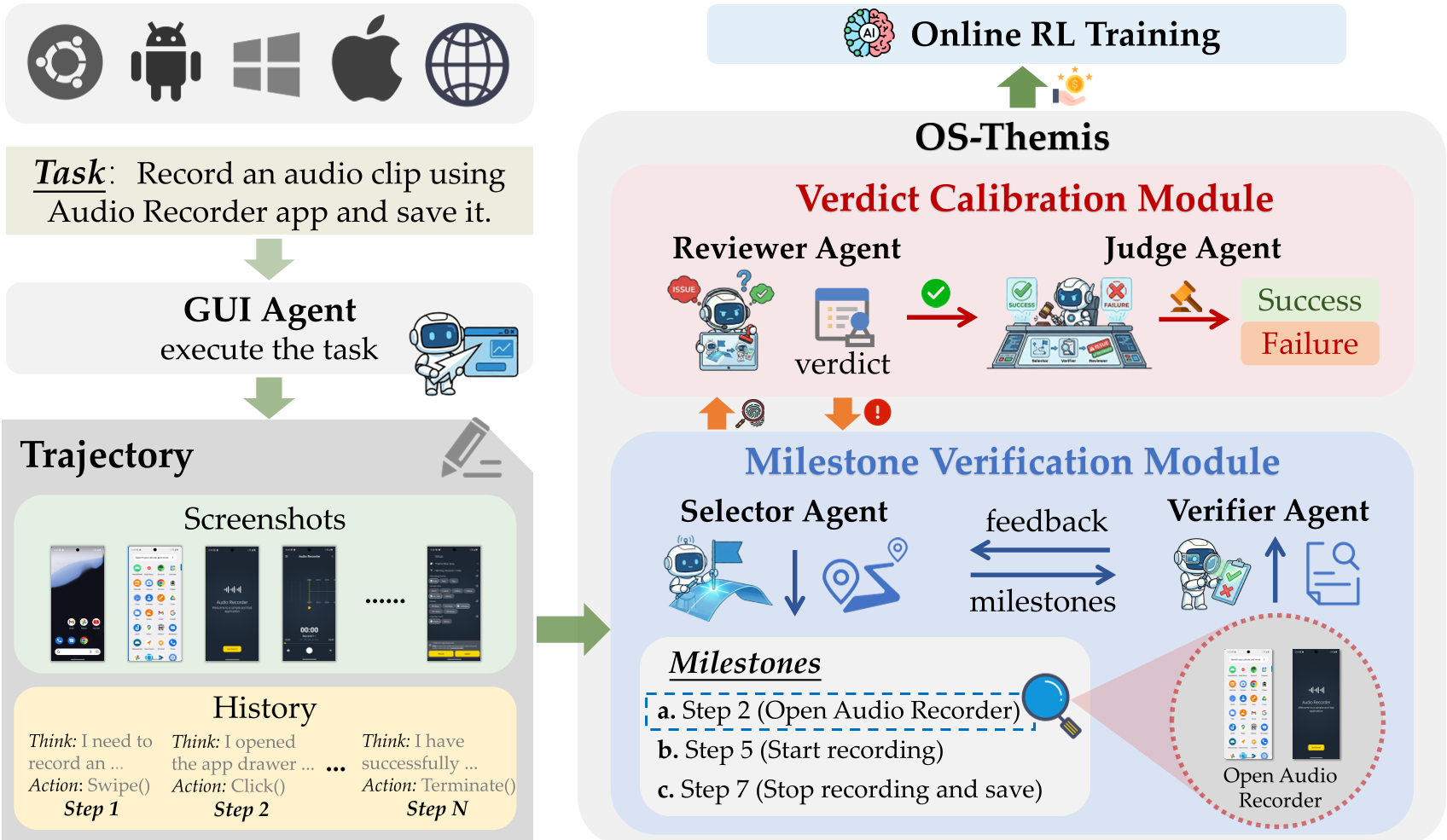
核心方法论:从单官司到“合议庭”
OS-Themis 不再信任单个模型的直觉,而是构建了一个严密的四人协作系统:
-
里程碑验证模块 (MVM):
- Selector Agent:将漫长的互动轨迹切分为关键的“里程碑”(例如:打开 App -> 找到文件 -> 定位光标 -> 插入文本)。
- Verifier Agent:针对每个里程碑,对比执行前后的截图,给出二进制的验证结果。这种局部细粒度的检查极大地降低了噪声。
-
判词校准模块 (VCM):
- Reviewer Agent(全场最严审计):专门负责“找茬”,检查里程碑是否完备。如果发现“没有检查保存状态”或“大小写不匹配”等隐患,会打回 MVM 要求补充证据。
- Judge Agent:综合所有审核过程、里程碑证据和原始任务目标,给出最终的奖励分 。
这种**证据驱动(Evidence-Grounded)**的设计,确保了高精度(High Precision),这对于策略梯度算法(Policy Gradient)至关重要——宁可漏掉正确的,也绝不奖励错误的。
实验结果:全平台的碾压优势
为了证明通用性,作者推出了 OmniGUIRewardBench (OGRBench),涵盖了移动端、网页、桌面端(Ubuntu, Windows, macOS)。
- 准确率突破:OS-Themis 在所有基准模型(Qwen3, GPT, Gemini)下均表现最优,平均准确率比 DigiRL 高出约 18.8%。
- 强化学习增益:在 AndroidWorld 在线 RL 训练中,OS-Themis 带来的增益达到了 7.1% 到 10.3%。
- 自我进化潜力:利用 OS-Themis 过滤出的高质量轨迹进行微调(SFT),模型性能提升了 6.9%,证明了其作为“自动化数据标注员”的卓越能力。

深度洞察:为什么这种多智能体方案有效?
在消融实验中,作者发现了一个有趣的结论:
- 如果不加 Selector(即检查每一步操作),Acc 会下降 4.7%,原因是引入了太多无关的“琐碎动作”,反而加剧了证据稀释。
- 如果不加 Reviewer,精度会大幅下降,因为 Judge 往往会表现得过于乐观。
这表明,模拟人类法律决策中的“详细取证”和“严格质证”过程,确实能有效解决复杂感知任务中的逻辑漏洞。
总结与未来启示
OS-Themis 不仅是一个奖励模型,它为自主进化智能体提供了一个基础设施。它告诉我们:单纯堆叠模型规模(Scaling up)不足以解决 GUI 任务的脆弱性,过程性的、可解释的验证框架才是通往可靠 Agent 的必经之路。
局限性:目前多轮迭代过程增加了推理延迟(约 117s/轨迹)。未来,如何通过模型蒸馏将这种“合议庭”的能力压缩到单个轻量化模型中,将是实现实时 GUI 闭环 RL 的下一个战场。
Takeaway for Practitioners: 如果你正在开发 GUI Agent,不要只看最终状态。建立基于里程碑(Milestone)的反馈机制,并优先保证奖励的“高精度(Precision)”,你的 RL 才有收敛的可能。