本文提出了 PokeVLA,一种轻量级(1.22B参数)的具身视觉-语言-动作(VLA)模型。通过两阶段训练(具身知识预训练和操作优化),在 LIBERO-Plus 基准测试及真实世界评估中显著超越了 OpenVLA 等更大规模的基线模型,达成 SOTA 性能。
TL;DR
在具身智能(Embodied AI)飞速发展的今天,大参数模型往往意味着高昂的推理代价。PokeVLA 的出现打破了“模型越大越好”的迷思。它仅凭 1.22B 的紧凑参数量,通过精准的具身先验注入和多视角语义/几何对齐,在 LIBERO-Plus 等硬核榜单上击败了规模大其数倍的模型。它不仅能听懂指令,还能像人类一样理解物体的空间关系和操作可行性(Affordance)。
痛点深挖:通用 VLM 真的懂机器人吗?
尽管谷歌的 RT-2 等工作证明了互联网规模的视觉语言模型(VLM)可以迁移到机器人领域,但学术界逐渐发现三大瓶颈:
- 领域偏见:通用 VLM 在猫马图片上训练,对“机械臂夹取点”或“物体的相对深度”缺乏直觉。
- 三维盲区:依赖 2D 图像输入的模型,在面对视角变换(Camera Viewpoint Shift)时极易崩溃。
- 特征污染:动作头直接接收 VLM 最后一层的原始特征,里面充斥着大量与当前任务无关的视觉背景噪声。
方法论详解:PokeVLA 的“制胜两步走”
1. 具身知识的“补课”(Pre-training)
作者构建了一个包含 2.4M 样本的超大具身数据集。与以往不同,这些数据不只是“图注”,而是涵盖了:
- 空间定位 (Grounding):物体在哪里?
- 交互能力 (Affordance):哪里是可以抓握的?
- 具身推理 (Reasoning):为什么要先开抽屉再拿球?
通过在这类数据上训练 PokeVLM(基于 Qwen2.5-0.5B 和双视觉编码器),模型在起跑线上就具备了更强的物理世界常识。
2. 精准的操作引导(Post-training)
这是 PokeVLA 最核心的创新。它在动作生成过程中增加了几个辅助任务:
- 目标感知分割 (Goal-Aware Segmentation):引入特殊的
<SEG>符号,强迫模型预测任务目标在主相机和手眼相机中的蒙版(Mask)。这不仅对齐了视角,还过滤了背景干扰。 - 几何强制对齐 (Geometry Alignment):利用 VGGT 基础模型提取的 3D 几何特征去监督视觉特征,让 2D 卷积网络也能“脑补”出 3D 结构。
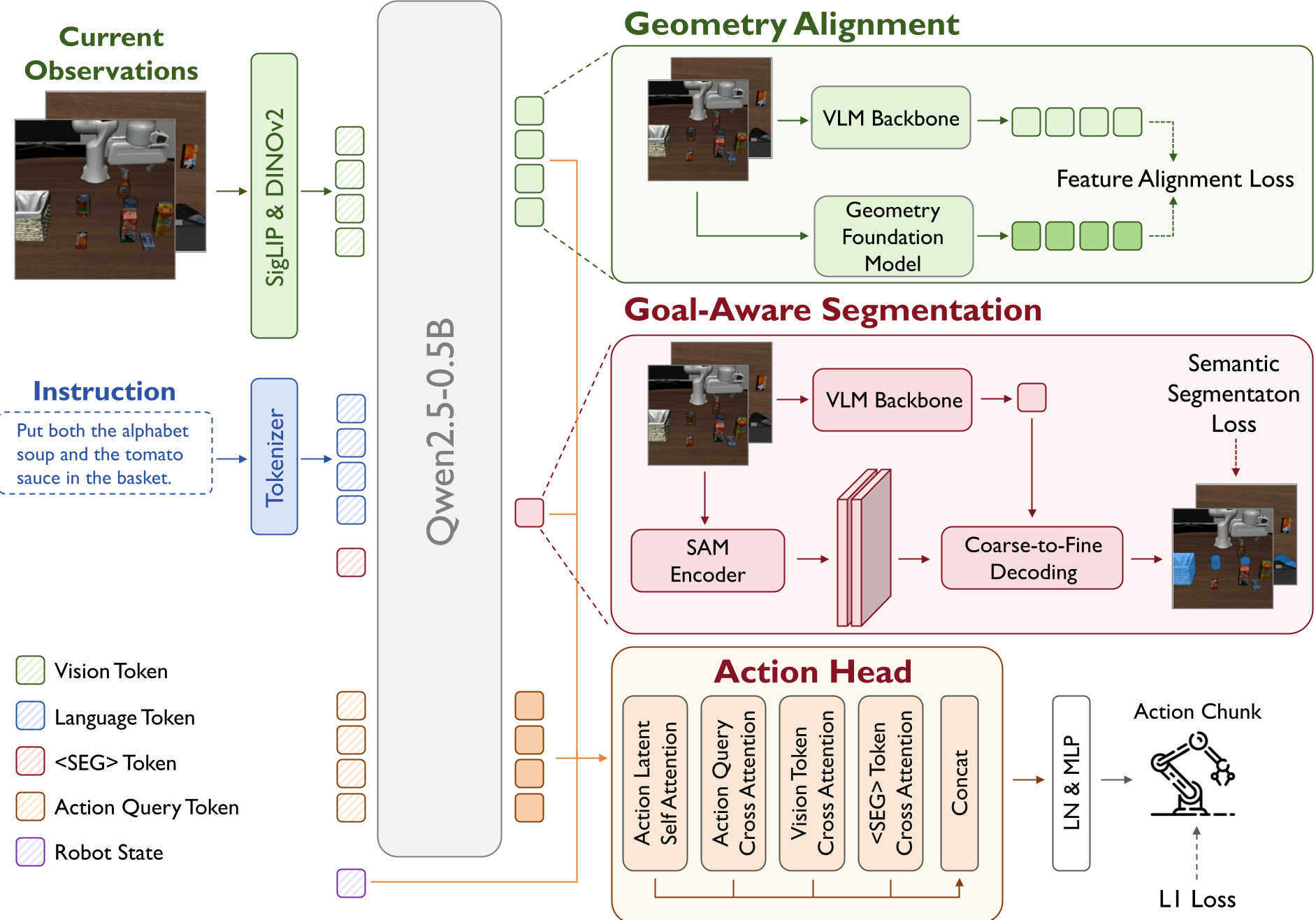
图 1:PokeVLA 整体架构。展示了从视觉特征提取、<SEG> 预测到 Action Head 动作生成的闭环过程。
实验与结果:小参数,大能量
仿真基准:LIBERO-Plus
在极具挑战性的 LIBERO-Plus 扰动测试中(包含光照改变、物体随机摆放、摄像头偏移),PokeVLA 展现了惊人的生命力:
- 总成功率:83.5%(SOTA)。
- 零样本泛化:在从未见过的环境扰动下,表现比 OpenVLA-OFT 强出近 10%。

图 2:在 LIBERO-Plus 上的各项数据对比。蓝色部分展示了在多种环境波动(如相机视角、光照、背景)下,PokeVLA 相较于基线的稳定性提升。
真实世界实验
在 xArm7 机械臂上的实测显示,PokeVLA 对“把最右边的水果放进盘子”这类包含空间方位描述的复杂指令,理解准确度远超 VLA-Adapter。

图 3:真实世界操作演示。模型成功识别“空盘子”并完成一系列颜色和方位相关的操作。
深度洞察与总结
PokeVLA 成功的本质逻辑在于:与其指望模型在海量通用数据中“悟出”操作逻辑,不如在小规模模型中显式地注入空间和语义约束。
- 它的价值:为端侧机器人部署提供了新路径。通过高效的辅助任务(分割、对齐),小型模型也能拥有大型模型的鲁棒性。
- 局限性:虽然 1.22B 在计算上很友好,但多层 Cross-attention 的引入在极高频率(如 >100Hz)的实时控制任务中仍有优化空间。
结语:PokeVLA 的开源不仅提供了一个强大的基座模型,更为 VLA 研究社区提供了一套“如何让 AI 真正看懂物理世界”的方法论参考。