The paper introduces a "fixed-budget" benchmark to evaluate how input representation choices—quantization, temporal encoding, and vocabulary semantics—affect generative medical event models. Using MIMIC-IV data and a one-epoch training constraint, the authors demonstrate that "fusing" medical codes with their numeric values significantly improves downstream clinical predictions, achieving SOTA-level performance in mortality and intervention forecasting.
TL;DR
In the world of generative medical AI, we often obsess over model size and data volume. This paper pivots back to the basics: Input Representation. By benchmarking 28 matched Transformers on MIMIC-IV data, the researchers found that simple changes in how we tokenize numeric values and time can spike performance more effectively than adding complexity. Their top recommendation? Fuse your codes with your values.
The "Plumbing" Problem in Clinical AI
Generative medical event models learn by predicting the "next token" in a patient's history. But if a potassium value of 6.5 (critically high) is lumped into the same token as a 5.0 (normal) due to poor binning, the model never sees the danger. This precision lost during tokenization creates an invisible ceiling that no amount of extra training can break.
The authors argue that tokenization is usually treated as "fixed plumbing." They set out to isolate these representation decisions—granularity, time encoding, and vocabulary standards—under a strict one-epoch "fixed-budget" benchmark to see what actually moves the needle.
Methodology: The Three Axis Sweep
The study systematically breaks down the input layer into three experimental axes:
- Quantization & Fusion: Should a blood pressure reading be two tokens (Code: SBP, Value: Q7) or one fused token (SBP_Q7)? How many "bins" (deciles vs. centiles) do we need?
- Encoding Mechanics: Testing "Soft Discretization" (interpolating between bins) and "xVal" (scaling tokens by numeric magnitude) against traditional discrete bins.
- Vocabulary Semantics: Does remapping messy native hospital codes to a clean, standardized format like CLIF (Common Longitudinal ICU Format) help or hurt?
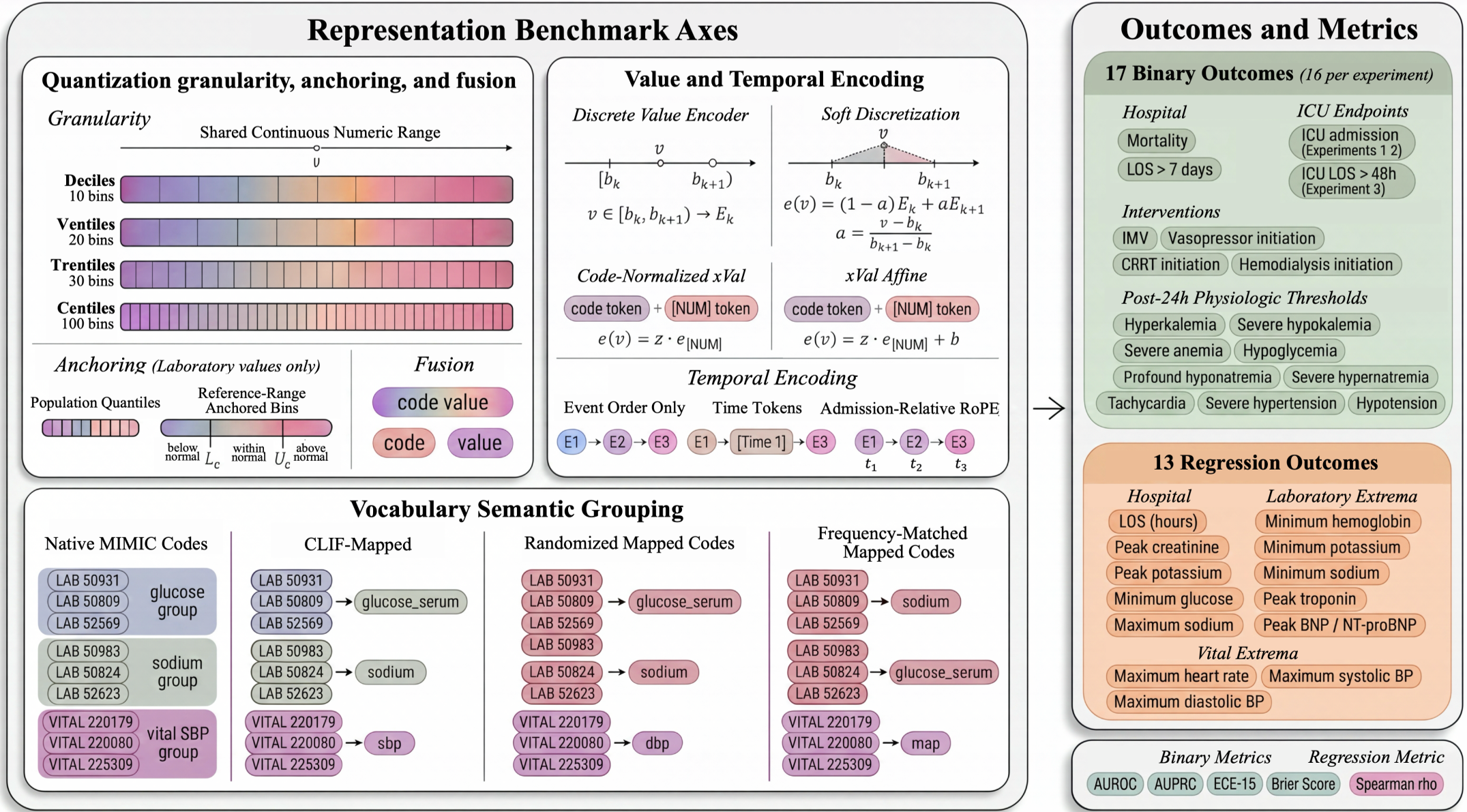 Figure 1: The benchmark evaluates 30 clinical outcomes, from mortality to electrolyte extremes, across these three representation axes.
Figure 1: The benchmark evaluates 30 clinical outcomes, from mortality to electrolyte extremes, across these three representation axes.
Key Insight 1: Fusion is the "Free Lunch"
The single most impactful finding was that fusing code and value tokens consistently outperformed separate tokens. In "unfused" models, a Q7 token for Potassium and a Q7 for Heart Rate share the same embedding, forcing the model to "re-learn" what Q7 means in every context. Fusing them (e.g., Potassium_Q7) creates "Local Binding," drastically improving the model's ability to capture clinical nuance.
- Result: Mortality AUROC jumped from 0.891 to 0.915 just by switching to fused tokens.
Key Insight 2: The Granularity Paradox
You might think more bins (e.g., 100 centiles vs. 10 deciles) would always be better. Paradoxically, the benchmark showed deciles were the sweet spot.
- Why? Finer bins fracture the data. If you have 100 bins for an infrequent test, some bins might never see a single example during one epoch of training, leading to "undertrained" embedding slots.
Key Insight 3: Time is better represented by "RoPE" or Order
Traditional models often insert explicit [TIME] tokens to show gaps between events. However, the authors found that removing these tokens and using admission-relative RoPE (Rotary Position Embeddings) or even just simple event order worked just as well.
- The Benefit: Omitting time tokens shortened sequences by 11%, allowing more clinical data to fit into the same context window.
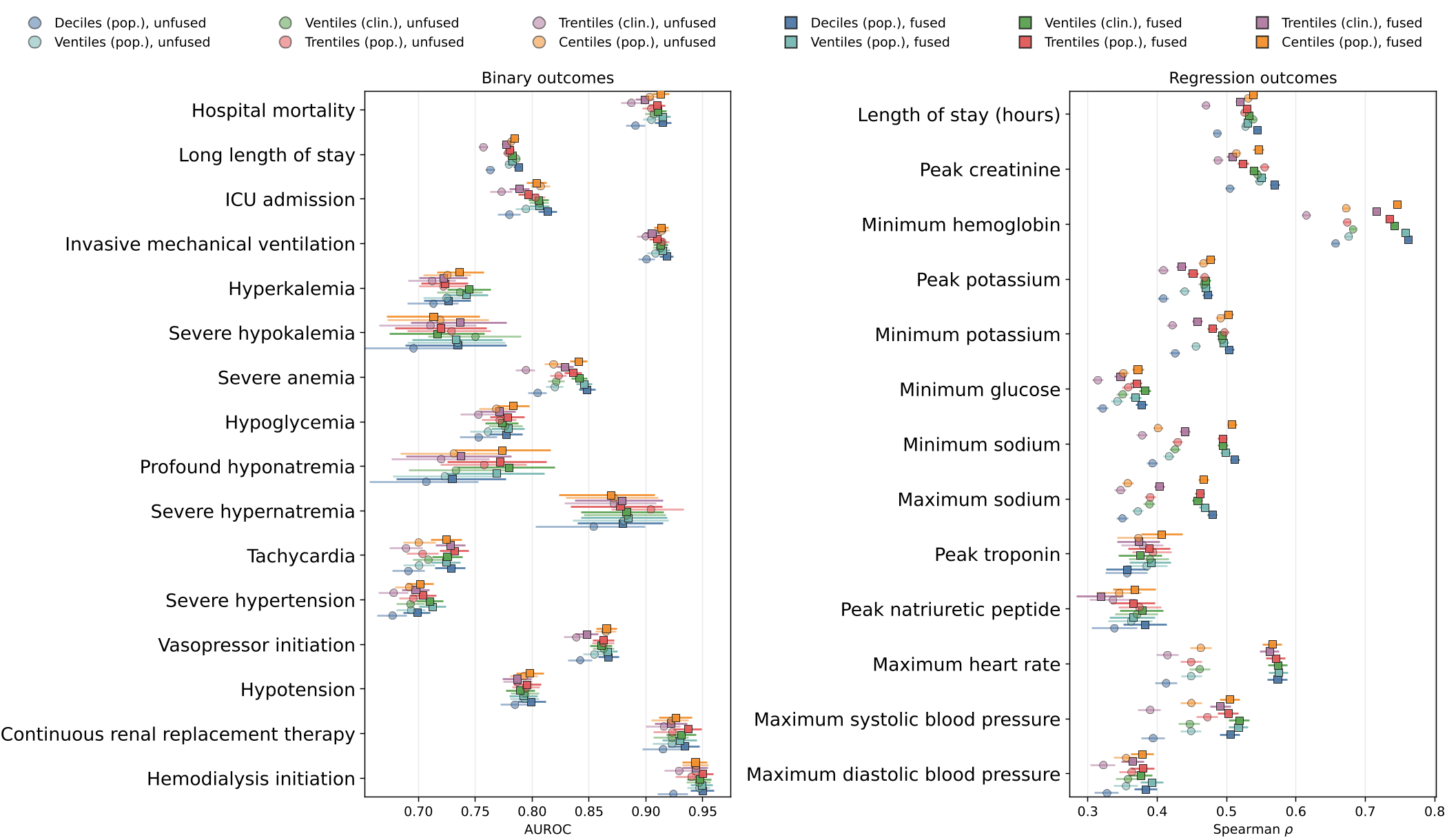 Figure 2: Fused tokenization (squares) consistently outperforms unfused (circles) across almost all binary and regression tasks.
Figure 2: Fused tokenization (squares) consistently outperforms unfused (circles) across almost all binary and regression tasks.
Standardizing the Language: The CLIF Experiment
In Experiment 3, the authors tested if remapping native codes to the CLIF standard significantly altered performance. The results were heartening: CLIF remapping preserved single-site performance while providing a smaller, cleaner vocabulary that is ready for multi-site "federated" use.
Critical Analysis & Future Outlook
This paper serves as a vital reminder that in high-stakes domains like medicine, domain-informed preprocessing is a powerful lever.
Takeaways for Practitioners:
- Default to Fused Tokens: It's a low-overhead change with high ROI.
- Start with Deciles: Don't over-complicate quantization unless you have massive data to support fine-grained bins.
- Ditch Time Tokens: Use relative position IDs to keep sequences lean.
Limitations: The study is limited to a one-epoch budget and a single-site (MIMIC-IV). It remains to be seen if "finer bins" would eventually win out given 100 epochs or 10x more data. However, for most institutional AI projects, this benchmark provides the most realistic "starting set" for EHR modeling today.
Conclusion
Input representation isn't just "preprocessing"—it is the foundation of what a model can fundamentally "see." By optimizing the representation layer before scaling the model, we can build clinical decision support systems that are not only more accurate but more efficient.