本文提出了 CoRectron,这是一种针对上下文推荐(Contextual Recommendation)任务的免投影(Projection-Free)在线学习算法。该方法通过引入二阶感知机(Second-order Perceptron)机制,在保持 对数遗憾(Regret)界的同时,显著降低了计算复杂度,并在處理非最优反馈时展现出更强的鲁棒性。
TL;DR
在上下文推荐任务中,传统的 Online Newton Step (ONS) 算法虽然能达到对数级的遗憾界,但其核心的马氏投影步骤在处理高维特征时效率极低。本文提出的 CoRectron 算法,巧妙利用了推荐决策对抗预测向量缩放的不变性,通过一种类似二阶感知机 (Second-order Perceptron) 的机制彻底移除了投影操作。结果是:单轮计算开销从 降至 ,且在反馈数据含有噪声时更具鲁棒性。
背景定位:从线性 Bandit 到上下文推荐
上下文推荐(Contextual Recommendation)是在线学习中一个独特的变体。与传统的线性 Bandit(观察标量奖励 )不同,在推荐场景下,我们观察到的是用户的行为选择(例如用户选择了哪件商品)。
- 任务定义:学习器推荐一个动作 ,而用户基于其隐藏偏好 选择一个(假设最优的)动作 。
- 核心痛点:此前的 SOTA 方法依赖于 ONS 框架,虽然理论完美,但马氏投影 (Mahalanobis Projection) 简直是高维计算的噩梦。在高维或核化(Kernelized)场景下,这种计算开销往往是不可接受的。
痛点深挖:为什么投影是可以被“干掉”的?
作者提出了一个非常深刻的直觉:Improperness (非适当性)。
在推荐任务中,我们寻找的是 。注意,如果你把预测向量 放大 10 倍,最大化的动作 是完全不变的!这意味着我们根本不需要像传统在线凸优化(OCO)那样,强行把 投影到一个有界集合内。
这种尺度无关性为我们打开了大门:既然不需要约束 的模长,那为什么还要费力去做投影呢?
方法论详解:CoRectron 机制
CoRectron 的核心逻辑非常简洁。它维护了一个累积残差向量 和一个二阶预处理器 :
- 更新规则:
- 残差定义:
- 矩阵演化:
这种更新方式与 2005 年提出的二阶感知机高度相似。通过这种设计,原本由于 越界而不得不进行的 投影操作消失了,取而代之的是简单的秩一更新(Rank-one Update)。
 表 1:CoRectron 与 ONS、LightONS 的复杂度对比,可见其在总时间复杂度上的显著优势。
表 1:CoRectron 与 ONS、LightONS 的复杂度对比,可见其在总时间复杂度上的显著优势。
实验与结果:速度与质量的双重飞跃
作者在有限维线性模型和复杂的 RBF 核模型上进行了对比。
1. 鲁棒性与超参数稳定性
实验发现,ONS 和 OGD 在超参数(正则化系数)较小时,遗憾值会迅速恶化,且计算时间激增(因为需要处理更复杂的投影)。而 CoRectron 在极广的超参数范围内保持了极低的遗憾和稳定的运行时间。
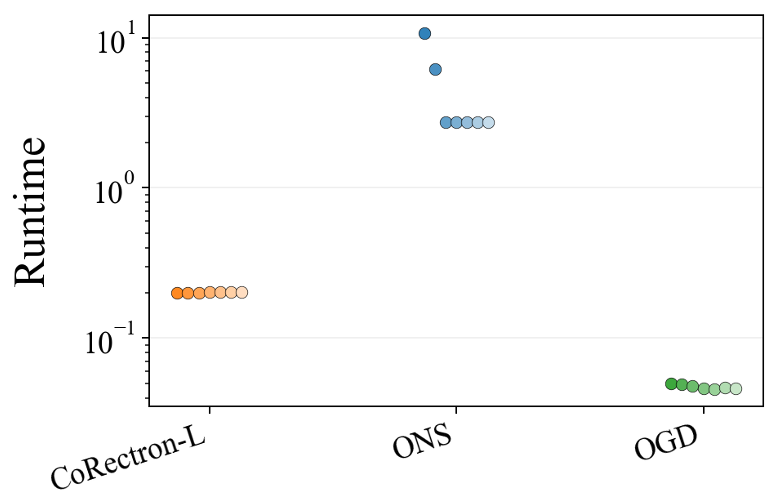 图 1:线性设置下的性能对比。CoRectron-L (深蓝色) 在遗憾值和鲁棒性上均优于 ONS。
图 1:线性设置下的性能对比。CoRectron-L (深蓝色) 在遗憾值和鲁棒性上均优于 ONS。
2. 核化挑战
在 Kernel Setting 下,投影的代价变得愈发昂贵。CoRectron-K 通过避免投影,直接规避了在高维核空间中求解复杂约束优化的问题。
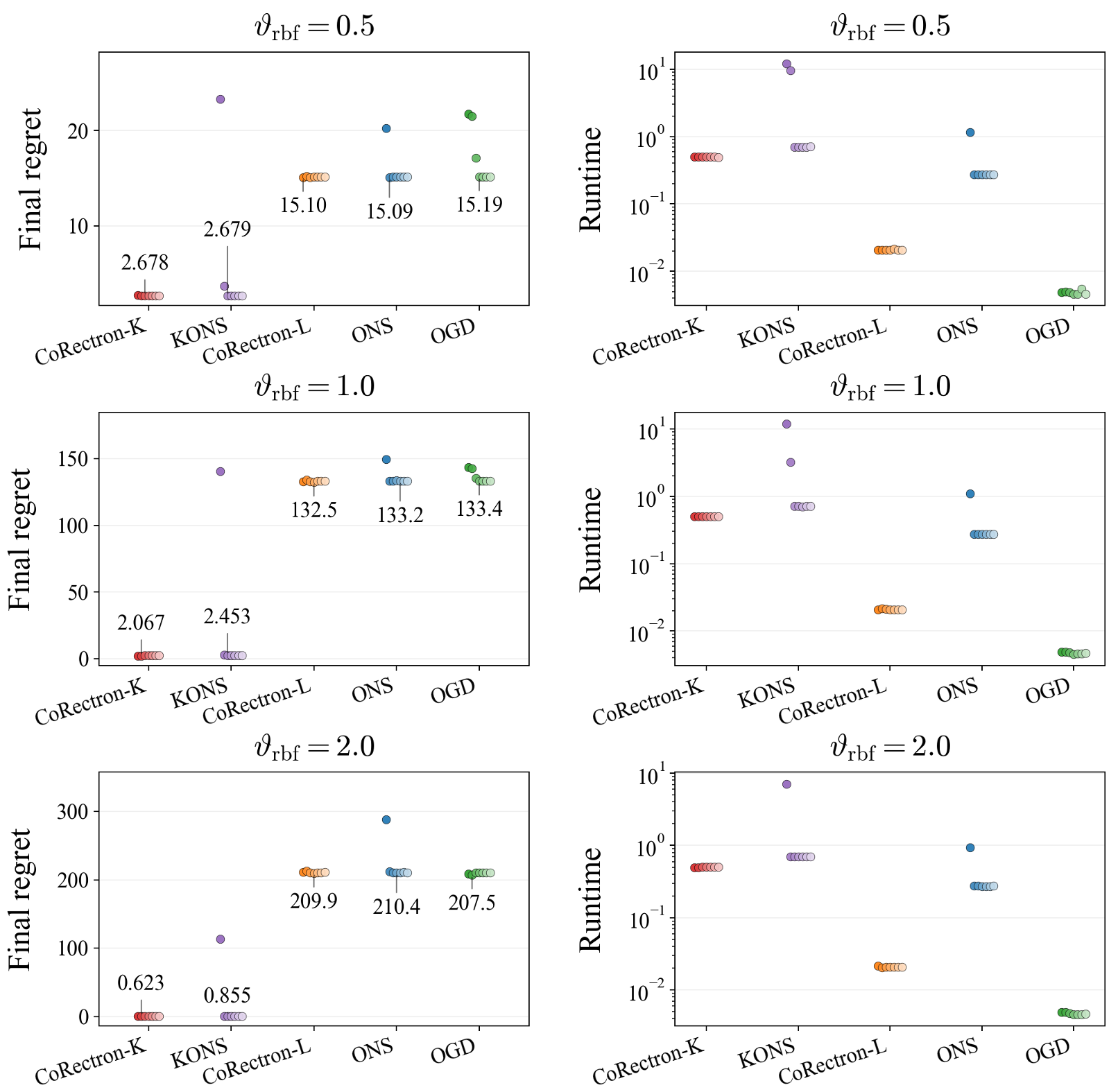 图 2:在 RBF 核设置下,CoRectron-K 不仅遗憾值更低,且运行时间保持在较低水平。
图 2:在 RBF 核设置下,CoRectron-K 不仅遗憾值更低,且运行时间保持在较低水平。
深度洞察:为什么二阶感知机在推荐中更强?
传统分类任务中,二阶感知机的错误界(Mistake Bound)往往依赖于间隔(Margin),在最坏情况下可能很大。但在上下文推荐任务中,作者通过严密的数学证明(基于椭圆势能引理 EPL),将这一界限收紧到了 。这揭示了:推荐任务的结构天然适合这种二阶更新策略。
此外,该算法在处理**亚最优反馈(Suboptimal Feedback)**时表现极其优雅。无需像 MetaGrad 那样运行几十个学习器并行寻优,单个 CoRectron 实例即可通过二阶信息的自动调节实现稳健推荐。
总结与局限
CoRectron 是一个兼具理论美感和工程实用的算法。它的出现意味着我们可以在处理复杂的逆在线优化问题时,告别昂贵的线性约束投影。
局限性:算法目前仍高度依赖于能够访问精确的线性优化算子(Linear Optimization Oracle)。在可行集极其复杂或是动作空间离散化程度极高的情况下,寻找 本身可能成为新的瓶颈。未来的研究方向可能在于如何进一步将这种免投影思路与近似 Oracle 相结合。