Qwen3.5-Omni 是一款全模态(Omni-modality)大型语言模型,采用 Thinker-Talker 架构并扩展至千亿参数级,支持 256k 超长上下文。该模型在语音对话、视频推理及实时交互方面取得 SOTA 成就,Qwen3.5-Omni-Plus 在多项音频理解任务上超越了 Gemini-3.1 Pro。
TL;DR
阿里 Qwen 团队发布的 Qwen3.5-Omni 标志着全模态大模型进入了“超长上下文+极低延迟”的新阶段。它不仅能听、能说、能看,更通过 Hybrid MoE 架构和 ARIA 对齐技术,实现了长达 10 小时音频理解和 400 秒视频实时推理。最令人惊艳的是其突现能力——Audio-Visual Vibe Coding,即直接根据视频/音频氛围生成可执行代码。
1. 痛点:为什么“原生全模态”这么难?
在 Qwen3.5-Omni 出现之前,多数多模态模型只是简单的“缝合”:一个预训练好的 Vision Encoder 挂载到 LLM 上。这种做法在处理实时流式交互(Streaming Interaction)时会暴露两个致命问题:
- 效率陷阱:Transformer 的二次方复杂度使得处理超长视频流极其昂贵。
- 对齐偏差:文本 Token 和语音 Token 的生成速率不一致,导致模型在“边说边想”时容易出现吞字、幻觉或语流中断。
2. 核心架构:Thinker 与 Talker 的高效协同
Qwen3.5-Omni 延续并升华了 Thinker-Talker 架构,将任务一分为二:
- Thinker (大脑):负责理解。它通过 Hybrid MoE Transformer 处理文本、图像和 400s 的 720P 视频。值得注意的是,它引入了带有显式时间戳(Formatted Text String)的音视频补丁,极大增强了长视频的时间跨度感知。
- Talker (声带):负责表达。它基于 Thinker 的隐藏层状态,利用多码本(Multi-codebook)技术实现帧级别的语音合成。
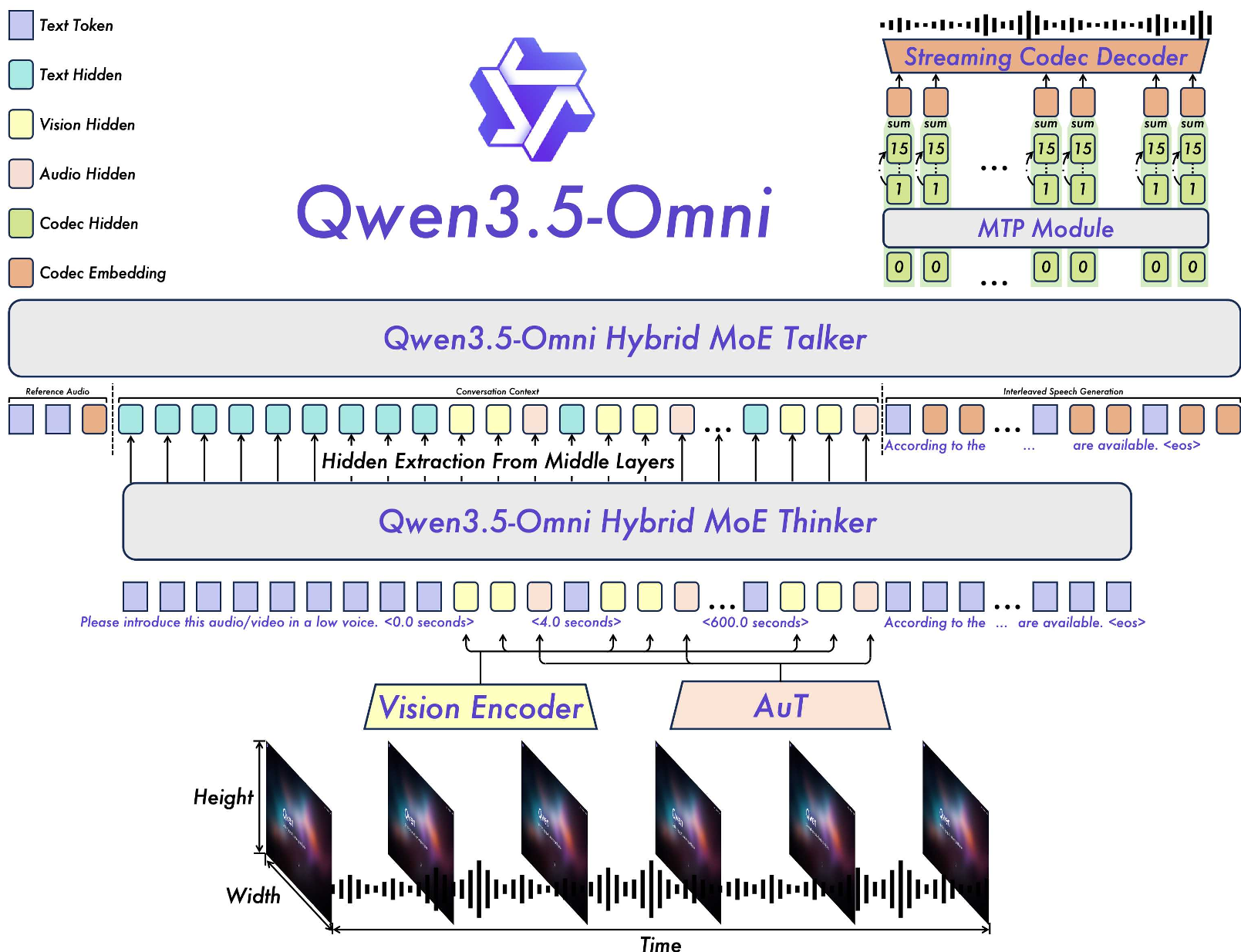 图 1:Qwen3.5-Omni 架构概览,展示了 Thinker 与 Talker 如何通过 ARIA 技术进行流式协作。
图 1:Qwen3.5-Omni 架构概览,展示了 Thinker 与 Talker 如何通过 ARIA 技术进行流式协作。
3. 技术突破:ARIA 动态对齐
为了解决语音生成的稳定性,作者提出了 ARIA (Adaptive Rate Interleave Alignment)。 物理直觉:不同语言的编码效率不同(比如中文一个 Token 代表的信息量通常大于英文)。ARIA 不再使用固定的步长对齐,而是通过一种自适应速率约束,动态确定每一时刻应该生成多少语音 Token。这种设计让模型在多语言环境下也能保持极高的韵律感和表情张力。
4. 实验战绩:超越 Gemini-3.1 Pro
实验结果显示,Qwen3.5-Omni-Plus 在音频理解领域已经稳居世界第一梯队。
- ASR 性能:在 FLEURS 榜单上,它的平均 WER 仅为 6.6%,超越了主流商业接口 GPT-4o 和 Gemini 系列。
- 交互延迟:对于开发者而言,最重要的数据是延迟。在 vLLM 加速下,Flash 版本的首包延迟仅需 235ms,这意味着人类几乎感受不到任何响应间隔。
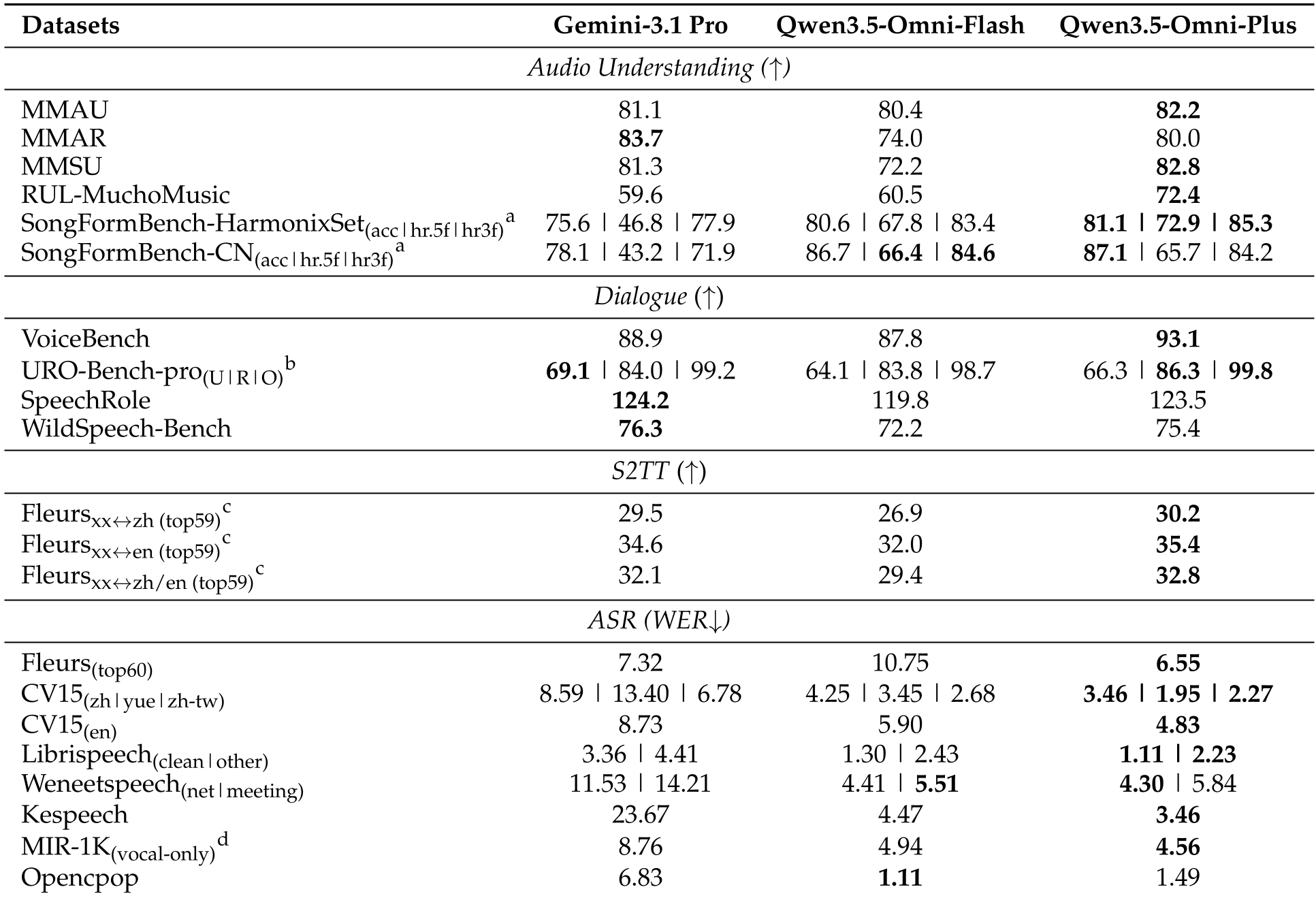 图 2:在音频理解(Audio Understanding)任务中,Qwen3.5-Omni 与 Gemini-3.1 Pro 的对比,显示了其在音乐表达和复杂场景理解上的优势。
图 2:在音频理解(Audio Understanding)任务中,Qwen3.5-Omni 与 Gemini-3.1 Pro 的对比,显示了其在音乐表达和复杂场景理解上的优势。
5. 深度洞察:零样本语音克隆与 Vibe Coding
Qwen3.5-Omni 展现了两项极具产品价值的能力:
- Zero-shot Voice Cloning:只需用户提供一段音频样本,模型就能在无需微调的情况下以该音色进行 29 种语言的对话。
- Audio-Visual Vibe Coding:这是一个极具前瞻性的发现。模型现在可以感知视频中的“氛围”(Vibe),比如给模型看一段复古游戏的视频,它能直接写出符合该风格的像素风渲染代码。
6. 总结与未来
Qwen3.5-Omni 不仅仅是在刷榜单,它通过 ARIA 和 Hybrid MoE 解决了一个核心工业痛点:如何在超长上下文下保持极低延迟的交互? 虽然目前在复杂医学推理等垂直领域仍有提升空间,但它无疑为未来的“实时 AI 助理”和“具身智能大脑”设定了新的 Benchmark。
关键词:Qwen3.5-Omni, MoE, ARIA, 实时交互, 256k Context, 语音克隆.