Points-to-3D is a diffusion-based 3D generation framework that utilizes point cloud priors (from LiDAR or VGGT predictors) to achieve geometry-controllable asset and scene synthesis. Built upon the TRELLIS architecture, it treats 3D generation as a latent inpainting task, achieving SOTA performance in geometric fidelity and rendering quality.
TL;DR
Points-to-3D bridges the gap between unconstrained generative synthesis and precise geometric reconstruction. By integrating point cloud priors (from sensors or predictors) directly into the latent space of a diffusion model, this framework transforms 3D generation into a sophisticated "inpainting" task. It doesn't just "imagine" a 3D object; it builds around the facts you give it.
Background Positioning: This work is a significant "control-oriented" upgrade to the TRELLIS framework, shifting the paradigm from purely reference-based (image/text) generation to structural-anchored generation.
Problem & Motivation: The "Hallucination" Gap in 3D
Current SOTA 3D generators like TRELLIS or LGM are remarkably good at creating plausible assets from single images. However, they suffer from a lack of geometric accountability. If you have a LiDAR scan of a sofa's front, a standard model might generate a back that is "plausible" but mathematically inconsistent with the provided dimensions.
The authors observed a critical wasted opportunity: active sensors (LiDAR, Depth cameras) and feed-forward predictors (like VGGT) provide explicit 3D measurements that existing models simply ignore by starting their diffusion process from pure Gaussian noise.
Methodology: Generation as Latent Inpainting
The core innovation of Points-to-3D is treating the partial 3D observation as a fixed anchor in the latent space.
1. Structural Latent Initialization
Instead of starting with noise , the model:
- Voxelizes the input point cloud into a grid .
- Encodes it using a Sparse Structure VAE to get a visible latent .
- Combines this with noise using a mask : .
2. The Staged Sampling Strategy
The inference process is split into two distinct phases to maintain the "truth" while ensuring environmental harmony:
- Inpainting Stage: Focuses on completing the global skeleton/structure based on the visible priors.
- Refinement Stage: Switches from masked inpainting to standard denoising to "heal" the boundaries where the known point cloud meets the generated regions, preventing "holes" or seams.
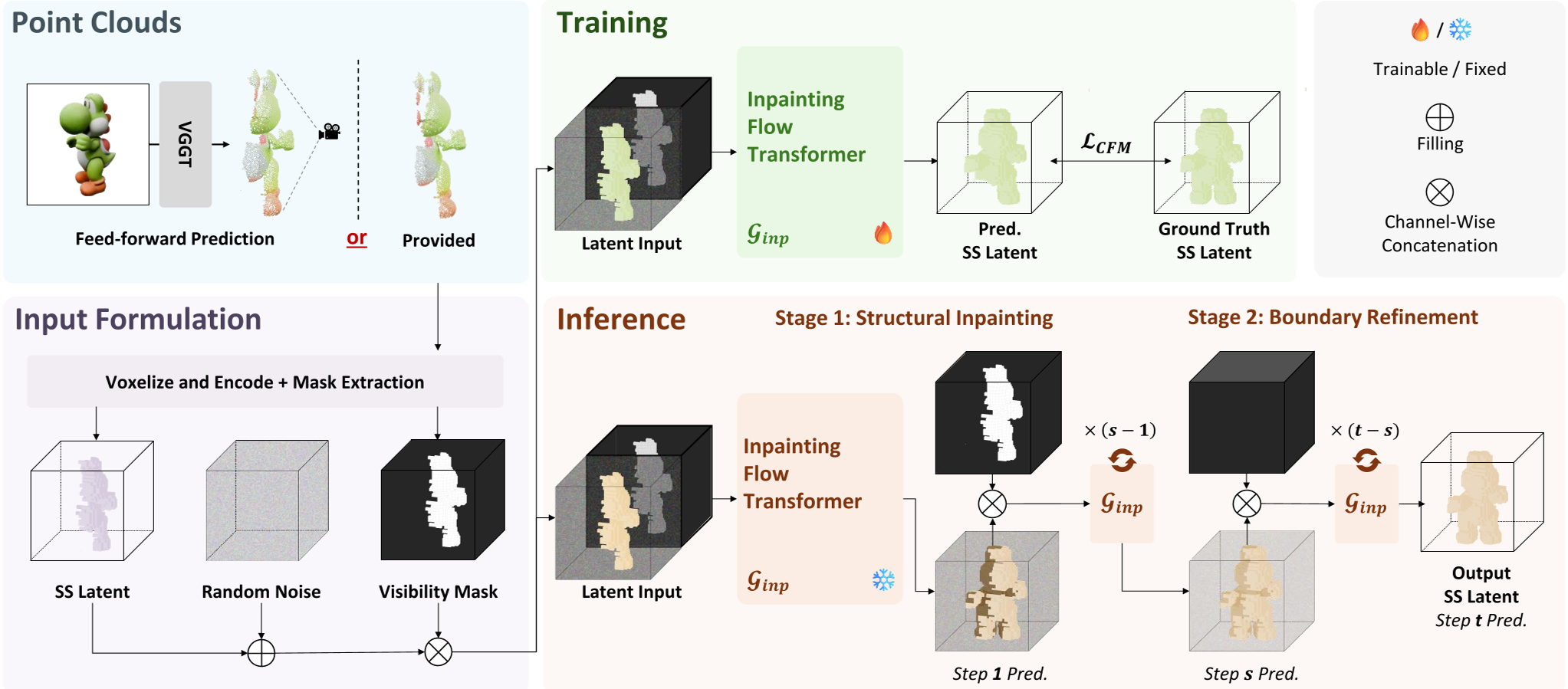 Figure 1: The Points-to-3D Pipeline showing the transition from point cloud priors to completed 3D assets via a two-stage sampling procedure.
Figure 1: The Points-to-3D Pipeline showing the transition from point cloud priors to completed 3D assets via a two-stage sampling procedure.
Experiments & Results: Precision Meets Creativity
The model was tested across object-level (Toys4K) and scene-level (3D-FRONT) benchmarks.
Quantifiable Superiority
In the Toys4K benchmark, the "Geometric Fidelity" metrics tell a clear story:
- F-Score: Ours (0.964) vs. TRELLIS (0.832).
- Chamfer Distance: Ours (0.013) vs. TRELLIS (0.034).
This indicates that the model isn't just making things look good (rendering) but is accurately placing surfaces in 3D space.
Visual Evidence
The refinement stage proves essential. Experiments show that without the "Boundary Refinement" steps (Inp:50, Ref:0), the output suffers from structural holes. By balancing 25 steps of each, the model achieves the highest PSNR-N (Normal map quality).
 Figure 2: Visual comparison showing superior geometric alignment and normal map consistency compared to SOTA baselines.
Figure 2: Visual comparison showing superior geometric alignment and normal map consistency compared to SOTA baselines.
Critical Analysis & Conclusion
Points-to-3D successfully demonstrates that geometric priors are first-class citizens in 3D generation. By moving the structural constraint into the latent space initialization, the model avoids the "steering" lag seen in attention-based conditioning.
Takeaway: This is a major step for practical AR/VR content creation where "matching the real room" is more important than "creating a random cool room."
Limitations: The performance is still somewhat bounded by the quality of the point cloud predictor (VGGT) when sensor data isn't available. Future work might involve end-to-end training of the predictor and the generator for better error tolerance.
Future Outlook: We expect this "Latent Inpainting" paradigm to spread to Multi-modal Large Language Models, where users can provide a "sketch" in 3D (via LiDAR) and ask the AI to "finish the room" with specific semantic styles.