PathPainter is a novel navigation framework that reformulates Bird's-Eye-View (BEV) path planning as an image-to-image generation task by leveraging foundation models like Gemini. It integrates zero-shot destination grounding and traversability mask generation with a cross-view localization system, achieving a 71.4% success rate in 160-meter long-range outdoor UAV navigation.
TL;DR
PathPainter is a hierarchical navigation system that treats path planning as an "image painting" problem. By prompting foundation models (like Gemini) to generate traversability masks and target markers on aerial images, it enables robots to navigate complex, unstructured outdoor environments using natural language instructions.
Background Positioning: This work sits at the intersection of Generative AI and Embodied AI. It moves beyond using Large Language Models (LLMs) just for high-level logic, instead utilizing the latent spatial reasoning of Image Generation Models to solve low-level geometry and connectivity problems in navigation.
The Problem: Why Traditional Maps Fail
Current robotic navigation usually depends on two things: semantic segmentation (identifying "road" vs "grass") and SLAM. However, this approach has two fatal flaws in the real world:
- Semantic Rigidity: A robot might be able to drive on a sidewalk or a dirt path, but a standard "road" segmenter will ignore these, leading to planning failures in open spaces like parks.
- Connectivity Rupture: Trees often occlude narrow paths in aerial shots. Standard segmentation models (like SAM 3.1) often see these as disconnected fragments, making A* search impossible.
Methodology: Planning as Generation
The core philosophy of PathPainter is that Image Generators are Generalist Vision Learners. They don't just see pixels; they understand the "logic" of a scene.
1. The Generative Pipeline
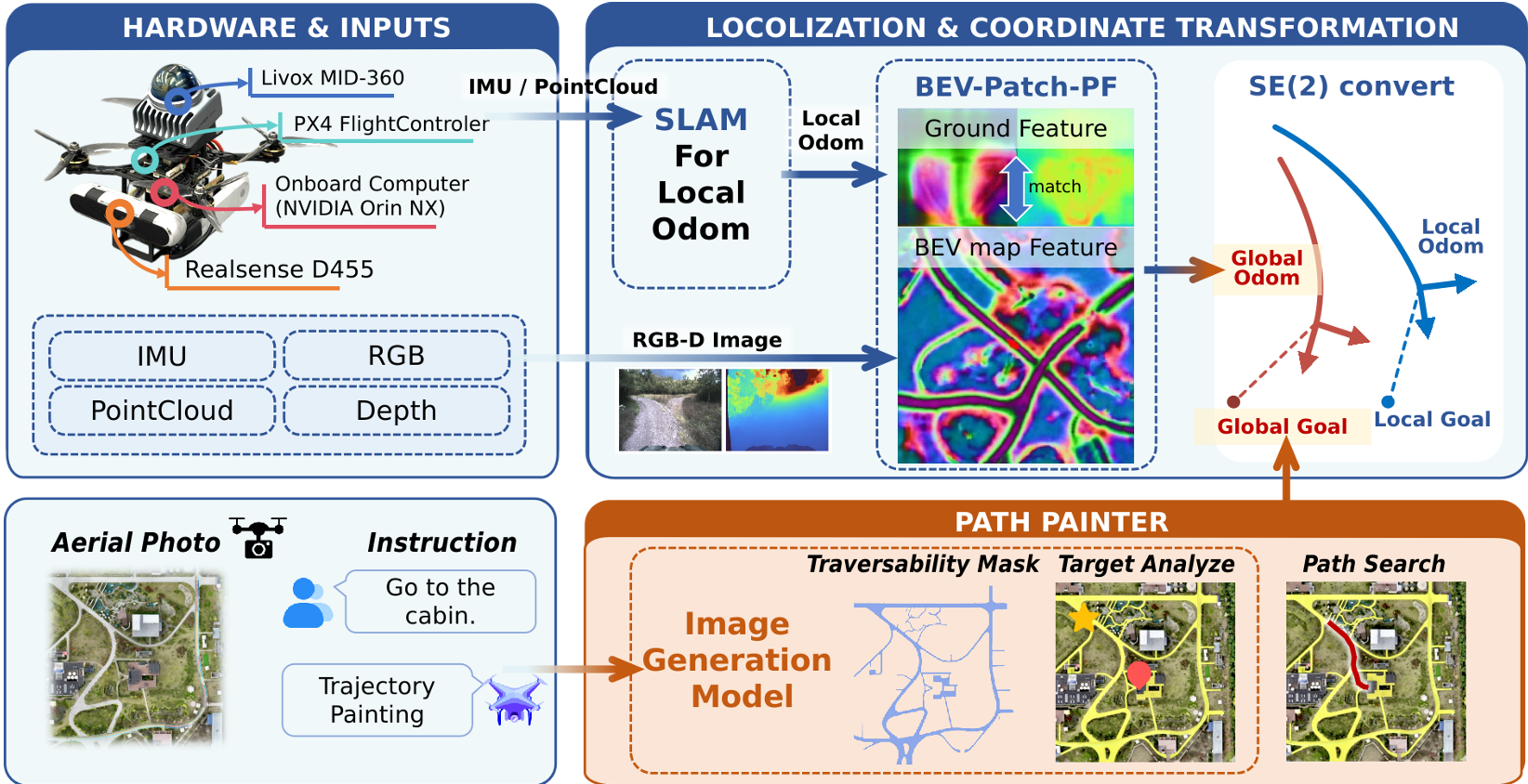
PathPainter follows a "Prompt-to-Mask" workflow:
- Destination Inference: The model receives a BEV map and a natural language command (e.g., "Go to the industrial campus gate"). It marks the target with a star.
- Traversability Painting: Instead of binary classification, it "paints" a mask of everywhere the robot could go. Because the model understands global context, it can "fill in" paths hidden under foliage, maintaining topological continuity.
- Search-based Refinement: A* search is performed on the generated mask. To ensure safety, a penalty is applied to points near the boundaries, forcing the path to the center of traversable regions.

2. Physical Execution & Localization
Planning a path on a map is useless if the robot doesn't know where it is on that map. PathPainter uses Cross-view Localization. It reconstructs local ground features from the robot's onboard RGB-D/LiDAR and matches them against the BEV map embedding. This corrects the drift of high-rate LiDAR odometry (FAST-LIO2), allowing for 160-meter long-range missions without RTK-GPS.
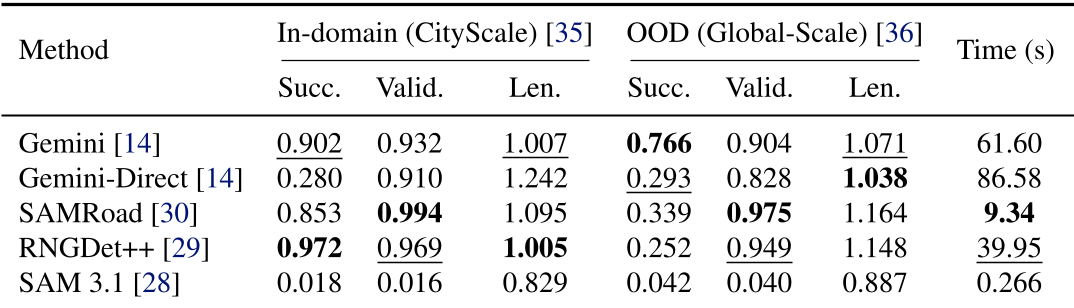
Experiments: Superior OOD Generalization
The researchers benchmarked PathPainter against SOTA "road-extraction" models like SAMRoad and RNGDet++.
- In-Domain: In familiar city street datasets, specialized models perform well.
- Out-of-Domain (OOD): In cluttered or unconventional environments, specialized models' success rates plummeted (often below 30%). PathPainter (using Gemini) maintained a much higher success rate because it didn't just "detect" roads—it "inferred" walkable spaces.
In real-world tests using a UAV (acting as a near-ground proxy), the system completed missions across parks and industrial campuses, handling large initial pose errors and significant GPS fluctuations.
Critical Insight & Conclusion
The "magic" of PathPainter lies in its use of Generative Priors. While a traditional segmenter asks "Is this pixel a road?", a generative model asks "How does a path naturally flow through this scene?". This shift from local classification to global reasoning is what enables the robot to handle "unseen" environments.
Limitations:
- Compute: Onboard inference for foundation models is still heavy, limiting localization updates to 1Hz.
- 2D Constraints: 2D BEV maps lack elevation data, which could be problematic in multi-level structures (like parking garages).
Future Outlook: As on-device AI accelerators improve, we likely see more robots ditching pre-defined semantic maps in favor of "hallucinating" their own traversability priors in real-time.