RepoZero is the first verifiable and scalable benchmark for evaluating Large Language Models (LLMs) in generating entire software repositories from scratch. It utilizes a novel "repository reproduction" task with cross-language constraints (e.g., Py2JS, C2Rust) and an automated execution-based verification pipeline to achieve SOTA-level rigorous evaluation.
Executive Summary
TL;DR: While LLMs have become proficient at writing individual functions, can they architect a whole software repository from scratch? RepoZero introduces a rigorous, execution-based benchmark to answer this. By forcing models to reimplement existing Python/C++ libraries in JavaScript/Rust and verifying them against a "gold standard" source oracle, it exposes a massive gap in current AI capabilities.
Positioning: This work moves the goalposts from simple code completion to Autonomous Software Engineering. It sits at the intersection of benchmarking and test-time scaling, proving that the next leap in AI coding won't come just from bigger models, but from better self-verification loops.
Problem & Motivation: The "Vibe Coding" Trap
Current code benchmarks suffer from two fatal flaws:
- Subjectivity: Many rely on "LLM-as-a-judge," where one model guesses if another model's code "looks" right. This lacks the binary rigour of actual software engineering.
- Data Leakage: Since models are trained on GitHub, they might "remember" a solution rather than "reason" through it.
The authors argue that the only way to truly test an agent is to see if it can build a system that behaves exactly like a reference implementation, but in a different language to prevent rote memorization.
Methodology: The ACE Framework and Source Oracle
The core innovation is Repository Reproduction. Instead of a vague prompt like "make a web scraper," RepoZero gives the agent the API signatures of a known library and says "make this library in a different language so it passes these tests."
The Oracle Advantage
Because the authors use existing, functional repositories as the "source," they have a Source Oracle. They can generate thousands of inputs, run them through the original code to get the ground truth, and then use those exact pairs to check the agent's work.
Agentic Code-Test Evolution (ACE)
To solve these hard tasks, they propose the ACE workflow:
- Initial Synthesis: The agent writes the repo.
- Test Generation: A testing agent creates edge cases.
- Oracle Verification: The source repo provides the correct answers.
- Iterative Refinement: The agent uses execution errors to fix its code.
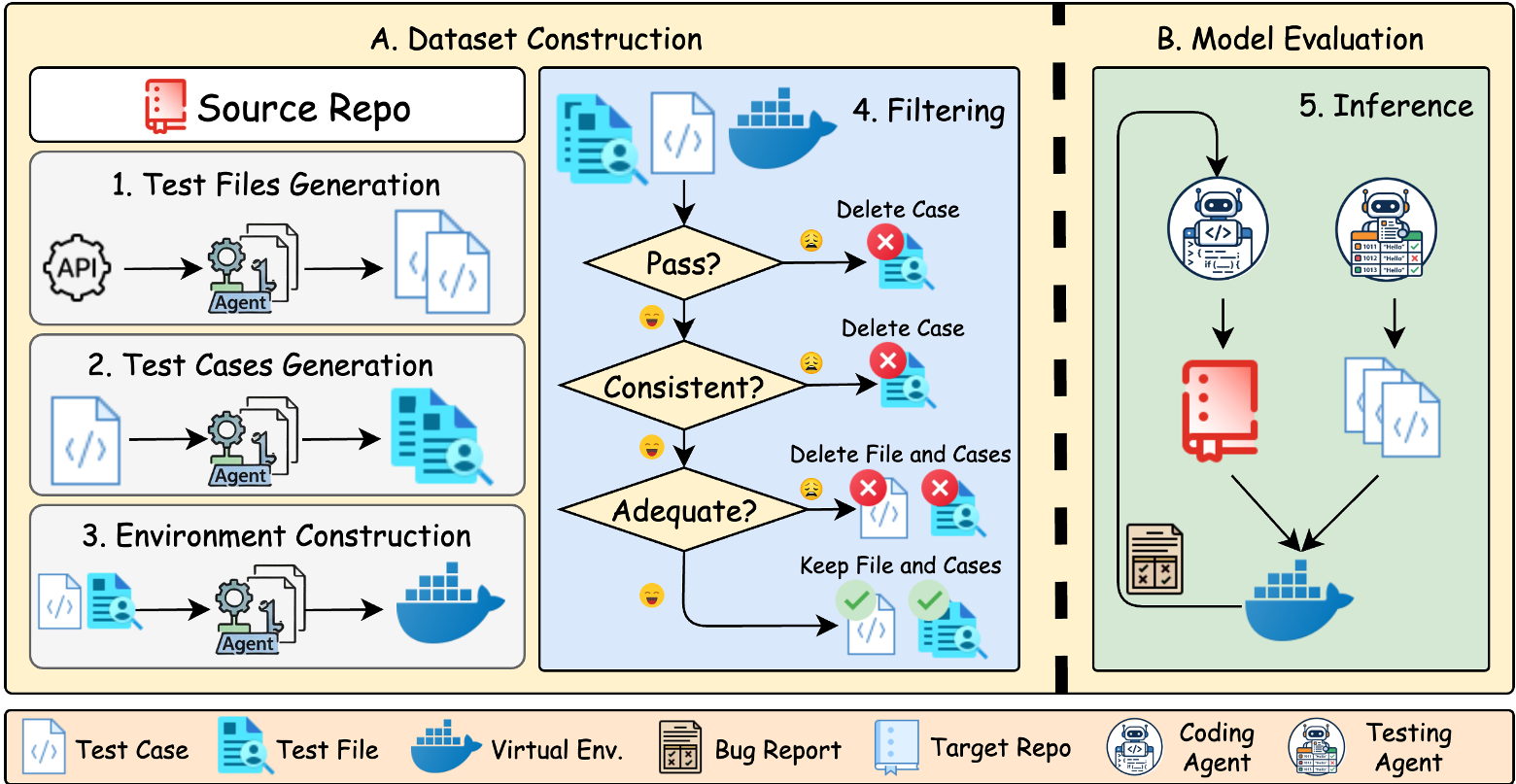 Figure 1: The RepoZero construction pipeline and the iterative ACE feedback loop.
Figure 1: The RepoZero construction pipeline and the iterative ACE feedback loop.
Experiments & Results: A Reality Check
The results are a sobering reminder of LLM limitations. Even with powerful scaffolds like Mini-SWE-Agent, most models fail to reach a 60% success rate on "Easy" tasks, and many plummet to below 20% on "Hard" repositories.
Key Findings:
- Claude-4.6-Sonnet leads the pack, but even its average performance hovers around 50%.
- The Runnability Gap: Models often produce code that runs but is semantically wrong (wrong logic, wrong math precision). About 40% of executable code failed the strict output matching.
- Contextual Drift: Agents often forget initial constraints as the project grows larger—a sign that long-context management is still a bottleneck.
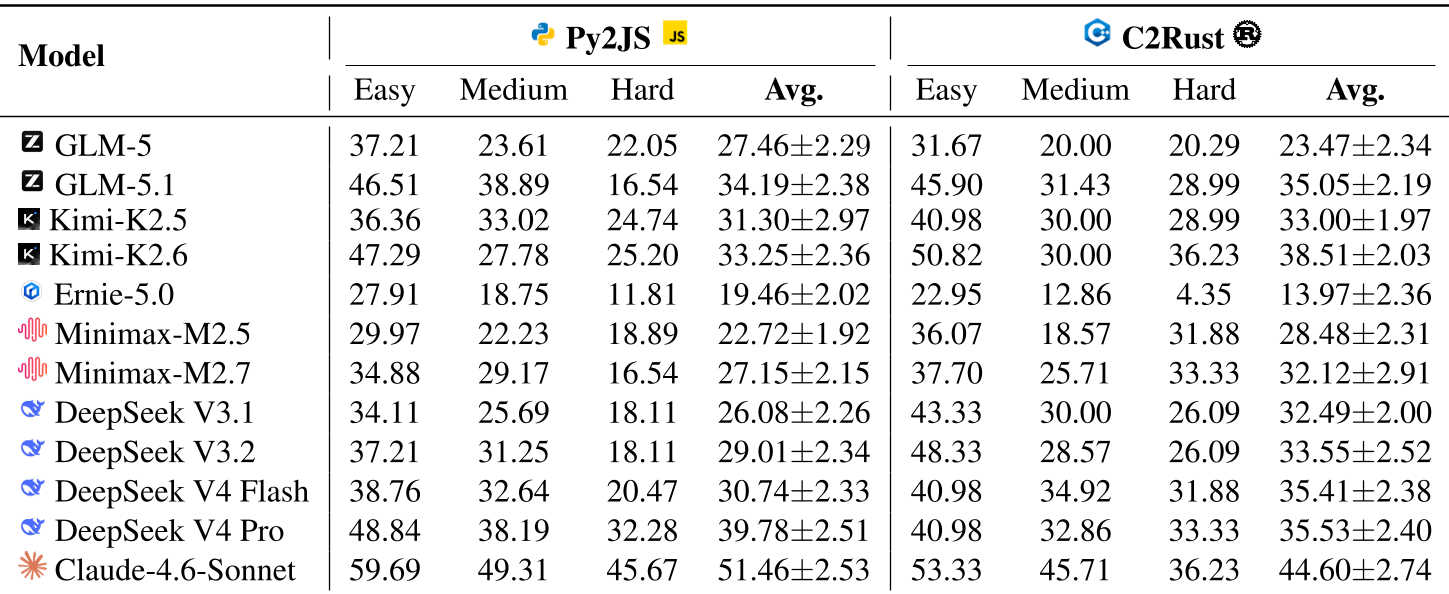 Table 1: Performance across different models and difficulty levels. Claude-4.6 remains the SOTA baseline.
Table 1: Performance across different models and difficulty levels. Claude-4.6 remains the SOTA baseline.
Critical Analysis & Conclusion
Takeaway: RepoZero successfully shifts the focus from "writing code" to "verifying logic." The success of the ACE framework suggests that test-time scaling—the ability of an agent to think and test before finalizing—is the most promising path toward autonomous development.
Limitations:
- The benchmark is currently "semi-synthetic," meaning it uses existing repos rather than entirely new real-world requirements.
- It focuses on deterministic libraries (math, data structures); non-deterministic systems (like UI or concurrent networking) remain a challenge for this verification style.
Future Outlook: We are entering the era of Agentic Engineering, where the value of an LLM isn't its first draft, but its ability to debug itself into a perfect solution. RepoZero provides the first rigorous measuring stick for that evolution.