本文提出了基于编排轨迹(Orchestration Traces)的 LLM 多智能体系统(MAS)强化学习框架,将复杂的智能体交互建模为包含生成、委派、通信和聚合事件的时间图。核心贡献是系统化地梳理了编排轨迹中的奖赏设计、信用分配及学习机制,并揭示了学术方法与 Kimi, Codex 等工业级系统之间的规模鸿沟。
TL;DR
传统的单智能体 Trajectory(轨迹)思维已经无法满足日益复杂的 LLM 团队协作需求。本文提出,LLM-MAS(多智能体系统)的强化学习应当围绕 Orchestration Trace(编排轨迹) 展开。这不仅是一个术语的改变,更标志着研究重点从“优化模型预测”向“优化团队决策过程”的范式转移。
核心速览
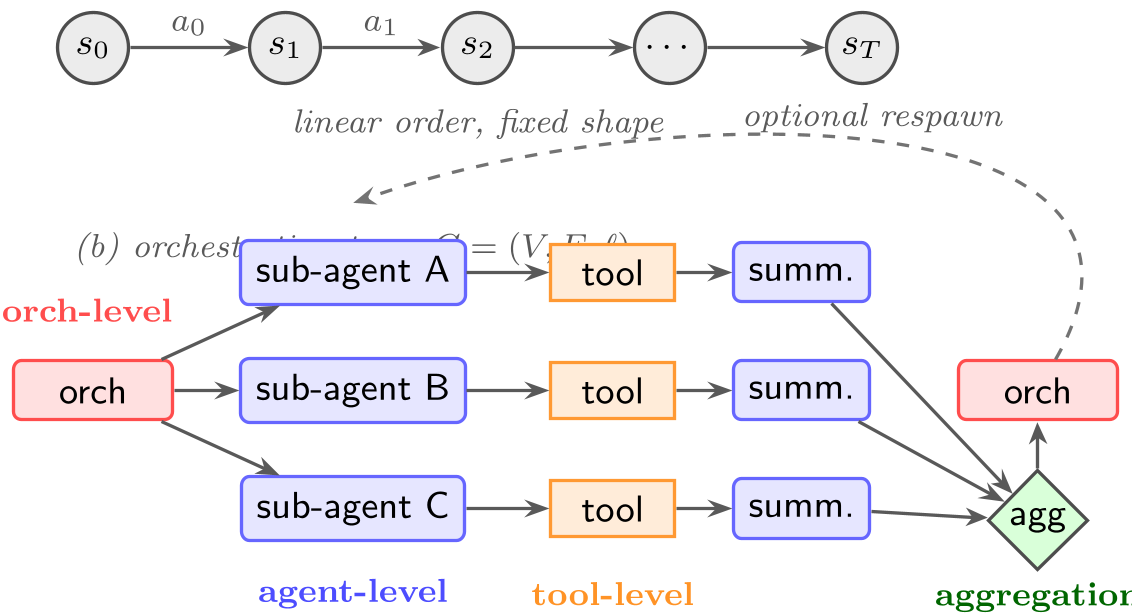
当前 LLM 智能体正从孤立的工具使用者向协同团队演进。本文通过引入 Orchestration Trace 这一抽象,将复杂的交互抽象为包含节点(生成、委派、消息、工具、聚合、停止)和边(因果、依赖)的时间图。这篇文章的核心价值在于为学术界和工业界建立了桥梁,明确了在 credit diffusion(信用扩散)和 dynamic-spawn(动态生成)背景下的技术坐标系。
痛点深挖:为什么 Classical MARL 不够用了?
传统的 MARL(多智能体强化学习)假设 Agent 数量固定、动作空间离散且通信受限。但在 LLM-MAS 场景下:
- 动作空间是自然语言:VDN 的加法分解或 MADDPG 的连续控制假设在此失效。
- Agent 数量动态变化:如同 Kimi 所展示的,编排器可以随时 Spawn 100 个子 Agent,这种 Dynamic-Dec-POMDP 特性传统方法极难处理。
- 信用分配的“黑洞”:在长达数千步的协作中,如果只有一个最终的成功/失败反馈(Shared Reward),如何判断是第 50 步的那个子 Agent 消息起到了关键驱动作用?
方法论详解:编排轨迹的解构
作者将编排决策拆解为 5 类核心动作(O1-O5):
- 何时生成 (O1):基于任务复杂度决定是否需要分身。
- 向谁委派 (O2):在动态 Agent 池中选出最优执行者。
- 如何通信 (O3):控制消息的冗余度和信息密度。
- 如何聚合 (O4):将碎片化结果合并为有效状态。
- 何时停止 (O5):在成本与精度之间寻找博弈平衡点(目前学术界在 O5 上的研究几乎为零)。
在信用分配上,论文提出了一个从 Team 到 Token 的 8 层级结构。为了解决长轨迹下的梯度不稳定性,Agent-wise Normalization(由 Dr. MAS 提出)和 Counterfactual Message Credit(由 C3 提出)成为了突破口。
实验与结果:工业界的领先与学术界的短板
文章对比了学术界方法与 Kimi (Moonshot AI)、Codex (OpenAI)、Claude Code (Anthropic) 的表现。
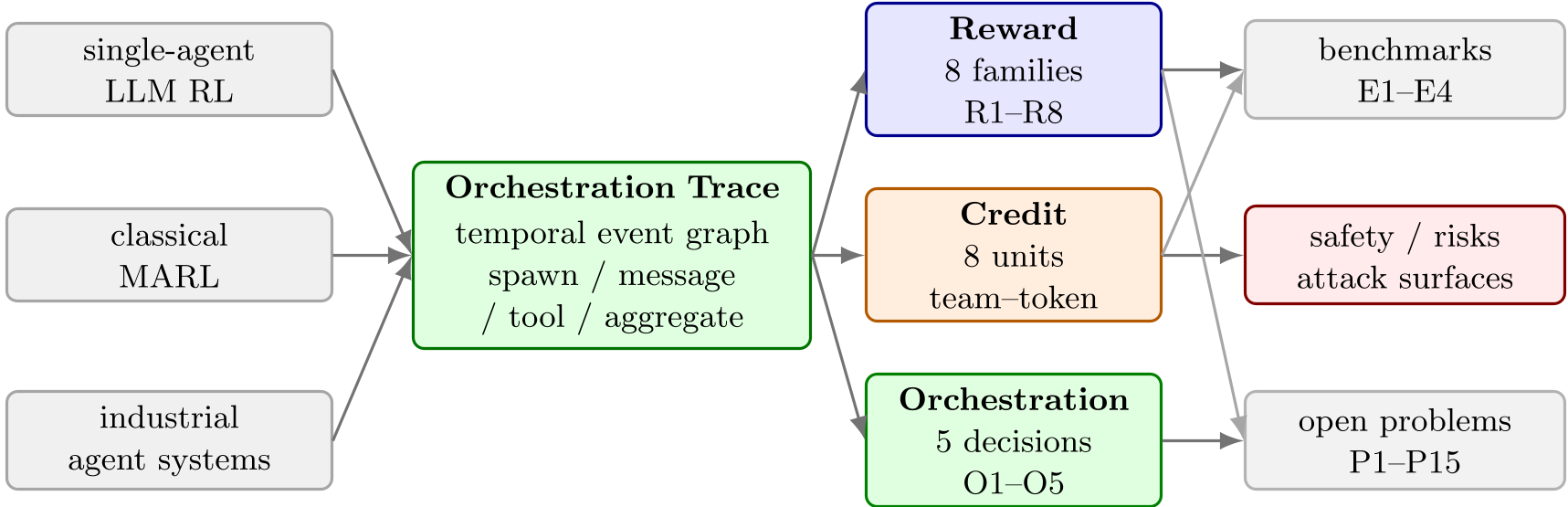
- 规模鸿沟:Kimi K2.5 已经能处理 1500 个协调步骤,而大部分学术论文的实验仍停留在 100 步以内。
- 协同增益:简单的 Shared Reward 会导致“搭便车”现象(Lazy Agent)。通过引入角色特定奖赏(R3),MALT 正确率提升了 14.14%。
- 编排稳定性:Dr. MAS 通过对 GRPO 算法进行 Agent 级别的归一化,解决了多智能体训练中的梯度爆炸/崩塌。
深度洞察:未来的 15 个开放性问题
作者极具前瞻性地指出了 15 个待解决的方向,其中最紧迫的是:
- MAS-native Benchmarks:我们需要能衡量“并行效率(Parallelism Efficiency)”和“错误放大率(Error Amplification)”的测试集,而不是单纯看 Accuracy。
- 可引导性(Steerability):当 Agent 团队在运行中走偏时,人类如何介入编排轨迹?
- 动态 Shapley 值:如何在 Agent 成员不断变动的情况下公平分配信用?
总结
多智能体协作的本质是信息增量的有效编排。这篇文章告诉我们,未来的 AI 训练将不再仅仅是让模型“说对话”,而是让它学会像一个优秀的 CTO 那样,高效地管理一个庞大的 Agent 团队。
注:本文基于 2026 年最新 arXiv 论文综述撰写,所有术语保留英文原文以确保学术严谨性。