This paper introduces the "Pricing Reversal Phenomenon" in Reasoning Language Models (RLMs), where models with lower listed API prices frequently incur higher actual inference costs. Evaluating 8 frontier RLMs (e.g., GPT-5.2, Gemini 3 Flash) across 9 tasks, the study reveals that in 21.8% of model-pair comparisons, the "cheaper" model is actually more expensive, with cost disparities reaching up to 28x.
TL;DR
In the era of Reasoning Language Models (RLMs), the sticker price on the API page is a lie. A new study from Stanford, UC Berkeley, and Microsoft Research reveals the Pricing Reversal Phenomenon: in over 20% of cases, the model you thought was cheaper actually costs more—sometimes up to 28 times more. The culprit? Thinking tokens, the hidden internal monologue that models use to "reason" before they answer.
Problem: The Mirage of Low API Pricing
For years, developers have balanced their budgets by comparing per-million-token rates. If Model A charges $3 and Model B charges $15, Model A is the winner, right?
This logic collapses with reasoning models. Unlike standard LLMs, RLMs generate a variable number of "thinking tokens" (internal Chain-of-Thought) that are billed as output but often invisible to the user. Because different models "think" with vastly different levels of verbosity, the nominal price per token no longer reflects the final bill.
Methodology: Decomposing the "Thinking" Overhead
The researchers evaluated 8 frontier models, including GPT-5.2, Gemini 3.1 Pro, and Claude Opus 4.6, across 9 rigorous benchmarks like AIME (math) and GPQA (science).
They broke down costs into three categories:
- Prompt Tokens: Your input.
- Thinking Tokens: The internal reasoning (The hidden cost driver).
- Generation Tokens: The final visible answer.
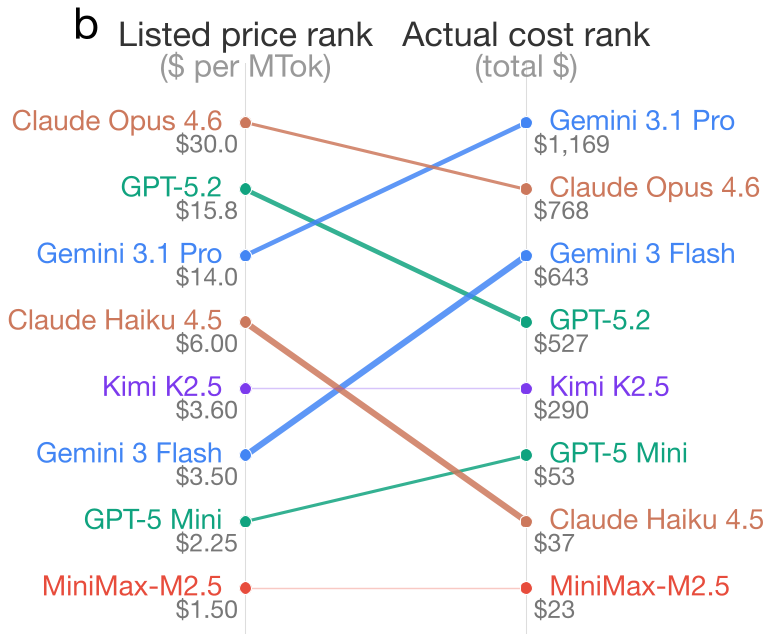
The Smoking Gun: Thinking Token Variance
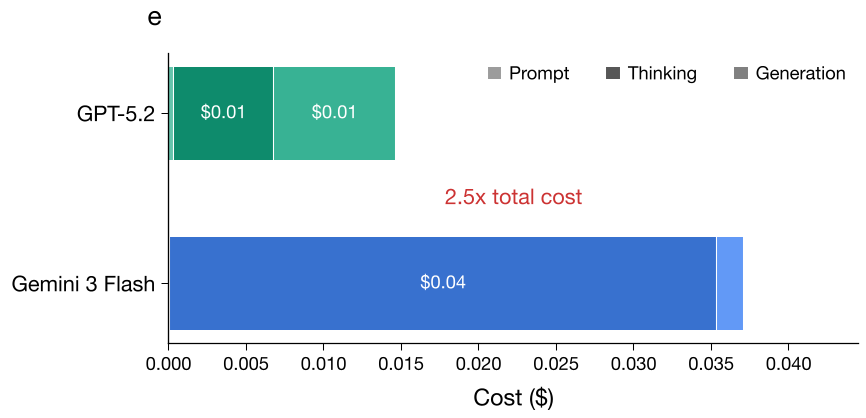
The study highlights a striking case: Gemini 3 Flash. Its listed price is 78% cheaper than GPT-5.2, yet it ended up being 22% more expensive across all tasks. Why? On a single AIME math problem, Gemini 3 Flash used over 11,000 thinking tokens, while GPT-5.2 achieved the same correct answer using only 562.
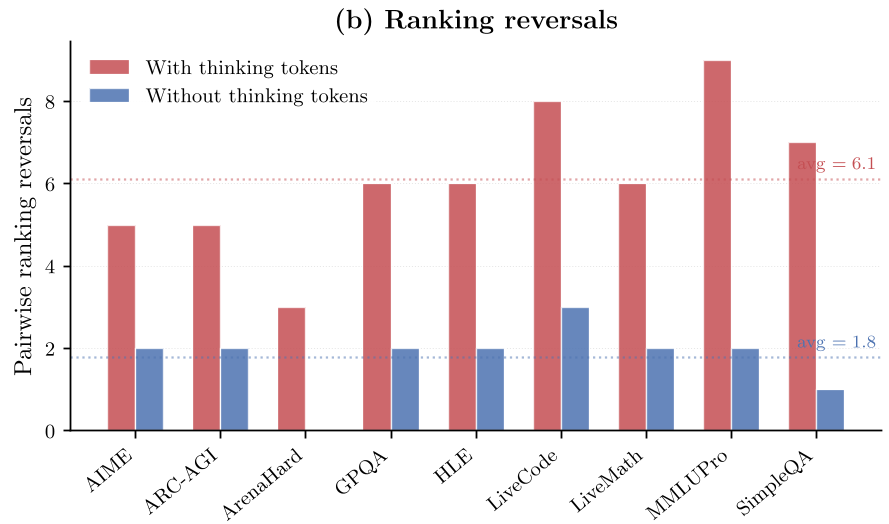
Experiments: Why Prediction is Harder than it Looks
If thinking tokens are the problem, can we just predict how many a model will use? The researchers tried using KNN (K-Nearest Neighbors) based on query embeddings and prompt-length regression to forecast costs.
The results were sobering. While semantics help slightly, they fail for high-variance reasoning models. The reason is irreducible variance: the model's "mood" fluctuates. By running the exact same query 6 times, they found that a model might use 9.7x more tokens on one run than another for the same prompt. This internal stochasticity creates a noise floor that makes fixed budgeting nearly impossible.
Critical Analysis & Takeaways
This paper exposes a fundamental shift in AI economics. Reasoning is a "black box" expense.
- For Developers: "Unit Price" is dead. You must perform workload-specific auditing. A model that is cost-effective for SimpleQA might be a budget-killer for complex coding tasks.
- For Providers: Transparency is required. Surfacing thinking token counts in real-time and providing cost-estimation APIs is the only way to retain developer trust.
- The Future: We are moving toward a world where we pay for "successful reasoning" rather than raw tokens.
Conclusion: As models get smarter, their behavior becomes more like a human expert—sometimes they find the shortcut, and sometimes they overthink the problem. In the RLM economy, efficiency of thought is just as important as the price of a token.
Source: Chen et al., "The Price Reversal Phenomenon: When Cheaper Reasoning Models End Up Costing More" (2026).