本文提出了 Perceptio,一种通过在自回归序列中直接生成 2D 语义分割(SAM2)和 3D 离散深度(VQ-VAE)Token 来增强感知能力的视觉语言模型(LVLM)。该模型基于 InternVL 构建,在 RefCOCO 系列基准上刷新了 SOTA,并在 HardBLINK 空间推理任务中提升了 10.3% 的准确率。
TL;DR
尽管当前的视觉语言模型(LVLMs)能言善辩,但在面对“谁离摄像头更近”这类简单的 3D 空间问题时,往往表现得像个“盲人”。Amazon 团队提出的 Perceptio 框架通过一种巧妙的方式解决了这一痛点:它要求模型在给出文本答案之前,先在自回归序列中“吐出”代表 2D 语义分割和 3D 深度信息的特殊 Token。这种类似于“空间思维链”的设计,让模型从纯粹的语义理解跃升到了真正的几何感知。
痛点深挖:LVLM 的“空间贫血症”
目前的 SOTA 模型(如 InternVL, Qwen-VL)在处理图像字幕和通用问答时非常强大,但它们的一个致命短板是 空间理解(Spatial Understanding)。
- Prior Work 的局限:大多数模型试图通过大规模预训练来“隐式”学习空间关系。然而,实验证明这种能力并不会随规模自动涌现。
- 缺乏显式表征:模型没有 3D 信息的输出接口,无法验证其是否真正理解了场景的几何结构。
核心方法:显式感知 Token 生成
Perceptio 的核心直觉在于:如果模型能先看清物体的边界(2D)并估算出距离(3D),那么它的回答必然会更准确。
1. 感知增强的推理序列
模型不再直接输出答案,而是遵循如下格式:
[seg tokens] + [depth tokens] + [text tokens]
这意味着模型必须先进行“物理建模”,再进行“逻辑推理”。
2. 模型架构解析
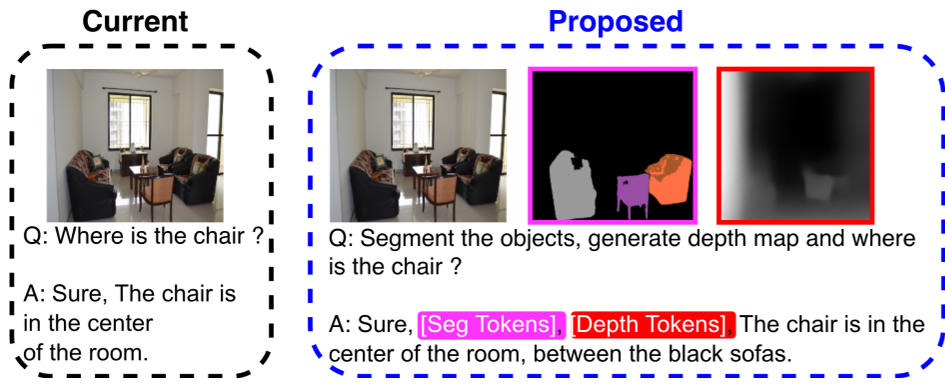
- 2D 路径:集成 SAM2。当预测到特殊的
[seg]Token 时,SAM2 解码器会结合视觉特征产生精确的分割掩码。 - 3D 路径:使用 VQ-VAE 离散化深度图。模型学习生成一组索引,这些索引对应预定义的深度码本(Codebook)。
- 软合并重构(Soft Depth Reconstruction):为了让离散生成的 Token 过程可导,作者使用了 Softmax 权重合并码本嵌入,确保了端到端的深度监督训练。
实验战绩:全方位的空降式领先
Perceptio 在多个维度上展现了压倒性的优势:
- Referring Segmentation (RES):在 RefCOCO 等基准上全面超越了 Sa2VA,证明了 3D 深度信息对 2D 定位也有显著加持。
- HardBLINK (空间推理金标准):在极难的相对深度判断任务中,Perceptio-8B 比之前的 SOTA (LLaVA-Aurora) 高出 10.3%。

消融分析:谁才是关键?
通过消融实验,作者发现了一个有趣的现象:
- 移除深度 Token:HardBLINK 准确率直接崩塌(从 71% 跌至 45%)。
- 移除分割 Token:通用的 VQA 能力会下降。
- 结论:2D 语义和 3D 几何是互补的,缺一不可。
深度洞察:为什么显式预测有效?
这实际上是在多模态领域践行了 Chain-of-Thought (CoT) 的思想。在文本 LLM 中,我们要求模型“一步步想”;在感知 LVLM 中,Perceptio 要求模型“一步步看”。
当模型必须显式地预测深度 Token 时,它实际上被迫在注意力机制中分配更多的权重给图像的几何纹理。这种 Inductive Bias(归纳偏置) 弥补了传统 Transformer 在结构化数据理解上的短板。
总结与展望
Perceptio 证明了:感知不是推理的后置插件,而应该是推理的前置基础。
局限性:
- 生成深度 Token 会引入额外的序列长度,导致推理开销略有增加。
- 对高质量教师模型(如 Depth Anything V2)有较强依赖。
未来方向:这种将感知信号 Token 化的思路,非常有潜力扩展到视频领域(如通过 Token 保持跨帧的几何一致性)或机器人具身智能领域(直接生成动作相关的空间 Token)。
本文由资深学术技术主编为您解读。获取更多 AI 前沿论文分析,请关注相关专题。