本文提出了 PEARL,一种用于免训练开放词汇语义分割(OVSS)的新方法。该方法通过 Procrustes 对齐和文本感知拉普拉斯传播两步推理过程,在不使用额外视觉骨干网络或后处理的情况下,在多个基准测试上达到了 SOTA 性能。
TL;DR
在开放词汇语义分割(OVSS)领域,如何在不进行微调(Training-free)的前提下让 CLIP 等大模型精准理解像素语义?本文提出的 PEARL 给出了一种优雅的方案:无需额外的 DINO 骨干网络,无需庞大的后处理,仅通过几何对齐 (Procrustes Alignment) 和 文本感知传播 (Laplacian Propagation),即可将密集预测精度推向新高(Avg. mIoU 43.2%)。
核心痛点:为什么 CLIP 直接做分割效果差?
现有的免训练 OVSS 工作通常面临两个瓶颈:
- 几何不匹配 (Geometric Mismatch):CLIP 为了实现对比学习的全局一致性,其 Patch 级别的特征往往被少数背景方向主导,导致 Query 和 Key 的几何空间存在偏向,直接计算相似度会引入巨大噪声。
- 文本作为孤岛 (Text in Isolation):传统方法仅将文本视为分类器标签,忽略了“狗”和“猫”在文本空间中的临近性应引导像素间的语义流动。
PEARL:对齐后再传播
PEARL 遵循“先对齐、后传播”的直觉,将其分为两个高效的闭式解步骤:
1. 自注意力中的 Procrustes 对齐
作者在最后一个 Transformer Block 的 Self-Attention 中插入了一个正交 Procrustes 对齐模块。其物理直觉是:在不改变向量模长和相对角度的前提下,通过一个旋转矩阵 将 Key 空间对齐到 Query 子空间。
- 加权去中心化:抑制高模长的背景 Token 干扰。
- 正交因子分解:利用 SVD 或更高效的 Newton-Schulz 迭代计算旋转矩阵。
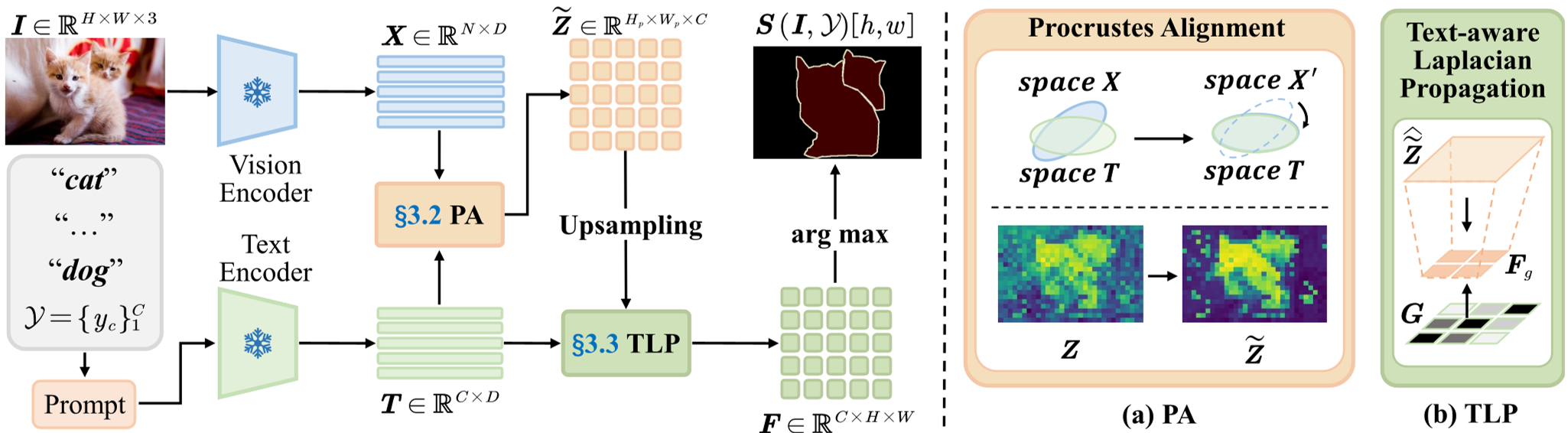 图 1:PEARL 框架。左侧展示了自注意力中的对齐,右侧展示了文本感知的拉普拉斯传播。
图 1:PEARL 框架。左侧展示了自注意力中的对齐,右侧展示了文本感知的拉普拉斯传播。
2. 文本感知的拉普拉斯传播 (TLP)
得到对齐后的 Logits 后,PEARL 构建了一个图,其中的边不仅受图像梯度限制(保护边界),更受文本原型间的语义相似度阈值控制。这使得语义能够从高置信度区域向低置信度区域平滑扩散,同时避免了不同类别间的过度平滑。
实验战绩:极致的效率与精度
PEARL 在 8 个主流数据集上全面超越了 NACLIP、SFP 等强基线,甚至在某些指标上逼近或超越了使用 DINOv3 辅助的复杂方法。
 图 2:可视化对比。PEARL 相比原生 CLIP(右)生成的 Mask 更加紧凑,对细长物体(如杆状物)的捕捉远超基线。
图 2:可视化对比。PEARL 相比原生 CLIP(右)生成的 Mask 更加紧凑,对细长物体(如杆状物)的捕捉远超基线。
关键量化数据:
- Pascal VOC (V21): 达到 64.1 mIoU,比强基线提升明显。
- 平均性能: 无辅助网络下达到 43.2 mIoU,确立了新的 Training-free SOTA。
- 效率: 在维持高性能的同时,显存占用保持在 1.32 GB 左右,Latency 极低。
深度洞察:为什么这种做法有效?
PEARL 的成功在于它意识到:语义就在几何之中。通过修正自注意力的注意力矩阵计算逻辑,模型实际上是在“擦亮眼睛”看 Patch 间的联系;而拉普拉斯传播则是引入了“常识”,让模型知道语义接近的类别在空间上也应具有连贯性。
总结与局限
PEARL 展示了密集预测任务并不总是需要重型的解码器微调。然而,它依然受限于 Prompt 的质量,且在处理极低对比度的边界以及实例识别(Instance-aware)方面仍有提升空间。这为未来的“Prompt 自动校准”和“自适应网格传播”留下了研究窗口。