本文系统研究了推理型语言模型(RLM)中“标称价格”与“实际推理成本”之间的脱节,提出了“价格反转 (Pricing Reversal)”现象。研究涵盖 GPT-5.2, Gemini 3 Flash 等 8 款前沿模型,揭示了低单价模型在实际任务中可能因巨量思考 Token 消耗反而更贵的现象。
TL;DR
在推理模型(RLM)时代,“便宜没好货”不仅是俗语,更成了数学事实。斯坦福与 UC 伯克利等团队的最新研究发现:21.8% 的情况下,单价更低的模型实际上更贵,溢价最高可达 28 倍。罪魁祸首在于模型不可见的“思考过程” (Thinking Tokens) —— 有些模型虽然单价低,但完成同一个任务需要比竞争对手多消耗 900% 的 Token。
1. 动机:被“标价”蒙蔽的开发者
随着 OpenAI o1, Gemini 3, Claude 4 等模型的发布,大家习惯了看官网的 API 价格表来选型。
- 直觉:如果模型 A 的输入/输出单价都比模型 B 低,那模型 A 肯定更省钱。
- 现实:这种逻辑在传统 LLM 上成立,但在“思考型”模型(Reasoning Models)上彻底破产。
开发者往往忽略了推理模型的一个关键物理特性:它们在输出最终答案前,会进行大量的内部链式推理(Chain-of-Thought)。这部分 Token 是要计费的,但其数量在选型时完全是黑盒。
2. 核心现象:价格反转 (Pricing Reversal)
研究团队对比了 8 款主流推理模型在 AIME(数学)、GPQA(科学)等 9 个基准测试上的表现,重塑了我们的认知坐标:
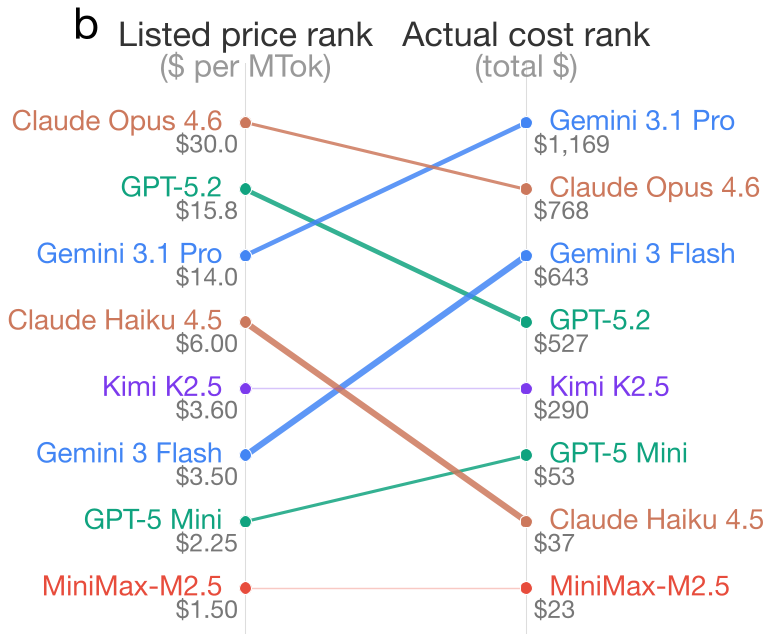
- 案例分析:Gemini 3 Flash 的标价仅为 GPT-5.2 的四分之一左右(约 15.75/MTok)。
- 反转结果:在 MMLUPro 任务中,Gemini 3 Flash 竟然成了最贵的模型。其真实支出比 GPT-5.2 还高 22%。
这种现象并非偶然,21.8% 的模型配对都出现了类似的排名倒挂。这意味着:如果你仅凭价格表选型,你有五分之一的概率选到更贵的那一个。
3. 根因深挖:Thinking Tokens 的异构性
为什么标价失灵了?作者通过公式 进行了成本分解。
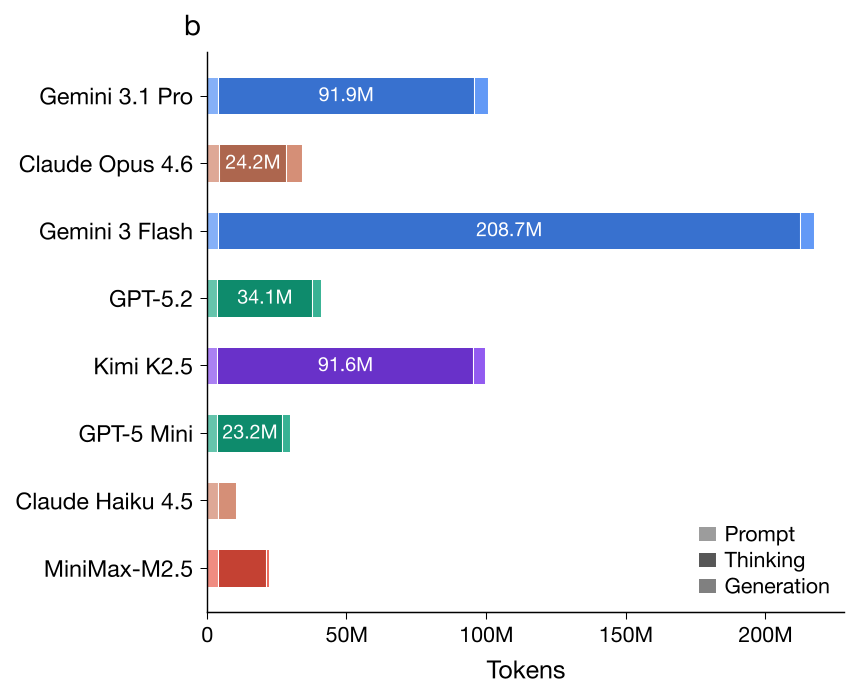
为什么会反转?
- 思考占大头:在 RLM 中,Thinking Tokens 占据了输出 Token 的绝大部分,且直接决定了最终账单。
- 效率极度不均:不同模型在处理同一个问题时,“思考效率”天差地别。
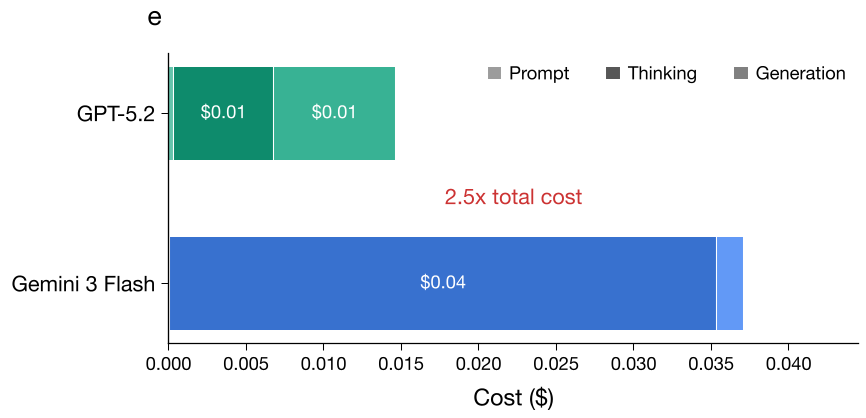
- 实战对比:面对同一道 AIME 数学题,GPT-5.2 思考了 562 个 Token 就拿到了答案;而 Gemini 3 Flash 为了完成同样的推理,疯狂消耗了 11,000+ 个 Token(见下图)。
- 结果:即使 Flash 的单价低,由于其“废话”多出 20 倍,最终成本依然反超。
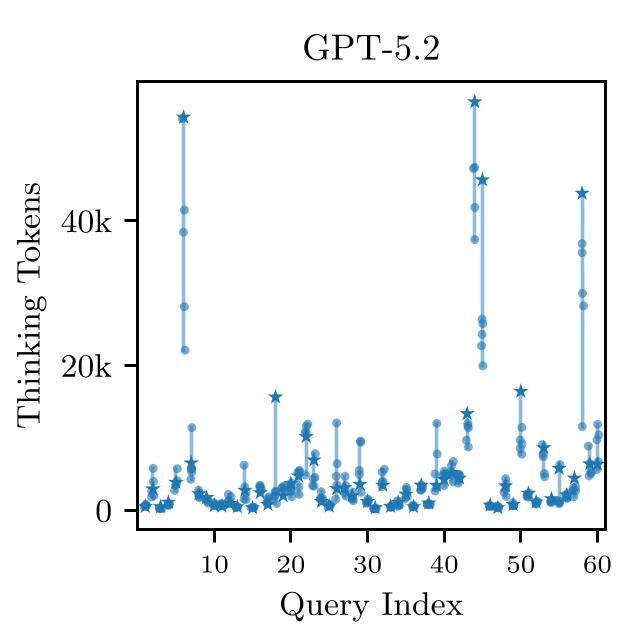
4. 预测难题:不可消除的随机噪声
既然知道了是 Thinking Tokens 在搞鬼,那我们预先预测一个 Query 会消耗多少 Token 行不行?
作者评估了线性回归、KNN 等多种预测方案,结论令人沮丧:成本预测极其困难。
- 内部随机性:研究人员对同一个 Query 重复运行 6 次,发现某些模型的 Token 消耗波动(CV)高达 0.38。
- 极端案例:同一个模型对同一道题,最贵的一次运行花费是最高的一次 9.7 倍。
- 物理直觉:推理模型的思考路径具有高度的采样随机性,这种“不可约噪声” (Irreducible Noise) 意味着即便最强的预测器也无法准确预估单次调用的费用。
5. 行业启示与总结
这篇论文是对当前 AI 成本核算体系的一次“降维打击”。
- 对开发者:不要再迷信单价。在进行模型大规模部署前,必须针对特定的 Workload 进行 Cost Auditing (成本审计),用真实数据而非标价来做决策。
- 对厂商:简单的固定单价已经不足以描述模型价值,未来可能演进为按推理深度计费,或者需要提供实时的“思考进度条”和成本预警 API。
- 结论:推理能力本质上是拿“Token 换智力”。如果一个模型的“智商增长”是以牺牲十倍的 Token 效率为代价,那么它的单价优势将毫无意义。
Takeaway:在 RLM 时代,最便宜的模型往往是那个在思考上最“干脆利落”的高单价模型。