Prune-OPD is an efficient framework for long-horizon On-Policy Distillation (OPD) that improves reasoning models by dynamically aligning training budgets with supervision quality. By monitoring local student-teacher compatibility (top-k overlap), it truncates unreliable rollouts and down-weights "drifted" trajectories, achieving up to 68% reduction in training time while matching or exceeding SOTA reasoning performance on benchmarks like AIME and HMMT.
TL;DR
On-Policy Distillation (OPD) is the powerhouse behind recent reasoning breakthroughs, yet it is computationally expensive and prone to "reward hacking" when student models drift away from their teachers. Prune-OPD introduces a dynamic pruning mechanism that monitors student-teacher compatibility in real-time. By killing off unreliable "drifted" reasoning paths early, it slashes training time by up to 68% without sacrificing accuracy, effectively turning OPD from a fixed-budget process into a reliability-aware one.
The "Drift" Problem: When the Teacher Stops Making Sense
The core philosophy of On-Policy Distillation is to let the student model generate its own reasoning traces (on-policy) and have a stronger teacher model provide token-level feedback. This solves the "exposure bias" of off-policy methods but introduces a hidden flaw: Trajectory Drift.
In long-horizon tasks like complex math (AIME, AMC), a single wrong turn in the student's thought process makes the subsequent tokens "alien" to the teacher. If the student is already on a path the teacher would never take, the teacher's "corrections" become locally nonsensical, contributing noisy gradients and wasting expensive GPU cycles on thousands of useless tokens.
Methodology: The Physics of Compatibility
Prune-OPD moves away from fixed rollout limits and introduces three key components to enforce reliability:
1. Local Compatibility Metric
The system tracks the Top-K Overlap Ratio. At every token , it compares the top candidate tokens from both student and teacher. If this overlap falls below a threshold (), it signals a Prefix-Drift Event.
2. Monotone Reward Attenuation
Instead of a hard cutoff, Prune-OPD accumulates these drift events into a reliability weight . This weight is non-increasing, ensuring that once a trajectory becomes unreliable, we don't start trusting it again just because of a coincidental token match later.
3. Dynamic Response Budget
The framework adjusts the global max-length based on the batch's "hit ratio"—the fraction of samples that remain reliable until the end of the current window. If many rollouts are being pruned early, the system automatically shrinks the generation window to save compute.
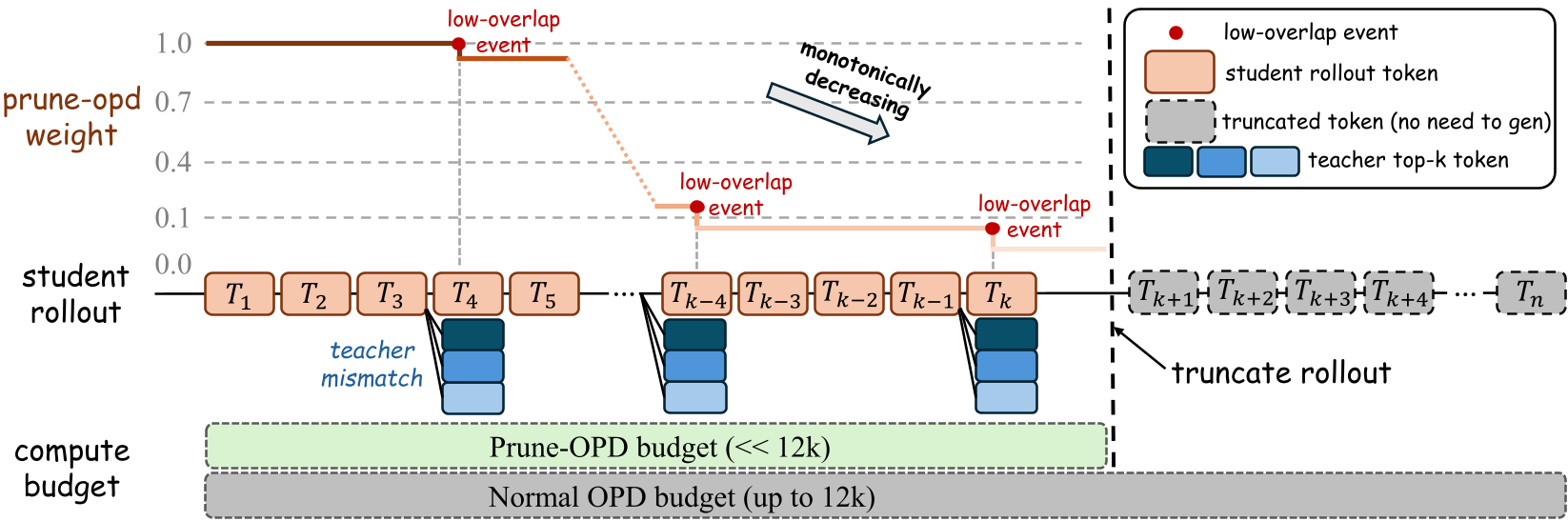 Figure 1: Conceptual overview showing how Prune-OPD monitors compatibility and triggers truncation only when supervision becomes unreliable.
Figure 1: Conceptual overview showing how Prune-OPD monitors compatibility and triggers truncation only when supervision becomes unreliable.
Experimental Validation: Efficiency Meets Accuracy
The authors tested Prune-OPD across various models (DeepSeek-R1, Qwen3). The results challenge the "more is always better" mantra of LLM training data.
Key Result 1: Massive Time Savings
When the student and teacher have low compatibility (common in "cross-family" distillation), Prune-OPD reduced wall-clock training time by 37.6% to 68.0%.
Key Result 2: Denoising for Better Accuracy
In the Qwen3-4B experiments, Prune-OPD actually outperformed the full-length baseline. By removing the long suffixes of drifted reasoning, it effectively removed gradient noise that was overwhelming the useful signals from the early, correct parts of the chain.
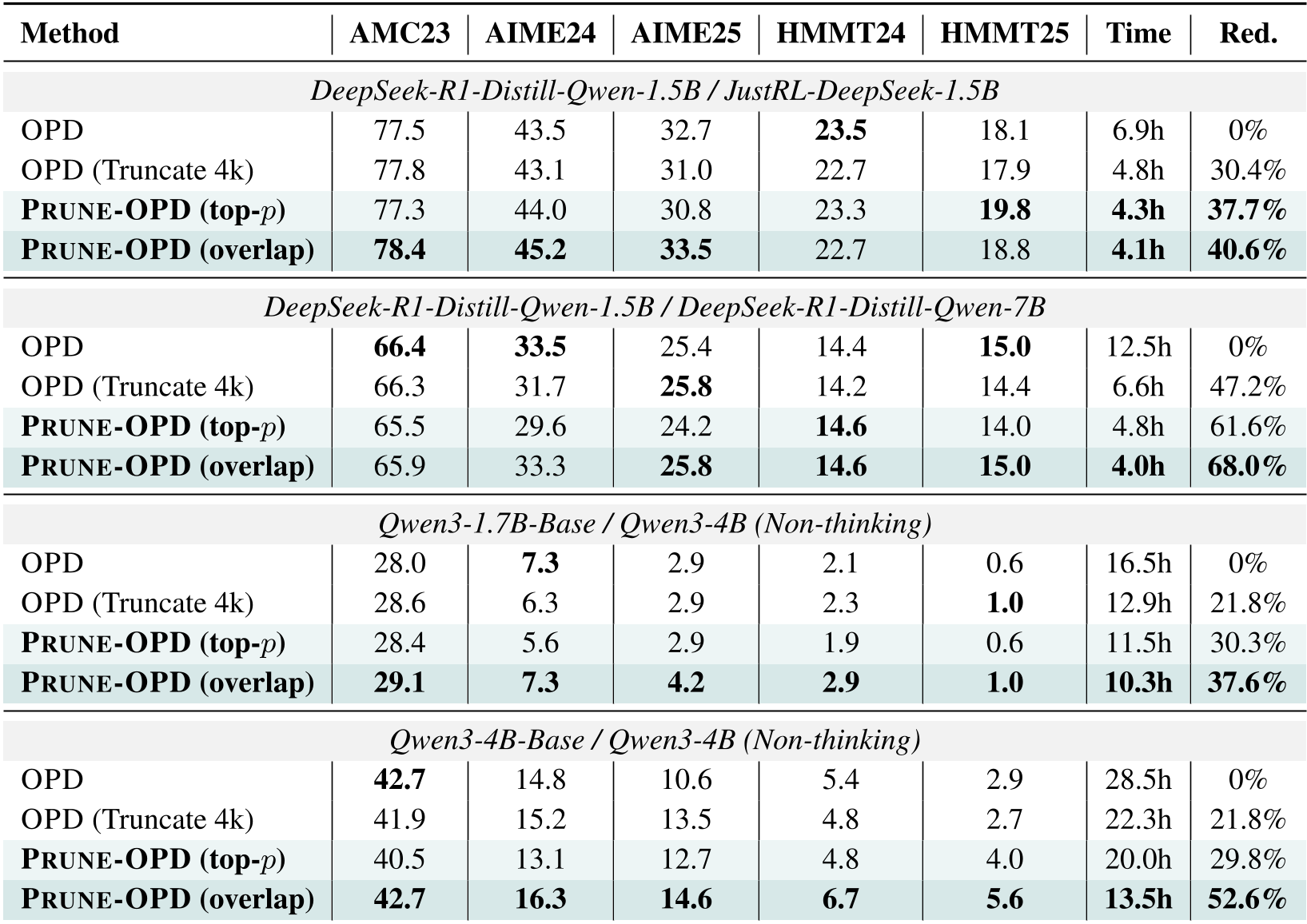 Table 1: Performance comparison across DeepSeek and Qwen pairs, highlighting significant time reduction with stable or improved benchmark scores.
Table 1: Performance comparison across DeepSeek and Qwen pairs, highlighting significant time reduction with stable or improved benchmark scores.
Key Result 3: Smart Adaptation
Importantly, Prune-OPD isn't just a "shortener." When the student and teacher are highly compatible (e.g., DeepSeek-R1-7B and Skywork-OR1-7B), the system automatically expands the window to 12k+ tokens, preserving high-quality long-context supervision.
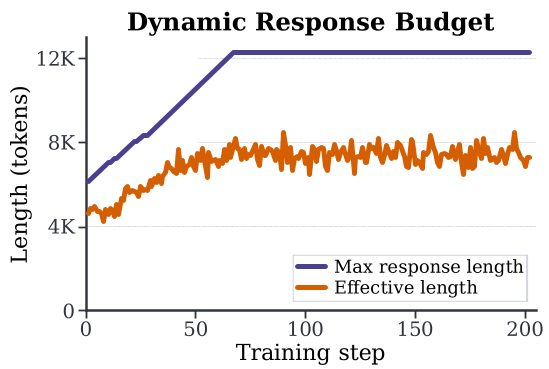 Figure 2: In high-compatibility settings, the effective length (left) stays high, ensuring long-context reasoning is not lost.
Figure 2: In high-compatibility settings, the effective length (left) stays high, ensuring long-context reasoning is not lost.
Critical Insight & Future Outlook
The most striking takeaway from Prune-OPD is its role as a gradient denoiser. In the world of reasoning RL, we often focus on the quantity of generation. Prune-OPD suggests that Trajectory Quality over Depth is the better heuristic.
Future Directions:
- Hybrid Objective: The authors suggest a future "gate" where the model switches from OPD (distillation) to GRPO (pure RL based on final answer) the moment the teacher becomes unreliable. This would allow the student to continue exploring even after drifting from the teacher's path.
- Broader Applicability: While tested on math, this reliability-aware pruning is a prime candidate for distilling agentic behaviors, where long "thought-action" sequences are notoriously prone to early divergence.
Conclusion
Prune-OPD proves that for complex reasoning, the "teacher's word" is only law as long as the student is on a path the teacher understands. By acknowledging this boundary, we can train reasoning models that are not only smarter but also significantly cheaper to build.