The paper introduces Relax Forcing, a novel training-free inference strategy for long video generation in Autoregressive (AR) Diffusion models. By replacing dense historical conditioning with a structured, sparse Relaxed KV-Memory mechanism, it achieves SOTA results on VBench-Long, particularly improving motion dynamics.
TL;DR
More memory doesn't always mean better videos. Relax Forcing reveals that dense historical context in autoregressive video diffusion models actually stifles motion and accumulates errors. By adopting a structured sparse memory—categorizing frames into Sinks, Tails, and Selected History—this training-free method boosts motion dynamics by 66.8% and speeds up inference by 26%.
Background: The Limits of "More Context"
Autoregressive (AR) video diffusion has becoming the standard for minute-scale video generation. Theoretically, these models can generate infinite frames by sliding a window and conditioning on previous results. However, in practice, they hit a "temporal wall": videos either drift into semantic nonsense or become "frozen" with zero motion.
The standard academic response has been to increase memory capacity. But this paper provides a counter-intuitive insight: Dense historical conditioning is a bottleneck. Too much past information makes the model "stiff," trapping it in the past and preventing natural motion evolution.
The "Functional Roles" Insight
The authors conducted a systematic study and discovered that temporal memory should be treated as a heterogeneous buffer. They identified three distinct roles:
- Sink (Global Anchors): The very first frames provide long-term identity and scene stability.
- Tail (Short-term Continuity): The most recent frames ensure the next frame doesn't have "glitches."
- History (Mid-range Structure): Middle frames provide the "momentum" for motion but are prone to being redundant.
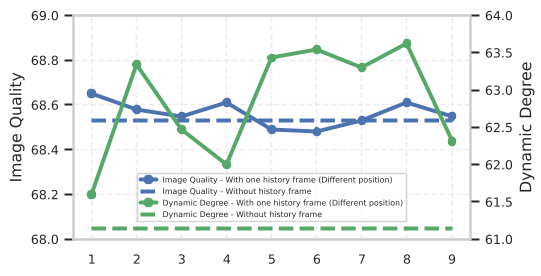 Figure: Analysis showing that increasing memory size (Sink, History, or Tail) leads to non-monotonic performance, often hurting motion dynamics.
Figure: Analysis showing that increasing memory size (Sink, History, or Tail) leads to non-monotonic performance, often hurting motion dynamics.
Methodology: Relaxed KV Memory
Based on this insight, the authors proposed Relaxed KV Memory. Instead of feeding the whole buffer into the Transformer, they "relax" the conditioning set:
- Decomposed Selection: It keeps fixed Sinks and Tails but dynamically picks the best mid-range History frame.
- Relaxation Scoring: To pick the best history frame, it uses a score: $r(h) = ext{Stability}(h) - \lambda \cdot ext{Redundancy}(h)$. It wants frames that are consistent with the "Sink" (global) but different from the "Tail" (local) to avoid repetition.
- Hybrid RoPE: Since the memory is now non-contiguous (gaps in time), they use a specialized Rotary Positional Embedding to maintain relative temporal distances without confusing the model.
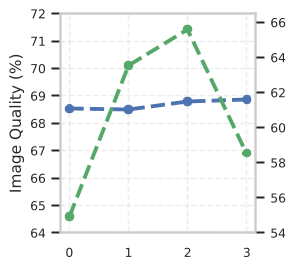 Figure: The Relaxed KV Memory architecture decomposing history into specific roles.
Figure: The Relaxed KV Memory architecture decomposing history into specific roles.
Experiments & Results: Efficiency meets Quality
The results on VBench-Long are striking. In 60-second generation tasks, Relax Forcing maintains high quality while competitors often collapse.
- Dynamic Degree: A massive +66.8% improvement. The videos actually move like real videos rather than static photos with slight wiggling.
- Inference Speed: Because it attends to only 7 frames instead of 21+ frames, the self-attention calculation is 2.64x faster, leading to a total 26% speedup in end-to-end generation.
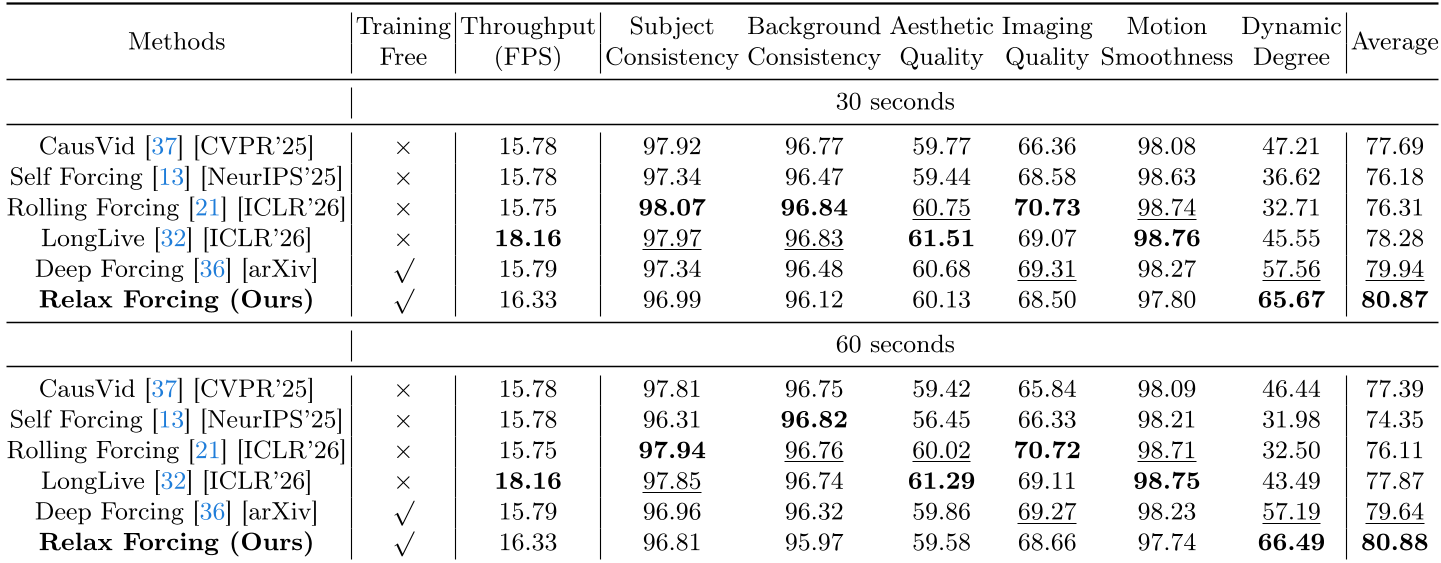 Table: Quantitative comparison showing Relax Forcing outperforming training-heavy baselines.
Table: Quantitative comparison showing Relax Forcing outperforming training-heavy baselines.
Critical Insight & Conclusion
Relax Forcing proves that the "memory bottleneck" in AI isn't just about hardware capacity—it's about information filtering. By treating the KV cache as a structured database where different "records" (frames) have different "keys" (roles), we can generate longer, more stable, and more dynamic content with less compute.
Limitations: While training-free, the method relies on the base model (Self-Forcing) having a decent understanding of temporal anchors. If the base model is too weak, the "Relaxation Score" might select noisy frames.
Future Outlook: This approach paves the way for "Streaming Video Transformers" that could potentially generate hour-long content by intelligently managing which "memories" to keep and which to let go.