PRL-BENCH is a comprehensive, medium-scale benchmark (100 tasks) designed to evaluate the end-to-end physics research capabilities of LLMs. It focuses on frontier subfields such as Astrophysics, HEP, and Quantum Information, requiring models to perform autonomous planning and long-horizon reasoning to reproduce results from recent Physical Review Letters papers.
TL;DR
As AI transitions from a tool to an autonomous researcher, the need for evaluation frameworks that mirror actual scientific inquiry has become critical. PRL-BENCH introduces 100 expert-level tasks derived from the prestigious journal Physical Review Letters. Unlike previous benchmarks, it requires LLMs to navigate open-ended research paths across five core physics subfields. The result? Even the world’s most advanced models fail to reach a 50% success rate, stumbling over conceptual errors and reasoning instability.
The "Agentic Science" Gap
Most current AI benchmarks like OlympiadBench or Humanity's Last Exam (HLE) are essentially advanced "homework" sets. They provide a clear problem statement and ask for a specific answer. However, real physics research is messy. It involves:
- Exploration: Choosing the correct theoretical framework without being told which one to use.
- Long-Horizon Persistence: Connecting 10+ steps of derivation and computation without losing the "thread."
- Hybrid Skillsets: Switching between symbolic math, Python coding for numerical verification, and conceptual model building.
PRL-BENCH was built to expose the gap between "solving problems" and "conducting research."
Methodology: From Paper to Benchmark
The researchers curated 100 papers from Physical Review Letters (August 2025 – March 2026). These weren't just any papers; they were specifically chosen for being theory-intensive and computation-heavy, allowing for objective verification without a physical laboratory.
The Task Anatomy
Each task is structured to prevent the LLM from simply searching for the paper text:
- Motivation: Scientific context.
- Core Task: An objective that requires multiple heterogeneous subtasks (e.g., a tensor-network simulation).
- Rubrics: Hidden checkpoints that verify if the model used the right physical intuition, not just if it arrived at a lucky number.
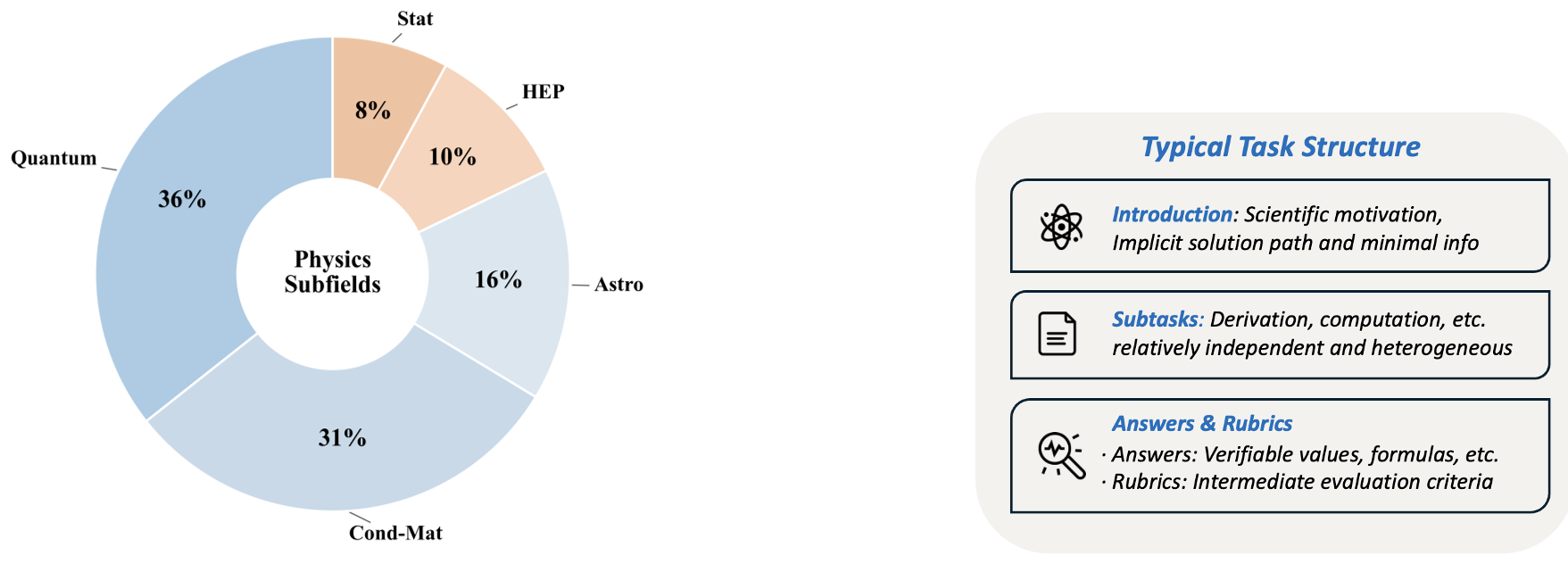 Figure 1: The workflow of PRL-BENCH, transforming frontier research into verifiable agentic tasks.
Figure 1: The workflow of PRL-BENCH, transforming frontier research into verifiable agentic tasks.
Experimental Frontiers: How do the Models Fare?
The study evaluated heavyweights like GPT-5.4, Gemini-3.1-Pro, and Claude-Opus-4.6. The findings provide a sobering look at the state of AI for Science:
- Gemini-3.1-Pro emerged as the leader (44.27/100), showing better integration of code and logic.
- Physical Intuition is the Bottleneck: Over 50% of failures were "Formulaic or Conceptual Errors." Models often grab a familiar-looking equation from a textbook that doesn't actually apply to the specific frontier problem at hand.
- The "Incompleteness" Trap: Models like Claude-Opus-4.6 often entered "self-correction loops" in long tasks, eventually failing to provide any answer at all because they lost track of the research objective.
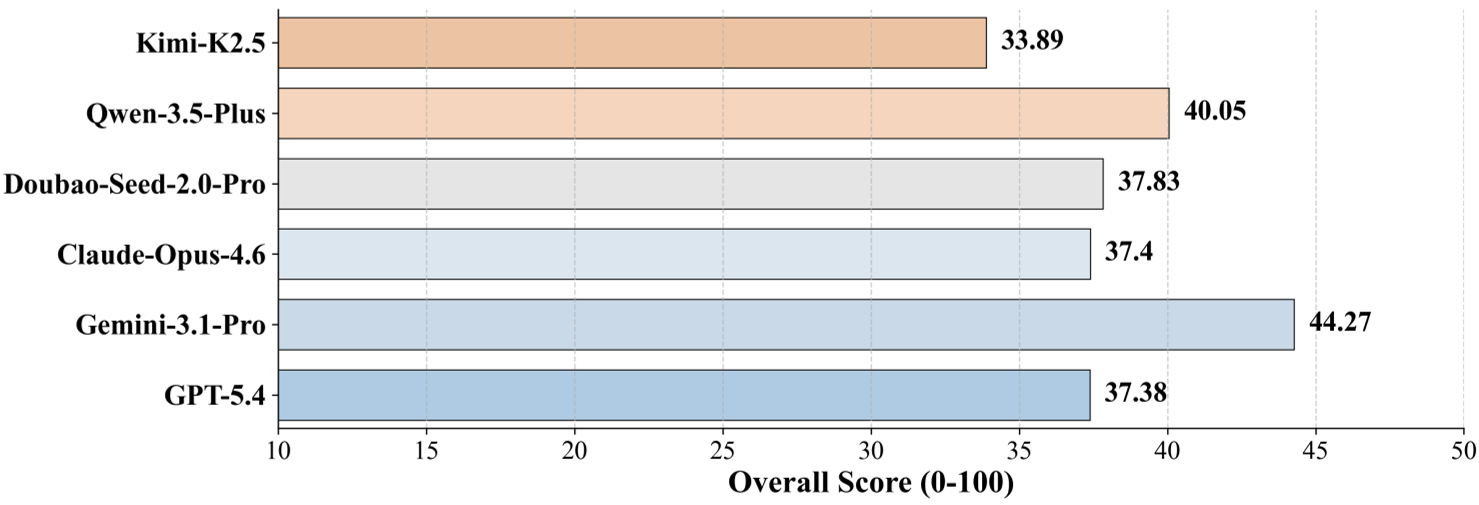 Figure 2: Performance breakdown showing Gemini and Qwen leading, but all models significantly underperforming in complex domains like Statistical Physics.
Figure 2: Performance breakdown showing Gemini and Qwen leading, but all models significantly underperforming in complex domains like Statistical Physics.
Deep Insight: Why is This So Hard?
The error decomposition (see Figure below) reveals that Derivation Error is particularly high in High-Energy Physics (HEP). This points to a fundamental weakness in LLMs: Symbolic Hallucination. When a derivation requires 20 lines of algebra, the probability of a model introducing a "spurious formula" to bridge a gap it doesn't understand becomes almost 100%.
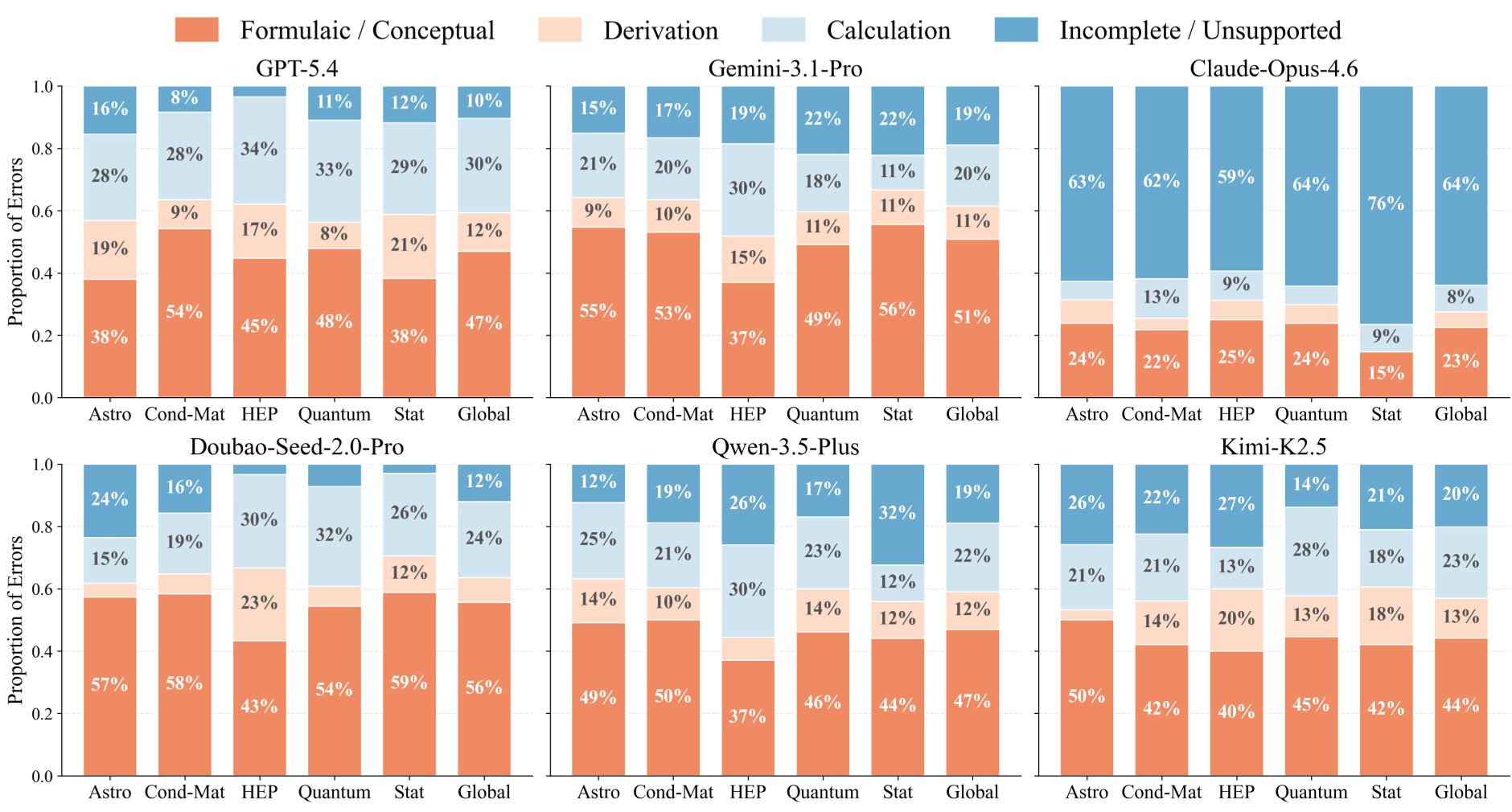 Figure 3: Breakdown of why models fail. Conceptual gaps and unstable derivations are the primary culprits.
Figure 3: Breakdown of why models fail. Conceptual gaps and unstable derivations are the primary culprits.
Conclusion & Future Outlook
PRL-BENCH proves that we are still in the "Advisory" phase of AI4Science. For an AI to become a truly autonomous "Scientist," it needs:
- Iterative Falsification: The ability to realize a hypothesis is wrong mid-derivation and backtrack.
- Deeper Domain Knowledge: Moving beyond "Standard Model" basics into the specific, nuanced effective field theories used in modern PRL papers.
The benchmark is now open-source, serving as a high-bar lighthouse for the next generation of reasoning models.