This paper presents a large-scale, data-driven empirical study of over 2,000 Reinforcement Learning (RL) environments, proposing a novel multi-dimensional taxonomy. It highlights the "From Pixels to Digital Agents" transition, documenting the shift from physical simulations to LLM-driven semantic reasoning agents.
Executive Summary
TL;DR: This massive empirical study analyzes over 2,000 publications to map the transition of Reinforcement Learning (RL) from "System 1" reactive pixel-pushing (Atari) to "System 2" deliberative semantic agents (LLMs). The authors reveal that environmental complexity, not just algorithm design, is the true catalyst for AGI.
Background: Positioned as a definitive taxonomic roadmap, this work transitions the field's focus from the "Agent" (the learner) back to the "Environment" (the generative crucible), arguing that the world-side of the MDP equation is what determines the upper bound of artificial intelligence.
Problem & Motivation: The Fragmentation of the "Wild West"
Historically, RL has suffered from a "crisis of reproducibility." Agents that achieve superhuman scores on isolated benchmarks often fail catastrophically when face with minor perturbations. The authors argue this is because we treat environments as static containers.
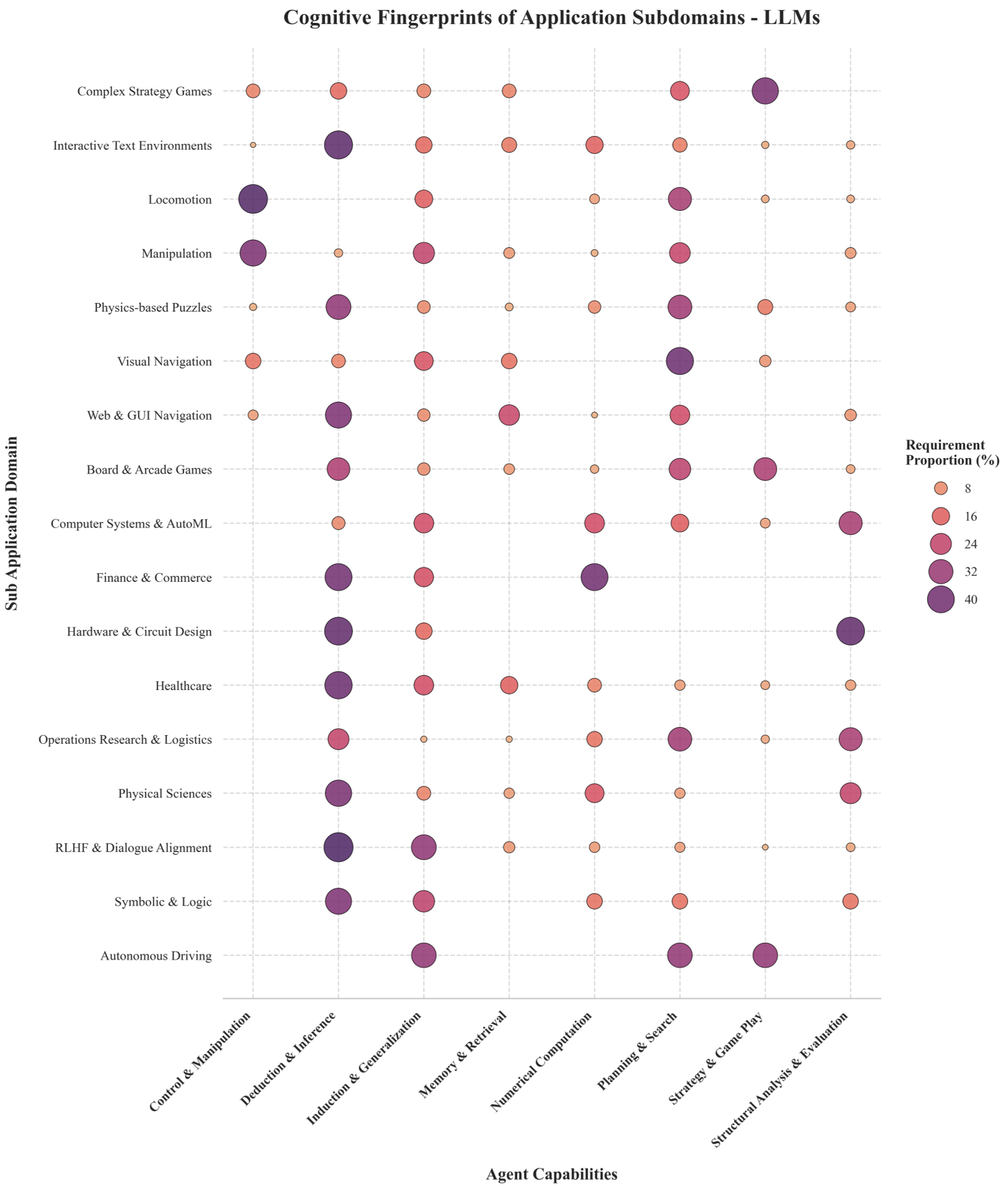
The motivation is clear: to move away from picking environments based on popularity and toward a rigorous understanding of Cognitive Fingerprints—the specific mental muscles (Memory, Deduction, Induction) that a task forces an agent to flex.
Methodology: The 7-D Taxonomy of Intelligence
The authors decompose the Markov Decision Process (MDP) into seven strategic dimensions to evaluate how "worlds" are built:
- Observability: From the "Perfect Information" of Chess to the "Digital Compartmentalization" of Web Browsing.
- Action Space: The evolution from physical torques to auto-regressive token generation.
- Reward Formulation: The shift from dense programmatic heuristics to sparse, human-aligned preference models (RLHF).
The Evolutionary Tree
The study categorizes the history of RL into four distinct epochs (2013-2025+), tracking the "Ascent of Cognitive Abstraction."
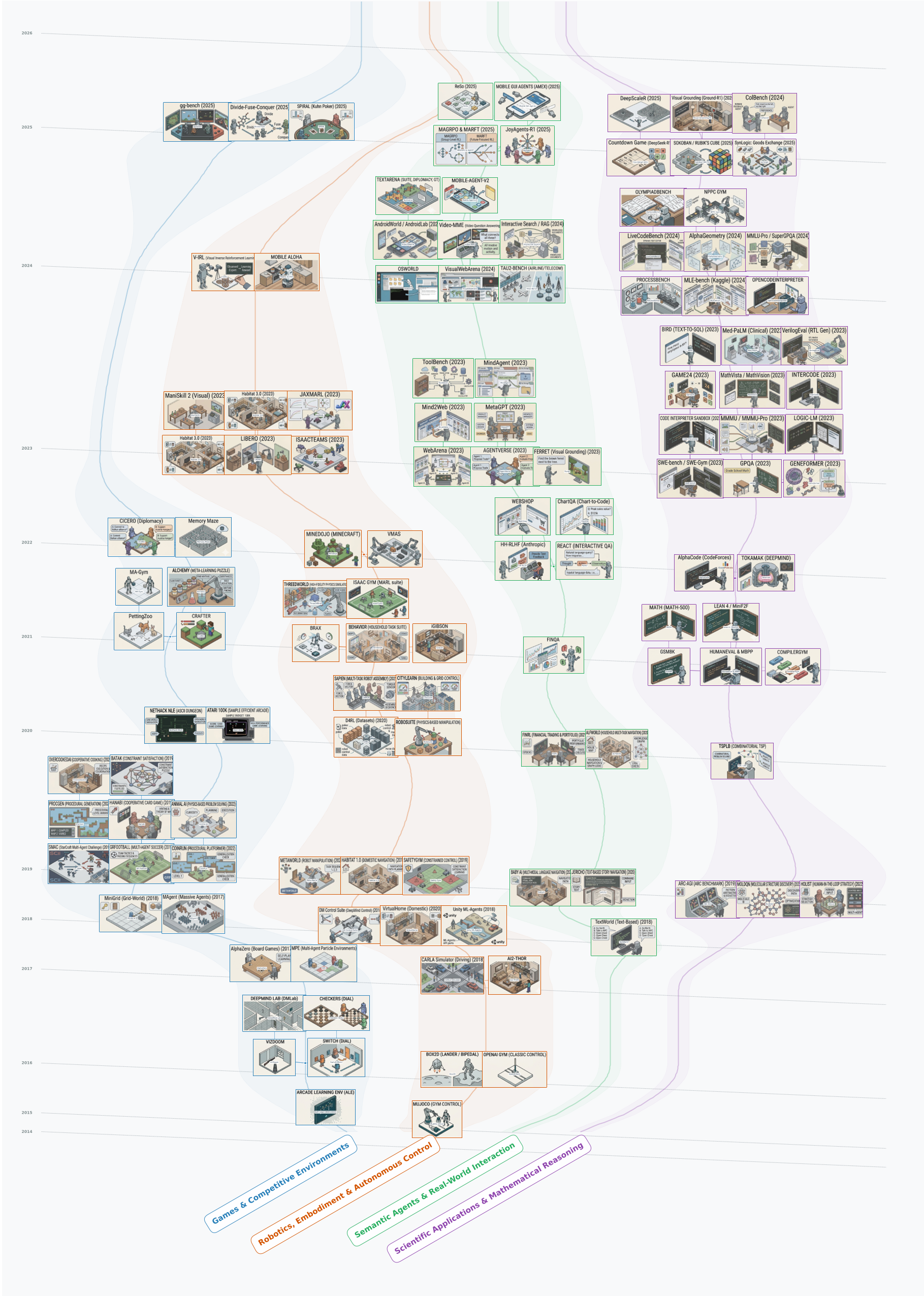
Two Ecosystems: Semantic Priors vs. Domain-Specific Generalization
The paper uncovers a fascinating bifurcation in modern AI:
- The LLM Ecosystem: Governed by the Semantic Prior. These agents don't learn from scratch; they deduce context from massive pre-trained knowledge. Their "fingerprint" is heavy on Deduction & Inference.
- The Broader RL Ecosystem: Focused on Domain-Specific Generalization (DSG). These agents survive on brute-force Planning & Search (like Monte Carlo Tree Search) and excel in NP-hard industrial optimization.
Performance & Capability Shifts
The data verifies a definitive migration: while physical control (Robotics) has stagnated due to the "sim-to-real" gap, System 2 Reasoning and Digital Agent benchmarks are exploding.
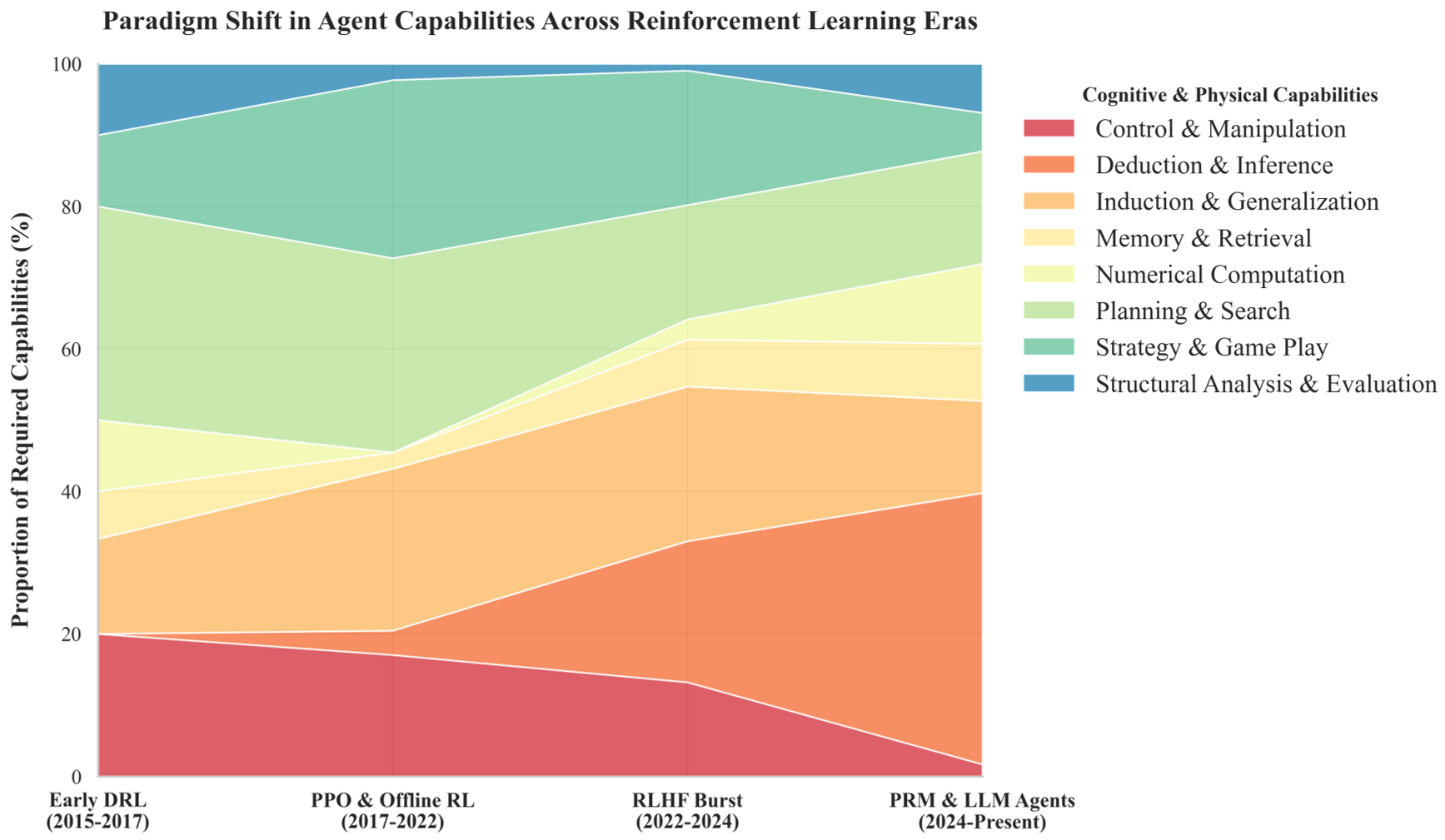
Deep Insight: The Convergence in STEM
A critical takeaway is the "Universal Need for Evaluation." Whether an agent is a GNN solving chip floorplanning or an LLM solving Verilog code, both require Structural Analysis. The environment's role has shifted from rewarding "what" happened to verifying "how" it happened through Process Reward Models (PRMs).
Critical Analysis & Future Perspectives
The paper concludes with a warning: Data Contamination. Because text-based environments are easily absorbed into LLM training sets, static benchmarks are dying.
The Path Forward:
- Procedural Semantic Generation: Environments that generate novel, logically sound puzzles on the fly.
- Embodied Semantic Simulators: The "Grand Convergence" where agents must perform high-frequency motor control while reasoning over complex, contradictory natural language manuals.
Conclusion
If RL is the engine of AGI, the environment is the road. This paper proves that to reach the destination, we must stop building better engines and start building more complex, procedurally generated, and semantic roads.