本文提出了 PanoVGGT,这是一个基于 Transformer 的前馈式全景 3D 重建框架,能够从单张或多张无序全景图中直接联合预测相机位姿、深度图和全局一致的 3D 点云,在 PanoCity 等数据集上实现了 SOTA 性能。
TL;DR
PanoVGGT 是一种革命性的前馈式 3D 重建架构,专门为全景影像设计。它抛弃了传统的“切割-拼接”针孔视图流程,通过引入球面感知的 Transformer 机制,能够在单次前向传播中从多张无序全景图中输出精确的相机轨迹、高精度深度图及无缝 3D 点云。配合本文发布的 PanoCity 大规模数据集,该方法在位姿估计和端到端重建质量上大幅领先基线模型。
痛点深挖:为什么全景重建很难?
全景图像(Equirectangular Projection)虽然提供了 360° 的超大视野,但也带来了两大痛点:
- 严重的非线性畸变:针孔相机模型在两极地区会失效,标准的 ViT 位置编码无法处理全景图中“越往两极采样越密”的几何特性。
- 数据极度匮乏:现有的全景数据集(如 Matterport3D)大多是离散的采样点,缺乏足够的视角重叠来训练端到端的几何推理模型。此前效果最好的模型(如 DUSt3R, VGGT)在全景图上往往会出现断层或结构扭曲。
核心动机与直觉 (Motivation & Insight)
作者认为,全景图像在几何理解上具有天然优势(视野连续、无盲区),只要能解决“位置编码与球面几何匹配”以及“旋转鲁棒性”问题,Transformer 强大的 cross-view correspondence 能力就能被释放。
方法论详解 (Methodology)
1. 球面感知位置嵌入 (Spherical-aware PE)
作者弃用了传统的 2D 坐标网格,而是将全景图的像素中心转换为四维向量 。这种设计的妙处在于它保持了经度上的循环连续性(Wrap-around Continuity),确保了全景图左右边缘在几何特征上的无缝对接。
2. 三轴 SO(3) 旋转增强
这是本文的“杀手锏”。不同于普通图像的裁剪旋转,全景图可以在整个球面上进行物理意义正确的旋转。通过这种三轴增强,模型学会了从不同倾斜角度、旋转角度观察同一场景,从而强迫网络解耦“投影畸变”与“语义内容”。
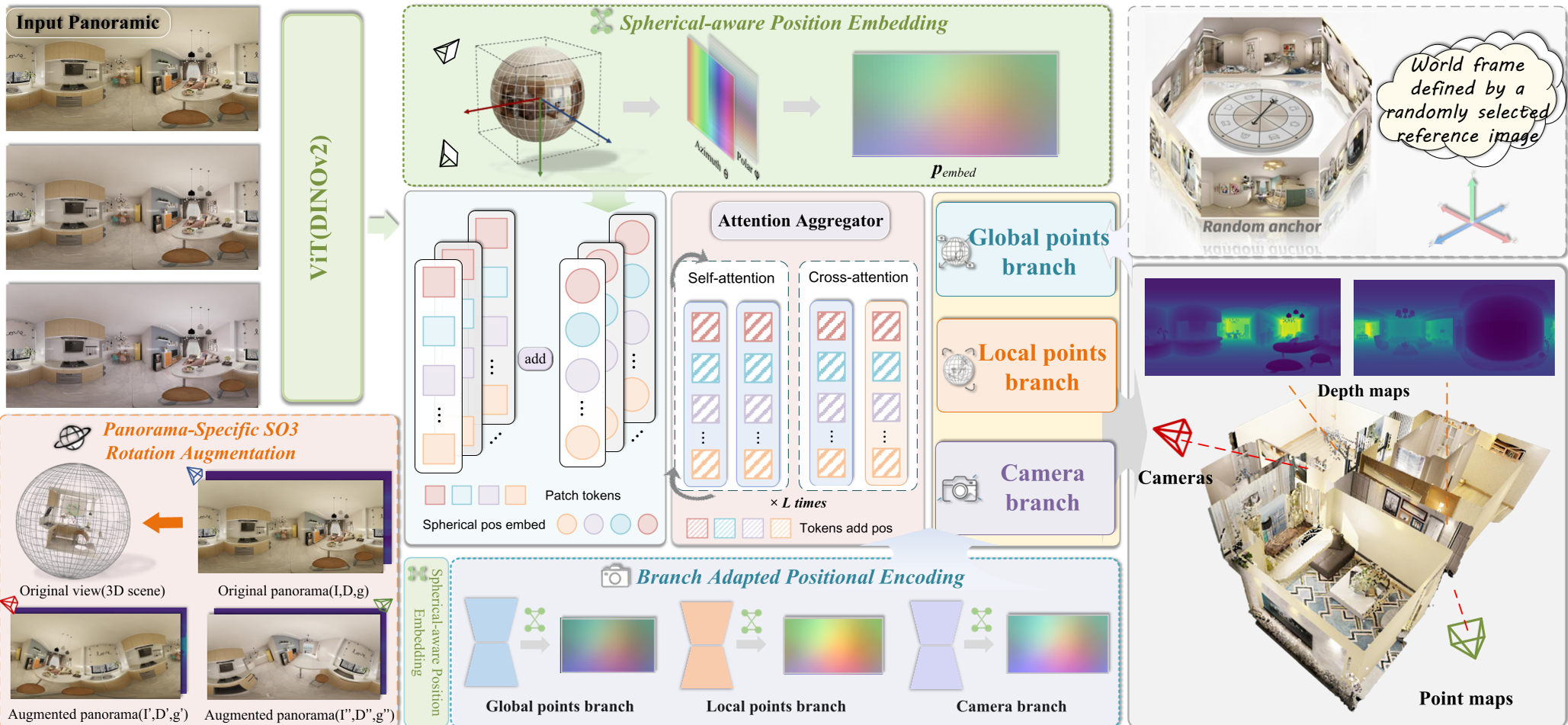 Figure: PanoVGGT 架构。采用含有 DINOv2 后干的 Alternating-Attention 块,并引入分支适配的球面 PE。
Figure: PanoVGGT 架构。采用含有 DINOv2 后干的 Alternating-Attention 块,并引入分支适配的球面 PE。
3. 加入随机锚点的几何聚合
为了消除全局坐标系的歧义(哪个相机是原点?),作者引入了 Stochastic Anchoring:训练时随机选一个全景图作为坐标系锚点。这种策略不仅消除了输入顺序的偏差,还增强了模型在处理无序图片集时的稳定性。
实验与结果 (Experiments & Results)
在作者新提出的 PanoCity 数据集(包含 12 万张具有真实深度和 6-DoF 位姿的高质全景图)上,PanoVGGT 展现了代差级的优势。
- 位姿估计:在 Matterport3D 上,相比 π3,PanoVGGT 的位姿准确率 (AUC@30) 提升了近 50%。
- 重建质量:如图 3 所示,即使是 SOTA 的针孔模型π3在面对全景输入时也会产生破碎的几何体,而 PanoVGGT 能够生成结构清晰、极具一致性的室内外建模。
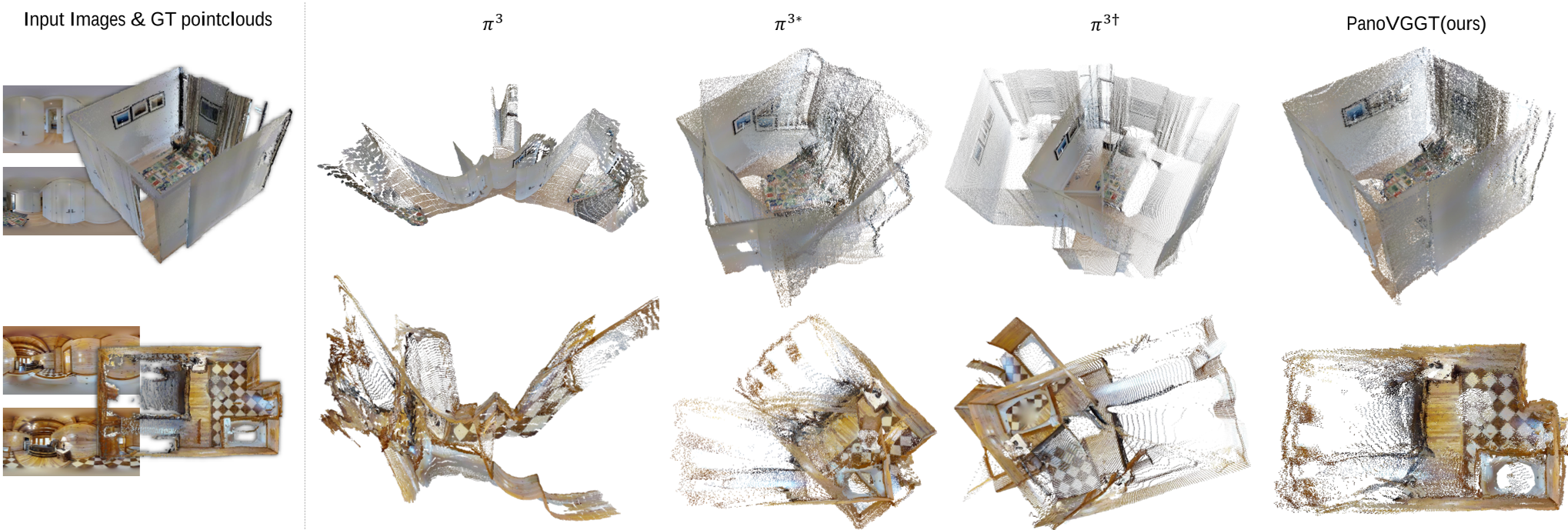 Figure: 在 Matterport3D 数据集上的点云重建对比,PanoVGGT 的结构完整性和锐度明显更高。
Figure: 在 Matterport3D 数据集上的点云重建对比,PanoVGGT 的结构完整性和锐度明显更高。
深度洞察与总结 (Critical Analysis)
总结 (Takeaway): PanoVGGT 的成功不仅在于架构的微调,更在于它通过 SO(3) 旋转增强和球面 PE,成功地让 Transformer 理解了非欧式投影下的几何不变性。这为机器人导航、智能城市建模以及全景 VR 设备的实时 SLAM 提供了一条简洁且高效的路径。
局限性 (Limitations): 目前模型仍主要针对等距柱状投影(Equirectangular)进行优化。如果输入是多源、非标准的鱼眼镜头或其他全景格式,模型性能可能会有抖动,且超长序列的内存消耗仍有待通过稀疏注意力等机制进一步优化。
未来展望: 随着 PanoCity 数据集的开源,研究社区可能会涌现更多专门针对大尺度室外环境的 3D 全景大模型。将该框架与 3D Gaussian Splatting 结合实现实时的高精度全景渲染,将是一个极具吸引力的方向。