Pixelis is a 8B-scale vision-language agent that performs reasoning by directly executing pixel-space operations (segment, track, zoom, OCR) rather than relying on abstract text tokens. It achieves a state-of-the-art average relative gain of +4.08% over Qwen3-VL-8B across six benchmarks, including a +6.03% peak on VSI-Bench.
TL;DR
Pixelis is a breakthrough 8B-scale vision-language agent that stops treating images as static arrays and starts treating them as interactive playgrounds. By introducing a framework for Reasoning in Pixels, it uses executable tools (like zoom, segment, and track) to build auditable evidence chains. It outperforms traditional passive VLM baselines by up to 6.03% and—crucially—uses a novel Test-Time RL (TTRL) mechanism to self-correct and adapt to new environments without needing single human label.
The Passive Observer Problem: Why VLMs Hallucinate
Current state-of-the-art VLMs are remarkably good at "telling stories" about pixels, but they are fundamentally disconnected from the physical reality they describe. They are passive observers. If a model misidentifies a small object in the corner of a video, it has no mechanism to "lean in" (zoom) or "follow it" (track) to verify its own hunch.
When these models face "domain shift"—such as a change in lighting or camera motion—their performance collapses because they cannot act to resolve uncertainty. Pixelis was designed to fix this by closing the perception-action loop.
Methodology: The Three-Stage Evolution
The authors move beyond simple supervised learning into a sophisticated three-phase training regime that transforms a model into an agent.
1. SFT: Learning the Grammar of Action
The model first learns a "tool-use syntax" through Supervised Fine-Tuning on Chain-of-Thought-Action (CoTA) traces. Unlike regular CoT, CoTA interleaves thoughts with actual serialized tool arguments (e.g., segmenting specific coordinates).
2. CC-RFT: Curiosity vs. Coherence
Innovation strikes in the second phase. To prevent the model from just "clicking randomly," Pixelis uses Curiosity-Coherence Reward Fine-Tuning.
- Curiosity: Encourages the model to explore states where its internal "dynamics head" predicts a visual outcome different from what the current policy sees.
- Coherence: This is the "logic guardrail." It uses cosine similarity between adjacent step embeddings to ensure the model isn't "tool hopping" erratically. It rewards logical, smooth transitions between reasoning steps.
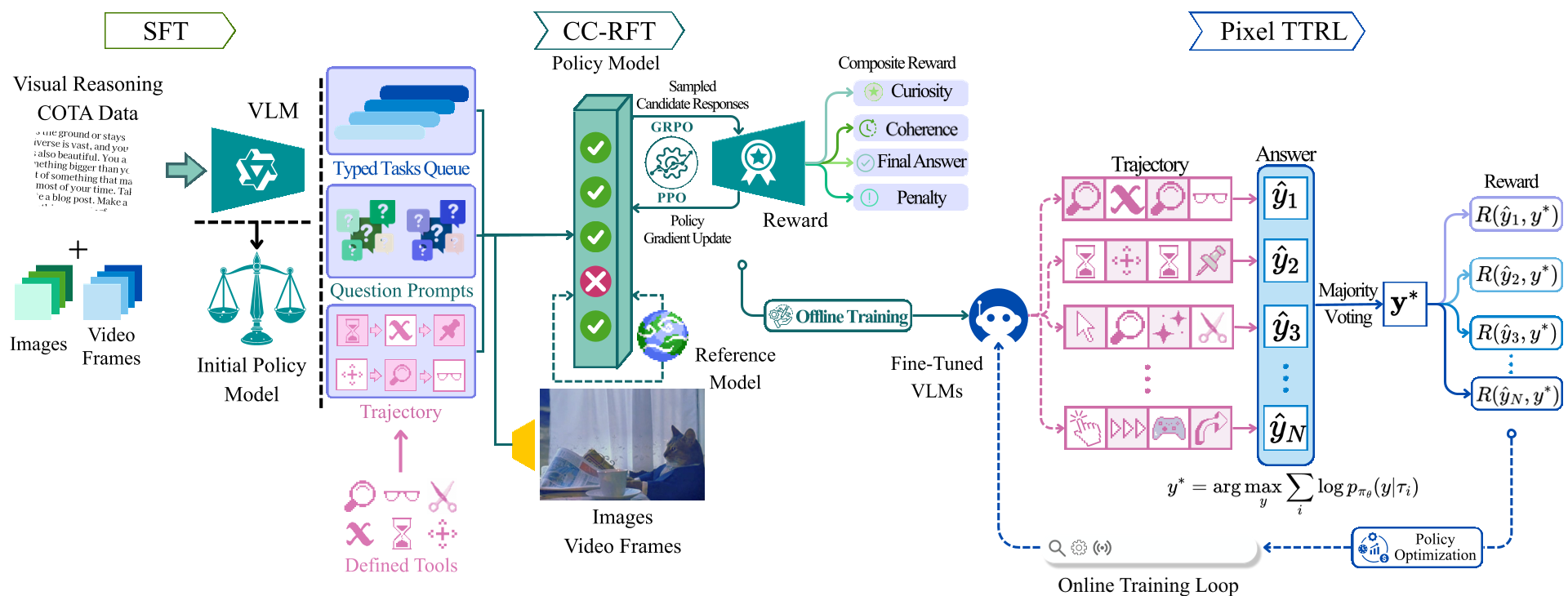 Figure 1: The three-phase pipeline from SFT to CC-RFT and finally Pixel TTRL.
Figure 1: The three-phase pipeline from SFT to CC-RFT and finally Pixel TTRL.
3. Pixel TTRL: Safe Self-Improvement
The third phase, Pixel Test-Time RL, is perhaps the most novel. At inference time, if the model is unsure, it retrieves "neighbors" from a memory index of past successful trajectories. It then performs trajectory-level voting. Instead of just picking the most common answer string, it looks for the most consistent behavioral pattern across the best-performing toolchains.
To prevent the model from drifting into "hallucination loops," they maintain a KL-to-EMA safety corridor. This keeps the updated policy from straying too far from a stable, slow-moving reference.
Experiments: Proof in the Pixels
Pixelis was tested on six grueling benchmarks (including V* Bench and MVBench). Using a Qwen3-VL-8B backbone, it didn't just beat the baseline; it did so with shorter, cleaner reasoning.
- Efficiency: Average chain lengths dropped from 6 steps to 3.7.
- Stability: Under lighting and motion shifts, Pixelis maintained a 3.5% accuracy gain while non-safe variants collapsed.
- Ablation Insight: Removing "coherence" led to visual tool hopping, while removing "curiosity" led to redundant, over-local chains.
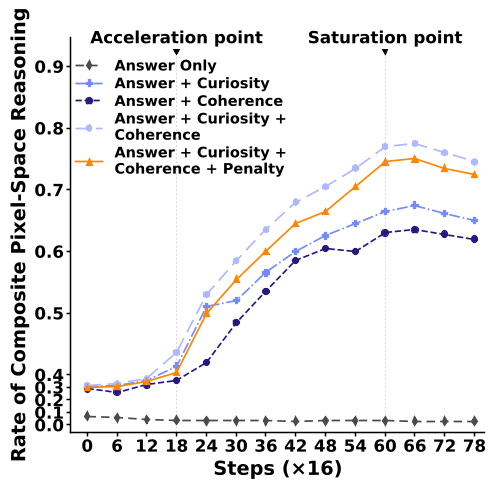 Figure 2: Pixel TTRL performance. Note how the "Safe" variant keeps token KL within the corridor while improving accuracy.
Figure 2: Pixel TTRL performance. Note how the "Safe" variant keeps token KL within the corridor while improving accuracy.
Critical Analysis: Why This Matters
The technical brilliance of Pixelis lies in its Visual Fidelity (VisFid) metric. By scoring the model on whether its tool outputs (like a mask IoU) actually match the evidence, it forces the AI to be honest. It replaces the "text-only" heuristic—which is prone to linguistic shortcuts—with a physical grounding requirement.
Limitations:
- The complexity is high: running segmentation and tracking tools at inference time adds significant latency (≈5.8s median).
- It relies on "non-differentiable" tools, meaning if the underlying segmentor (like SAM2) fails on a thin structure, the error propagates.
Conclusion
Pixelis marks a shift from LLMs that talk to agents that do. By treating pixels as verifiable evidence and toolchains as self-supervision, it provides a blueprint for the next generation of embodied AI that can learn "in the wild."
Final Takeaway: Acting within pixels, rather than abstract tokens, grounds multimodal perception in the physical world and enables autonomous adaptation without a human in the loop.