This paper introduces Physion-Eval, a large-scale benchmark for evaluating physical realism in AI-generated videos using expert human reasoning. It evaluates 12,718 videos from five state-of-the-art models (Sora 2, Veo 3.1, etc.) across 22 physical categories, revealing that over 80% of generated videos contain human-identifiable physical glitches.
TL;DR
While models like Sora and Veo produce cinematically stunning videos, do they actually understand gravity, collisions, or causality? Physion-Eval reveals a harsh truth: over 83% of AI-generated videos fail basic physics tests when scrutinized by experts. Even more alarming, current Multi-Modal Large Language Models (MLLMs), often used as automated judges, are remarkably "blind" to these physical glitches, missing up to 90% of failures that are obvious to a human eye.
The Motivation: Aesthetics $
eq$ Reality The AI community has recently pivoted from calling video models "generators" to calling them "World Simulators." For a model to simulate a world, it must respect the invariance of physical laws—objects shouldn't disappear, water shouldn't spray without a source, and ice shouldn't grow in volume while melting.
Existing metrics like FVD (Fréchet Video Distance) measure distribution shifts, which rewards "looking like a movie" rather than "behaving like the world." The authors of Physion-Eval argue that we lack a diagnostic tool to pinpoint exactly where and why these digital worlds break.
Methodology: Mining Reasoning, Not Just Labels
Physion-Eval isn't just a dataset of "Pass/Fail" grades. It is a massive collection of 10,990 expert reasoning traces.
- Diverse Sourcing: The researchers pulled videos from WISA-80K (exocentric/third-person) and EPIC-KITCHENS (egocentric/first-person) to cover 22 physical categories including rigid-body dynamics, fluid flow, and thermodynamics.
- Expert Pipeline: Instead of using random crowdsourced workers, they employed STEM-background experts and a "two-annotator + one-senior-reviewer" workflow to ensure the reasoning was grounded in undergraduate-level physics.
- Granular Taxonomy: Failures are classified into 8 categories such as Object Permanence, Causal Sequence Violation, and Material/State Inconsistency.
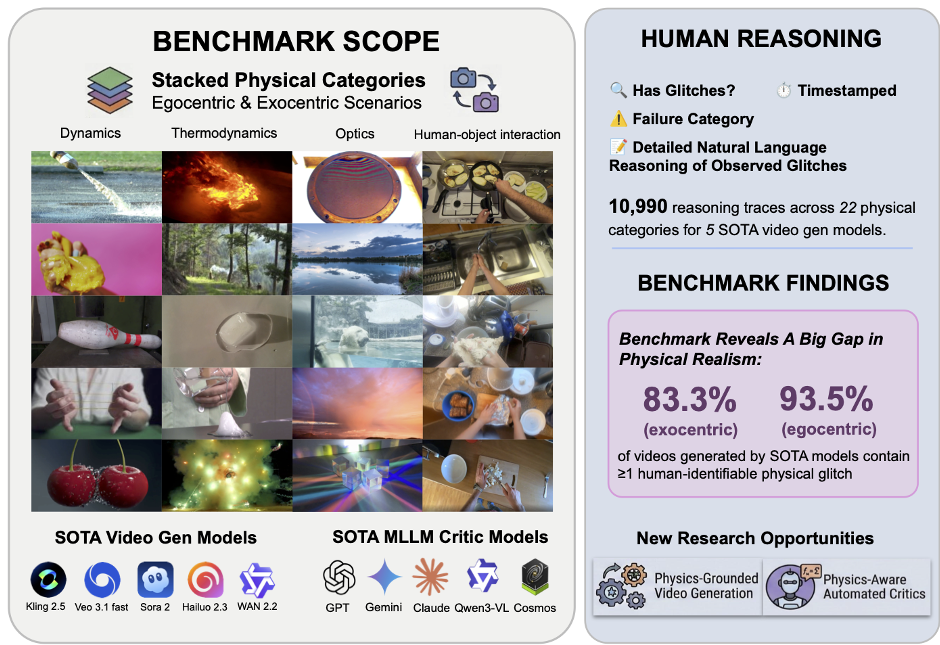 Figure 1: The Physion-Eval benchmark structure, showing the gap between human detection and model performance.
Figure 1: The Physion-Eval benchmark structure, showing the gap between human detection and model performance.
The Results: A Striking "Physical Gap"
The evaluation of 5 SOTA models (Kling 2.5, Veo 3.1, Sora 2, Hailuo 2.3, and Wan 2.2) yielded several critical insights:
- The Egocentric Nightmare: Models struggle significantly more with first-person views (93.5% failure rate) than third-person views. This is a major hurdle for Embodied AI, where a robot needs to predict the results of its own actions.
- The MLLM Blind Spot: The paper benchmarks 10 MLLMs as "critics." The result? They are far inferior to humans. Even Gemini 3.0 Pro, a top-tier model, often hallucinates causes for glitches or misses them entirely because it cannot reason across fine-grained temporal steps effectively.
 Figure 2: Common failure modes. Note the object merging and the lack of proper force response during impacts.
Figure 2: Common failure modes. Note the object merging and the lack of proper force response during impacts.
Deep Insight: Why Do Models Fail?
The authors suggest that the current denoising diffusion objective is the culprit. Diffusion rewards pixel-level reconstruction. If a model generates a frame that looks beautiful but is physically impossible (like a ball passing through a wall), the loss function doesn't necessarily penalize it as long as the "texture" looks realistic.
Furthermore, Internet-scale datasets are biased toward "cinematic" edits and flashy visuals rather than "clean" physical interactions. This biases models toward visual aesthetics over physical logic.
Critical Analysis & Future Outlook
The value of Physion-Eval lies in its diagnostic nature. By providing timestamped explanations, it allows researchers to:
- Deter Hallucinating Critics: Train better automated evaluators that actually ground their "reasoning" in visual evidence.
- Closed-loop Refinement: Use these human-in-the-loop reasoning traces to fine-tune models using RLHF (Reinforcement Learning from Human Feedback) specifically for physical consistency.
Limitations: The study focuses on single interactions. Real-world "multi-physics" (e.g., a gust of wind blowing a burning cloth into a pool of water) remains an even higher mountain to climb.
Conclusion
Physion-Eval is a wake-up call for the "World Simulator" narrative. It proves that we are still far from models that truly understand the causal and physical fabric of reality. For now, if you want to know if a video is physically real, don't ask an AI—ask a human with a physics degree.
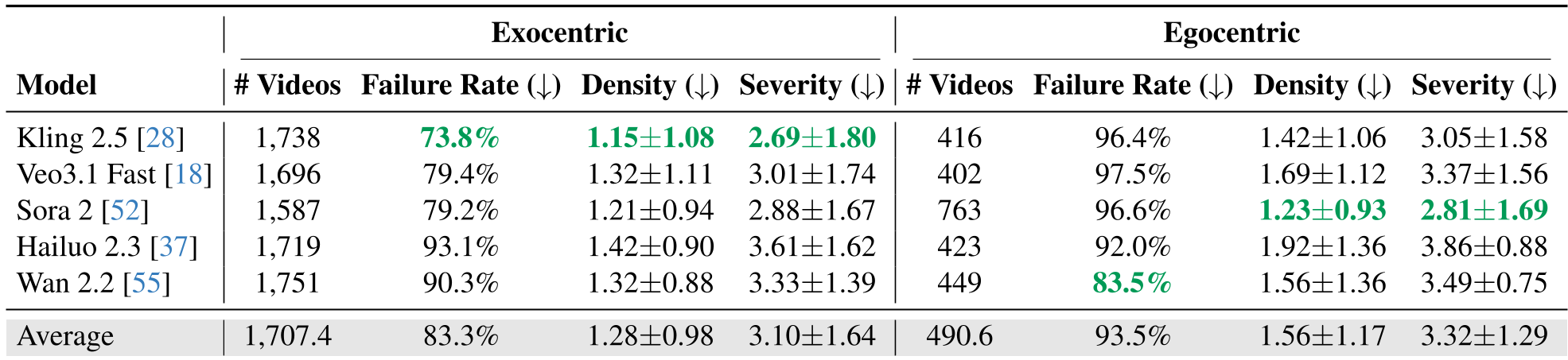 Table 1: Quantitative failure rates and glitch density across leading models.
Table 1: Quantitative failure rates and glitch density across leading models.