本文由 Apple 和 Google 的研究团队提出 PathMoE,一种路径约束的混合专家(MoE)架构。该方法通过在连续层块(Blocks)内共享路由(Router)参数,将原本指数级增长的专家路径空间(Expert Path Space)进行压缩,显著提升了模型在大规模语言建模和下游任务中的性能。
TL;DR
传统的 Mixture-of-Experts (MoE) 架构在每一层都“各行其政”,独立选择专家,导致模型在海量的可能路径(Path Space)中迷失。Apple 与 Google 的研究者通过 PathMoE 改变了这一现状:通过在连续层块内共享路由器参数,显著压缩了路径空间。结果显示,这种简单的归纳偏置不仅提升了模型精度(16B 模型在 10/12 任务中获胜),还消除了对辅助负载均衡损失的依赖,让模型更鲁棒、更具解释性。
1. 痛点:被忽视的指数级路径空间
MoE 之所以强大,是因为它能解耦模型容量与计算成本。由于每个 Token 只激活部分参数(Top-k),我们可以训练万亿级规模的模型。
然而,主流 MoE(如 Mixtral, DeepSeek-MoE)存在一个结构性隐患:路由独立性。
- 假设有 层,每层 个专家,可能的专家路径总数为 。
- 对于一个 24 层、每层 16 个专家的模型,路径数高达 ,远超任何训练集的 Token 总数。
这种“组合爆炸”导致了严重的统计低效。每个 Token 在每层都重新做决定,导致专家难以形成跨层的协同效应。
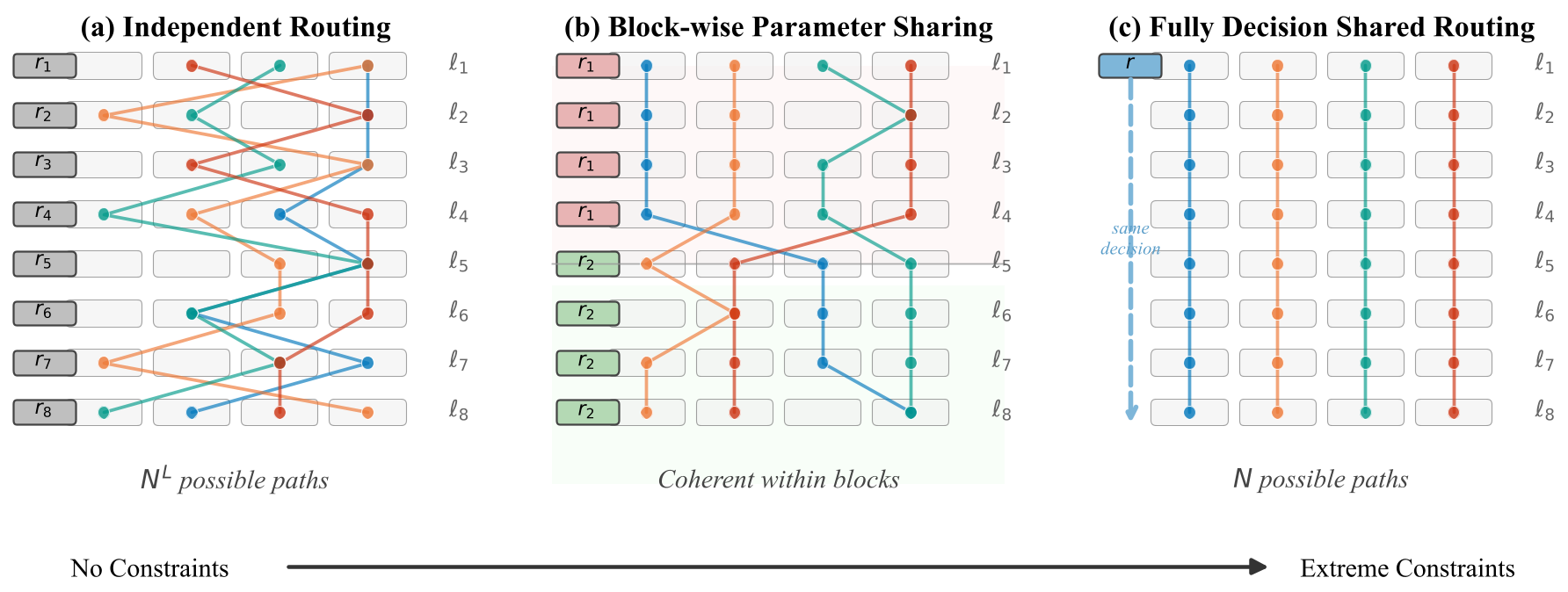 图 1:(a) 独立路由 (b) PathMoE 分块共享 (c) 完全决策共享
图 1:(a) 独立路由 (b) PathMoE 分块共享 (c) 完全决策共享
2. PathMoE:参数共享的妙用
作者并没有走向另一个极端(即强制所有层选同一个专家),而是提出了 PathMoE。
2.1 核心机制
PathMoE 将网络分为多个块(Block),每个块内的所有层共享同一个路由器参数 。
- 为什么有效? 因为 Transformer 的残差连接(Residual Connections)保证了相邻层的输入表征 和 是非常接近的。
- 物理直觉:由于 且共享 ,路由器在块内会自然产生高度相关的概率分布。这不仅鼓励了路由一致性,还允许模型随着网络深度(跨 Block)根据表征的变化动态调整路径。
2.2 无需辅助损失(Load Balancing Loss)
传统 MoE 必须使用复杂的辅助损失来防止所有 Token 涌向同一个专家。PathMoE 由于在路径层级引入了约束,实验发现即使不加辅助损失,模型也能自发地实现负载均衡,且训练更加平稳。
3. 实验结果:全方位的跨越
在 0.9B 和 16B 两种规模下,PathMoE 展现了统治级的表现。
3.1 性能对比
在 Fineweb 和 DCLM-Pro 数据集的测试中,PathB4-MoE(Block Size = 4)在各项常识推理和知识任务中均优于标准 MoE。
 表 1:16B 模型下 PathMoE 在绝大多数任务上显著优于独立路由基线
表 1:16B 模型下 PathMoE 在绝大多数任务上显著优于独立路由基线
3.2 鲁棒性与专业化
这一部分是最令人惊喜的发现。PathMoE 强制减少了路径熵(Routing Entropy),使 Token 集中在更少数的高效路径上。
- 鲁棒性提升 22.5 倍:当随机扰动路由决定时,PathMoE 的性能下降极其缓慢,而传统 MoE 会迅速崩溃。
- 路径即语义:通过词云分析发现,PathMoE 的每条路径都自发演化出了清晰的语言学功能——有的路径专门处理“标点”,有的处理“人名”,有的处理“动词”。
 图 2:不同专家路径自发形成的语言学聚类(词云)
图 2:不同专家路径自发形成的语言学聚类(词云)
4. 深度洞察:为什么这种约束反而更好?
在深度学习中,我们通常认为参数冗余和灵活性是好事。但 PathMoE 告诉我们,适当的结构化约束是更强的归纳偏置。
- 信号增强:当路径被压缩后,原本分散在 条路径上的训练信号现在集中在少数核心路径上。每个专家路径接收到的有效训练样本变多了。
- 跨层协同:专家不再是孤立的孤岛,而是成为了连贯“流水线”上的一部分。第 层的专家可以确信它接收到的输入具有特定的统计特性,因为它在路径上与其前后的专家是协同工作的。
5. 局限性与展望
PathMoE 在 Token-choice 路由(即 Token 选专家)上表现极佳,但在 Expert-choice 路由上提升不明显。此外,Block Size 的最优值(目前看是 4)可能随任务领域而异。
总结 (Takeaway): PathMoE 的成功挑战了“路由越灵活越好”的直觉。通过这种“参数共享”的巧妙路径约束,我们不仅得到了更强的模型,还向理解 MoE 内部运作逻辑迈出了一大步。对于正在构建大规模 MoE 模型的团队来说,这几乎是一个“免费中餐”(既提效又省参数)。
本文由资深学术技术主编重构。