The paper introduces PokeVLA, a compact (1.22B parameter) Vision-Language-Action foundation model for robotic manipulation. It employs a two-stage training paradigm—pre-training on a 2.4M sample embodied dataset and fine-tuning with multi-view geometry alignment and goal-aware segmentation—achieving SOTA results on the LIBERO-Plus benchmark and real-world tasks.
TL;DR
The robotics community has long wrestled with a paradox: larger Vision-Language-Action (VLA) models offer better reasoning but are computationally heavy and often lack the fine-grained spatial awareness needed for precise manipulation. PokeVLA breaks this cycle by delivering a 1.22B parameter model that outshines 7B giants. By integrating a 2.4M-sample embodied pre-training stage and a novel "Goal-Aware" segmentation mechanism, PokeVLA sets a new SOTA on the LIBERO-Plus benchmark and showcases remarkable robustness in real-world deployment.
Problem: The Blind Spots of Generalist VLAs
Modern VLAs like OpenVLA typically inherit their intelligence from general-purpose Vision-Language Models (VLMs). While these backbones are great at identifying "an apple," they struggle with:
- The Reasoning Gap: General web data doesn't teach a model that a "red apple" on the "rightmost" side requires a specific gripper orientation.
- Spatial Inconsistency: When a model looks at a scene through both a static base camera and a moving wrist camera, it often fails to realize it's looking at the same object.
- Coarse Action Guidance: Raw features from the last layer of a VLM are often too "fuzzy" for high-precision action experts to decode into specific trajectories.
Methodology: The Two-Stage "Poke" Strategy
Phase 1: Embodied Pre-training (The "PokeVLM")
The authors don't just use a vanilla VLM. They curate a massive 2.4M dataset covering four pillars: General VQA, Spatial Grounding, Affordance Learning, and Embodied Reasoning. This ensures the backbone (based on Qwen2.5-0.5B) is "born" with robot-centric vision.
Phase 2: Action Injection & Geometric Alignment
To bridge perception and action, PokeVLA introduces three key innovations:
- Goal-Aware Segmentation: Using an
<SEG>token (inspired by LISA), the model learns to predict semantic masks of targets across multiple views. This forces the model to maintain a "unified target representation." - Geometry Alignment: During training, the VLA's hidden states are aligned with a 3D geometric foundation model (VGGT). This "Spatial Forcing" allows the model to "understand" 3D depth and structure using only 2D inputs during inference.
- The Action Head: Instead of simple MLP projection, a cross-attention-based action head aggregates the enhanced geometry features, the
<SEG>semantics, and robot proprioception to generate action chunks.
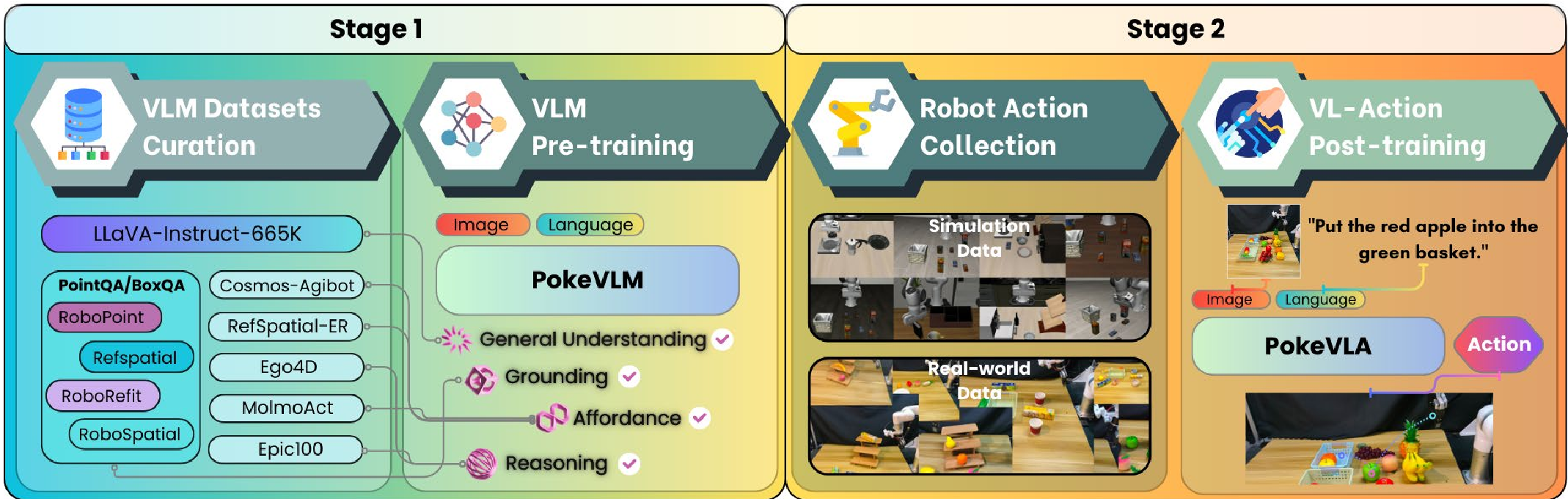 Fig 1: The dual-stage training pipeline and model architecture of PokeVLA.
Fig 1: The dual-stage training pipeline and model architecture of PokeVLA.
Performance: Small Model, Big Results
The "Pocket-sized" 1.22B model doesn't just hold its own; it dominates.
- SOTA Benchmarking: On LIBERO-Plus, PokeVLA reached 83.5% success, notably excelling in "Robot Initialization" and "Camera Viewpoint" perturbations where traditional models fail.
- Generalization Power: In a "Zero-shot Transfer" test (trained on LIBERO, tested on LIBERO-Plus), PokeVLA reached 79.3%, nearly 10% higher than the significantly larger OpenVLA-OFT (7B).
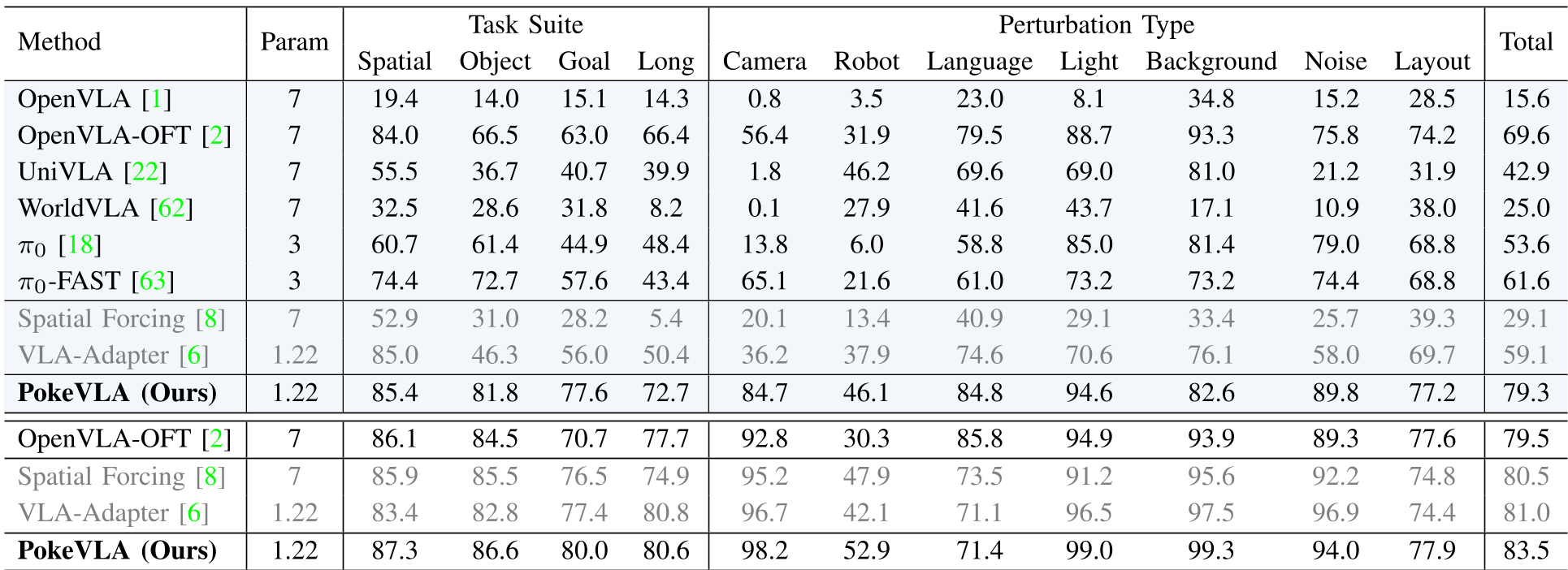 Fig 2: Comparative performance on LIBERO-Plus tasks and various environmental perturbations.
Fig 2: Comparative performance on LIBERO-Plus tasks and various environmental perturbations.
The "Why": Why does it work?
Ablation studies reveal that Goal-Aware Segmentation is the MVP for robustness. By forcing the model to segment the target, it effectively "filters out" background noise like changing lights or flickering textures. The model stops being distracted by the world and starts focusing on the task.
 Fig 3: Visualizing the robustness of goal-aware segmentation under diverse perturbations.
Fig 3: Visualizing the robustness of goal-aware segmentation under diverse perturbations.
Deep Insight: A New Paradigm for Efficiency
The most striking takeaway from PokeVLA is that parameter count is not the only path to intelligence. By distilling 3D geometry information during training (Geometry Alignment) and using dedicated tokens for semantic grounding, PokeVLA achieves a level of "Spatial Awareness" that previously required much larger models or additional sensors (like LiDAR/Depth).
Limitations and Future Work
While PokeVLA is highly efficient, it still relies on a SAM-based teacher for segmentation labels during training. Future iterations might move toward self-supervised target discovery to remove the need for human-in-the-loop mask annotations.
Conclusion
PokeVLA proves that with the right embodied priors and a clever architecture that aligns geometry and semantics, a 1.22B parameter model can be a world-class robot controller. For the industry, this signals a future where powerful VLAs can run locally on edge devices with high frequency and high reliability.
Check out the project page for videos of PokeVLA in action: getterupper.github.io/PokeVLA