本文提出了 Planner-centric Multi-agent Framework,这是一种将 UI 自动化任务分解为 Planner(规划者)、Actor(执行者)和 Memory Manager(记忆管理器)的高效协作框架。核心成就:通过仅针对 Planner 进行强化学习(RL)优化,使 Qwen2.5-VL-7B 在 WebVoyager 上的表现提升了 28%,并超越了 GPT-4o 和 Gemini-2.5-Pro 等闭源模型。
TL;DR
在复杂的 UI 自动化任务(如网页导航、系统控制)中,传统的“一个模型包揽全局”的做法正面临严重挑战。来自 UCSD 的研究团队提出:规划(Planning)才是 Agent 性能的“一等公民”。通过将系统拆分为 Planner、Actor 和 Memory 三个角色,并发现 Planner 的模型规模直接决定了成败。实验证明,用 32B 的 Planner 搭配 7B 的 Actor 的效果,远好于三个模块均匀分配资源。
背景定位:从单体模型到模块化协作
当前的视觉语言模型(VLM)虽然强大,但在处理需要多步骤推理的长时程任务(Long-horizon tasks)时,常常顾此失彼。
- “细节迷失”:模型虽然点准了按钮,但忘了最初的搜索限制条件。
- “眼高手低”:模型知道该去比价,却在繁琐的点击跳转中操作失误。
该文提出的框架(见下图)通过角色解耦,成功让开源小模型在多项基准测试中“逆袭”闭源巨头。
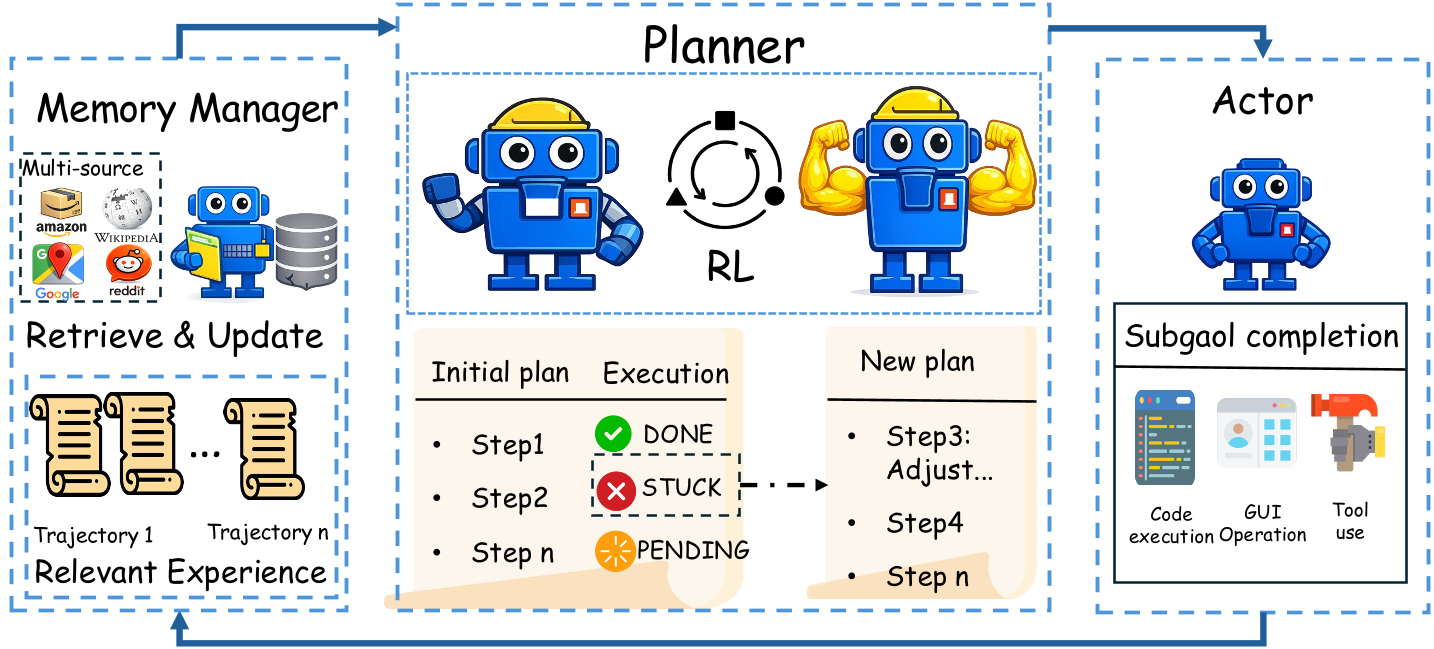
核心洞察:为什么要“厚此薄彼”?
作者进行了一次极具启发性的核心实验:Scaling Analysis。他们分别对 Planner、Actor 和 Memory Manager 的模型规模进行独立横向扩展。
实验发现:
- Planner 决定天花板:Planner 的性能增长趋势()几乎与升级整个系统一致。
- Actor 是合格劳动力即可:一旦 Actor 达到一定规模(如 7B),继续增加参数对整体任务成功率的边际收益递减。
- Memory 最不“吃”资源:更小的模型就能胜任上下文检索任务。
这一结论在神经科学中亦有映证:人类的高级决策受控于前额叶皮层(类似 Planner),这通常是复杂任务的性能瓶颈。

方法详解:Planner-Centric RL
基于上述洞察,作者提出了一种极其高效的训练策略——只练规划者。
- 模块化 RL:冻结 Actor 和 Memory,仅使用 GRPO 算法对 Planner 进行微调。这样做避免了角色冲突(Role Confusion),让模型专注于“想清楚下一步该干什么”。
- VLM-as-judge 奖励机制:利用强大的 Qwen2.5-VL-32B 作为裁判,从任务正确性、推理连贯性和交互效率三个维度对完整轨迹打分(1/3/5分制)。
- 记忆增强:Planner 能够同时访问离散记忆(过去的文字总结)和连续记忆(多模态 Embedding),显着提升了跨界面泛化能力。
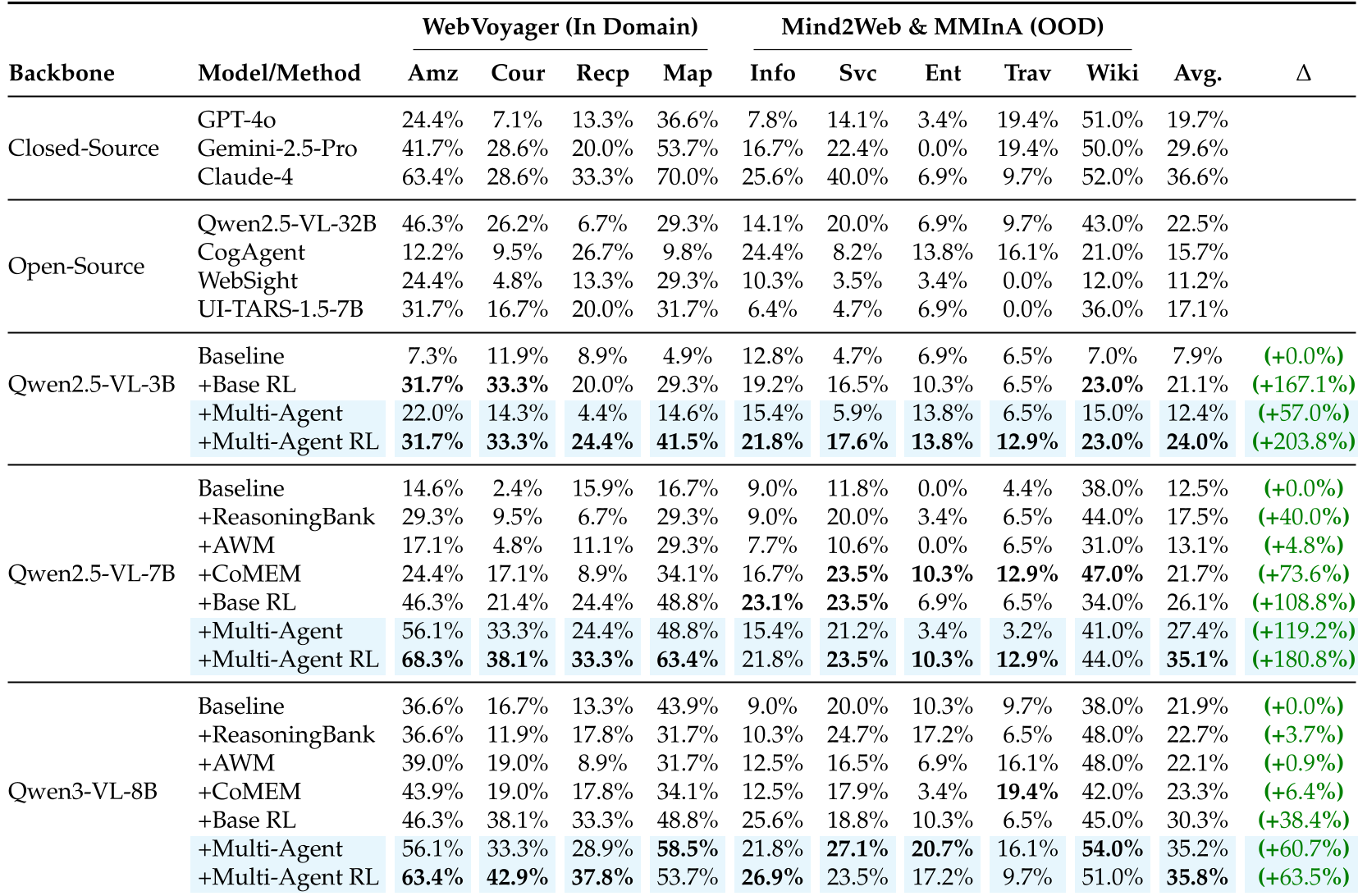
实验战绩与深度洞察
在 WebVoyager、OSWorld 和 MCPBench 三个领域的全面测试中,该框架展现了统治力:
- Web 端:Qwen2.5-VL-7B 协作模型总体表现超越 GPT-4o 78%。
- 通用性:在完全未见过的网站和桌面应用中,Planner 表现出极强的反思和修正能力(见下表对比)。
消融实验的关键启示
有趣的是,作者对比了“联合训练(Joint Training)”和“仅训练 Planner”。结果显示,联合训练反而更差。这说明在同一个模型里强行塞入“高层规划”和“底层操作”两种不同的归纳偏置(Inductive Bias),会引发模型的知识遗忘或角色混乱。
总结与局限性
这篇论文为 Agent 的工程落地提供了一套清晰的“性价比手册”:
- 资源分配:高配 Planner + 标配 Actor。
- 优化重心:优先打磨长程规划的 RL,而非底层动作的 SFT。
局限性:目前的奖励信号仍然是“轨迹级”的,分配到每个中间步骤时可能存在信号稀疏问题。未来引入过程奖励(Process Rewards, PRMs)可能会进一步解锁 Agent 的潜力。
Senior Editor's Note: 该研究标志着 Agent 研究从“大力出奇迹”进化到了“精细化治理”阶段。它告诉我们,赋予 Agent 灵魂的不是它能执行多少种 API,而是它面对复杂环境时那份“临危不乱”的逻辑规划。