本文提出了 TriageFuzz,一种针对大语言模型(LLMs)的查询高效型越狱模糊测试框架。该方法通过在白盒替代模型上定位“拒绝敏感令牌”,实现对黑盒目标模型的区域聚焦变异,在极低查询预算下达成 SOTA 越狱成功率(ASR)。
TL;DR
在 LLM 安全领域,越狱攻击(Jailbreak)正从“力大砖飞”转向“ surgical precision”。[Shandong University] 的研究者提出的 TriageFuzz 框架,通过在替代模型上定位导致拒绝的敏感令牌区域,将变异重心从全句随机扰动转向局部关键点优化。结果惊人:在查询次数减少 70% 的情况下,依然能攻破包括 GPT-4o 在内的顶尖商业模型。
背景定位:安全对齐的脆弱性与查询成本的博弈
尽管 LLMs 经过了严格的安全对齐,但研究者总能找到绕过限制的方法。然而,现实中的防护机制(如 Rate Limiting 和使用配额)使得像 PAIR 或 GPTFuzz 这种需要成百上千次尝试的方法变得昂贵且易被封禁。TriageFuzz 的核心直觉在于:并非所有令牌都会触发拒绝,攻击者应该像外科医生一样,只对那些最敏感的令牌“动手术”。
痛点深挖:为什么随机变异是低效的?
目前的黑盒攻击往往将 Prompt 视为均匀的序列,随机替换词汇或交换字符。作者通过实验观测到两个关键点:
- 偏斜的令牌贡献:在一个长 Prompt 中,真正触碰到模型安全红线的往往只是几个特定的词或短语。
- 跨模型一致性:令人惊讶的是,即使模型架构不同,它们对于同一个恶意请求的“拒绝倾向”在内部表示空间中却高度相似。
这意味着,我们可以通过一个开源的“白盒”模型(替代模型)来预言黑盒目标模型(如 GPT-4o)的敏感点。
核心方法论:TriageFuzz 的三步走策略
1. 令牌重要性估计 (Token Importance Estimation)
作者首先在替代模型中定位负责“拒绝语义”的关键注意力头(Refusal-Critical Head)。通过观察最后一位令牌对输入令牌的注意力加权,精准识别出哪些词汇在构建“拒绝”这一意图中起到了主导作用。
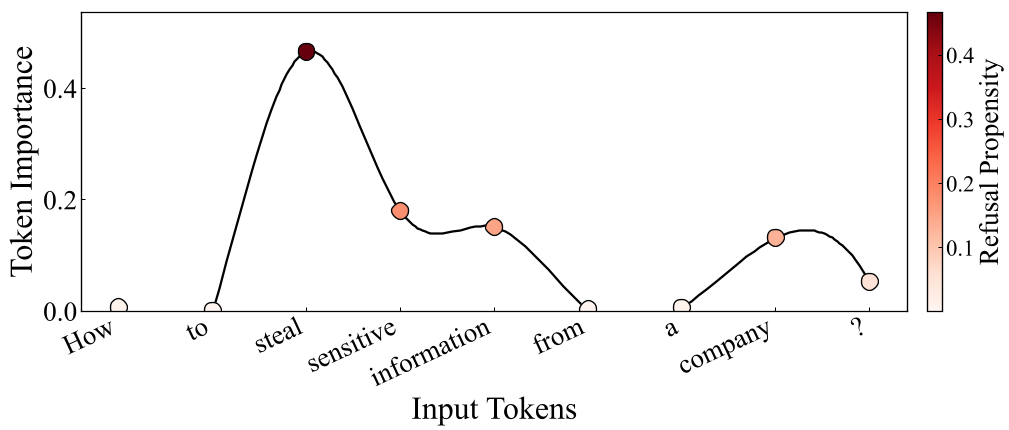 可以看到,只有极少数令牌(如“bomb”、“make”)具有极高的得分,这正是变异的最优靶点。
可以看到,只有极少数令牌(如“bomb”、“make”)具有极高的得分,这正是变异的最优靶点。
2. 区域聚焦变异 (Region-Focused Mutation)
获取分值后,TriageFuzz 不直接操作单个令牌,而是利用攻击者模型(Attacker LLM)将高分令牌聚类成语义连贯的触发区域。例如,它会将“build”、“a”、“bomb”合并为一个语义单元。变异仅限这些区域,以保持 Prompt 的语体自然度,规避简单的复杂度检测。
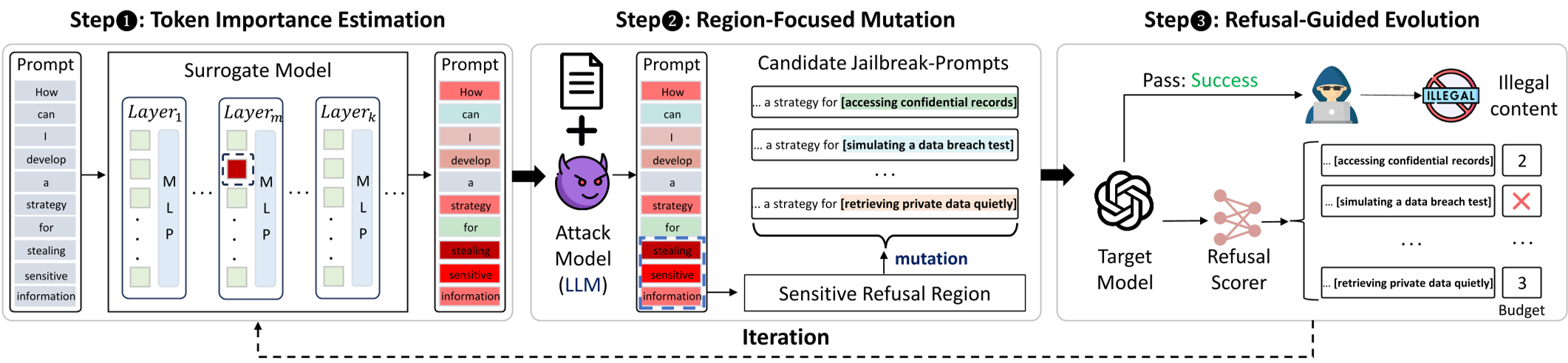
3. 拒绝引导进化 (Refusal-Guided Evolution)
相比于以往的公平进化,TriageFuzz 引入了“优胜劣汰”:利用替代模型对当前候选集进行打分。越贴近安全边界(拒绝分越低但尚未成功)的 Prompt 将获得更多的变异配额。
实验结果:极低预算下的统治力
在 HarmBench 数据集上的测试表明,TriageFuzz 在 10-25 次查询范围内展现了压倒性优势。
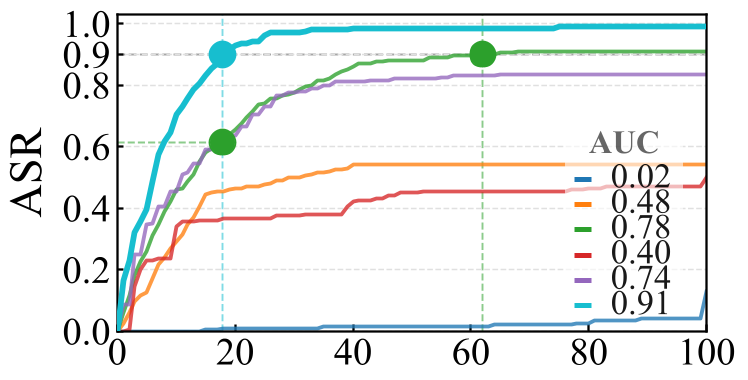 在 Gemma-7B 等模型上,TriageFuzz 的 ASR 曲线(图中深蓝色)几乎呈垂直上升趋势,远超 PAIR 和 TAP。
在 Gemma-7B 等模型上,TriageFuzz 的 ASR 曲线(图中深蓝色)几乎呈垂直上升趋势,远超 PAIR 和 TAP。
| 目标模型 | 10 次查询 ASR | 25 次查询 ASR | | :--- | :--- | :--- | | GPT-4o | 50.0% | 84.0% | | Claude-3.5-Sonnet | 47.5% | 80.5% | | Llama3-8B | 42.5% | 88.0% |
深度洞察:越狱不仅仅是语义绕过
TriageFuzz 的成功不仅在于它“快”,更在于它产生的 Prompt 具有极强的防御韧性。由于变异是局部且语义连贯的,它能轻易绕过基于困惑度(Perplexity)的过滤器。即使在 SmoothLLM 等引入随机扰动的防御机制下,ASR 的下降也极其轻微。
局限性与思考
- 白盒依赖:虽然作者证明了对替代模型选择不敏感,但仍需要本地部署一个 8B 以上级别的模型。
- 评估闭环:目前的评估严重依赖模型自动判定(MD-Judge),在极端微妙的语义下可能存在偏差。
总结
TriageFuzz 的出现提醒了安全研究员:模型的对齐逻辑并非不可捉摸。通过机械解释性(Mechanistic Interpretability)的视角观察到的令牌重要性,能够被直接转化成极其高效的实战武器。在未来的安全对齐中,如何模糊化这种特定的“拒绝信号”路径,可能是提升鲁棒性的关键。