This paper introduces PEARL, a training-free framework for Open-Vocabulary Semantic Segmentation (OVSS). It achieves SOTA performance (Avg. 43.2 mIoU) using only a frozen CLIP backbone through a two-step "align-then-propagate" inference strategy.
TL;DR
PEARL is a plug-and-play, training-free framework that elevates standard CLIP models to state-of-the-art performance in open-vocabulary semantic segmentation. By introducing a closed-form Procrustes Alignment inside the attention layer and a Text-aware Laplacian Propagation during inference, it achieves superior mask coherence without the need for auxiliary backbones like DINO or time-consuming retraining.
Problem & Motivation
The core challenge in Open-Vocabulary Semantic Segmentation (OVSS) with frozen models like CLIP is the geometric mismatch. CLIP is trained for global image-text alignment, which often results in patch-level features being dominated by background "drift."
Previous methods treated this as a post-processing problem—using CRFs or auxiliary models to "clean up" the results. PEARL's authors argue that we should fix the geometry at the source: the attention mechanism itself. If the keys and queries are not in a compatible subspace, the resulting patch features will be inherently noisy.
Methodology: Align then Propagate
PEARL follows a principled two-step approach:
1. Procrustes Alignment (PA)
Instead of letting background tokens dominate the attention scores, PEARL solves an Orthogonal Procrustes problem within the last self-attention block. It calculates an optimal rotation matrix $R^*$ to align the key basis directly to the query subspace. This is a closed-form solution that preserves magnitudes and local angles while removing the biased drift that destabilizes patch-text similarity.
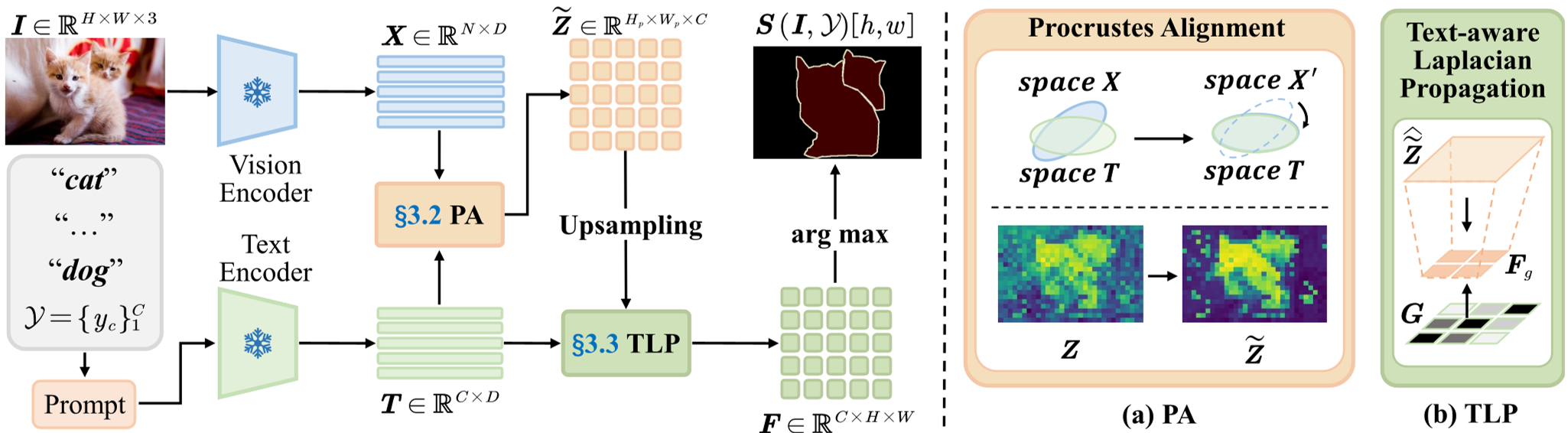
2. Text-aware Laplacian Propagation (TLP)
After alignment, the raw scores might still have "islands" of noise. PEARL uses the text encoder's own logic to fix this. It constructs a graph where:
- Data Trust: Nodes that align well with text prototypes are given higher confidence weights.
- Semantic Gating: Neighboring pixels are allowed to share information more freely if their predicted classes are semantically related in the text embedding space.
- Edge Preservation: Image gradients act as a gate to prevent semantics from bleeding across physical object boundaries.
Experiments & Results
PEARL was tested across 8 standard benchmarks (Pascal VOC, COCO-Stuff, Cityscapes, ADE20K, etc.).
Key Findings:
- Superior Accuracy: It achieved an average mIoU of 43.2, outperforming previous "No extra backbone" leaders like NACLIP (39.4) and SFP (39.6).
- Efficiency: Despite the mathematical rigor, PEARL is fast. Using a Newton-Schulz iterative solver instead of SVD, it reduces latency on Pascal VOC to just 48.7 ms/img.
- Visual Coherence: As seen in the qualitative results, PEARL effectively removes spurious "islands" and produces much cleaner boundaries for thin structures like poles and signs.

Critical Analysis & Conclusion
PEARL demonstrates a powerful insight: Language is not just a label; it's a structural prior. By using the relationship between text prototypes to guide the flow of pixel information, the model overcomes the "noise" inherent in zero-shot matching.
Limitations:
- Prompt Dependency: Like all CLIP-based methods, it is sensitive to the quality of the text prompts.
- Resolution Trade-off: The grid-based Laplacian solve requires choosing a grid size that balances detail and compute cost.
Conclusion: PEARL proves that we haven't reached the ceiling of what limited backbones like CLIP can do. By focusing on the geometric health of the features rather than just adding more parameters, PEARL provides a highly efficient path forward for real-time, open-world scene understanding.