QUITOBENCH is a billion-scale, regime-balanced open benchmark for time series forecasting, built from the single-provenance Alipay "QUITO" corpus. It categorizes series into eight "Trend × Seasonality × Forecastability" (TSF) regimes to evaluate models based on intrinsic data properties, achieving a new SOTA evaluation standard for both deep learning and foundation models.
TL;DR
The time series forecasting field is facing an "evaluation crisis" due to data leakage and skewed benchmarks. QUITOBENCH introduces a massive, contamination-free dataset from Alipay, shifting the focus from application-domain labels (like "Finance" or "Traffic") to intrinsic statistical TSF Regimes (Trend, Seasonality, Forecastability). The results challenge the "bigger is better" dogma, showing that 1M-parameter models can beat 200M-parameter giants in specific settings.
The Problem: The "Traffic" Trap
In traditional benchmarks like GIFT-Eval or Timer, datasets are grouped by domain. However, a "traffic" series can be a smooth diurnal curve or a chaotic burst of events. This coarse grouping hides the real drivers of forecasting difficulty. Furthermore, existing benchmarks are often imbalanced, where 76% of the data might fall into a single "easy" category, allowing models to "rank-squat" without truly being robust.
Methodology: The TSF Taxonomy
To solve this, the authors propose the TSF Regime. Every series is analyzed for:
- Trend (T): Long-term drift (via STL decomposition).
- Seasonality (S): Periodic patterns (via STL decomposition).
- Forecastability (F): Signal regularity (1 - Normalized Spectral Entropy).
By binarizing these (High/Low), they create 8 distinct cells (e.g., HIGH_LOW_LOW is the "pathological" regime with high drift but high noise). QUITOBENCH ensures a near-uniform distribution across these cells, forcing models to prove their mettle across all conditions.

Key Insight 1: The Context-Length Crossover
One of the most profound findings is that the "winner" changes with the amount of history provided.
- At Short Context (L=96): Deep Learning models (like CrossFormer) dominate, fitting local dependencies with high precision.
- At Long Context (L≥576): Foundation Models (Chronos-2, TimesFM) take the lead. Their pre-trained "world model" of time series allows them to exploit recurring motifs and long-term seasonality that smaller models miss.
Key Insight 2: Parameter Efficiency is Not Dead
Despite the hype around 200M+ parameter foundation models, the paper shows an "Efficiency Frontier." Deep leaning models with ~1M parameters (like CrossFormer) are 59x more parameter-efficient, often matching or surpassing the MAE of foundation models.
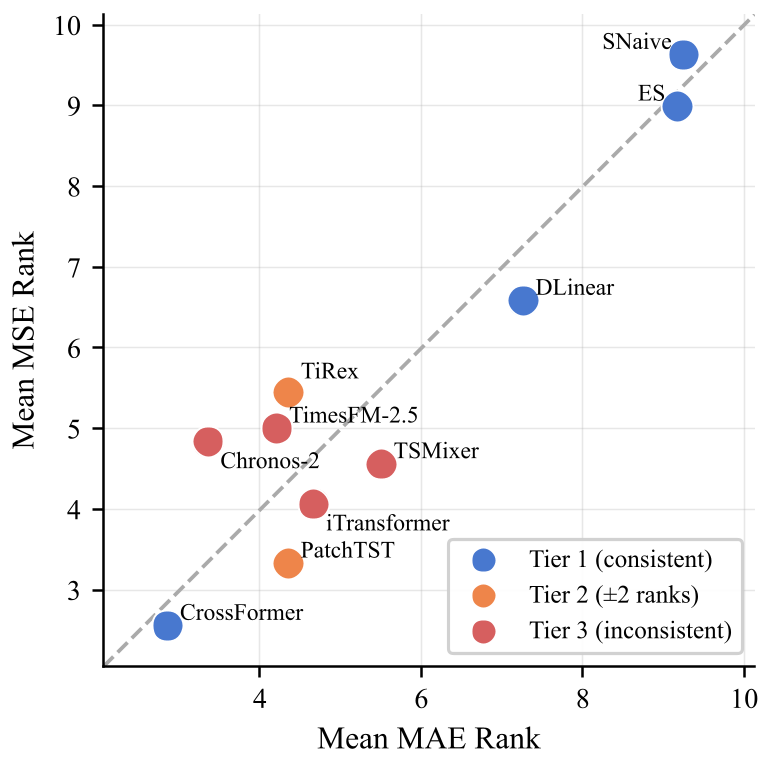
Experiments and Results
Across 232,200 evaluation instances, CrossFormer emerged as the overall champion in MAE and Rank. However, the HIGH_LOW_LOW regime remains a "stress test" where all current models fail significantly—3.64x worse performance than the easiest regime. This indicates that while we have made progress in seasonal data, "turbulent" trend-dominated noise is still an open frontier.
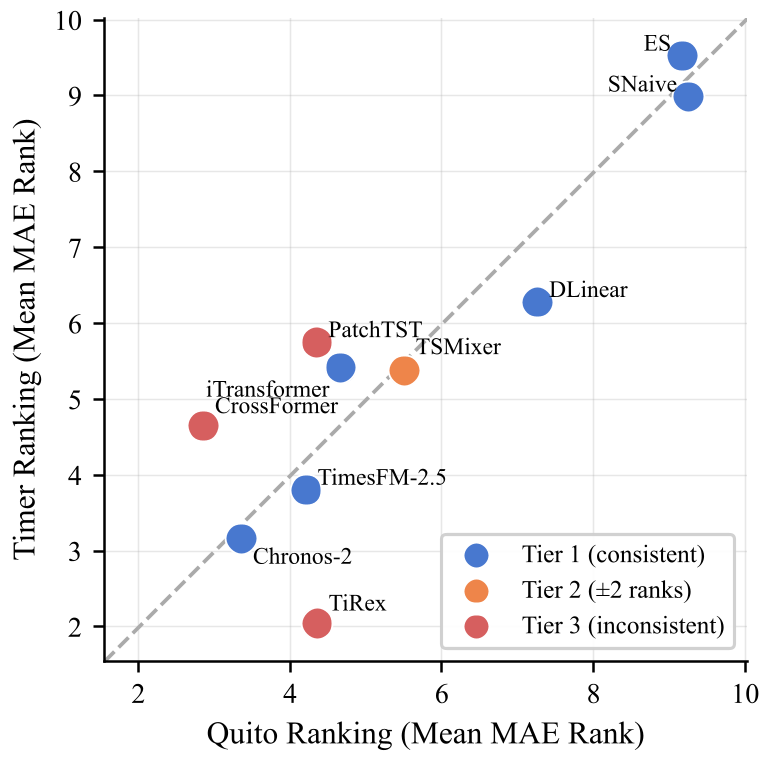
Critical Analysis & Conclusion
QUITOBENCH proves that single-provenance data (from one large platform like Alipay) can actually be more diverse than a collection of public datasets if sampled correctly across TSF regimes.
Takeaway for Practitioners:
- Don't just scale the model: Scaling the training data tokens is far more effective than increasing parameter counts.
- Context Matters: If your system only provides short historical windows, stick to optimized Deep Learning models like CrossFormer or PatchTST. If you have years of historical data, Foundation Models will finally earn their keep.
Limitations: The data is currently anonymized for commercial sensitivity, and while it covers 9 verticals, it may still reflect the specific "gravity" of a massive fintech ecosystem.
Future work will likely look at probabilistic forecasting and integrating these TSF-aware models into automated CloudOps pipelines.