SELF1E is a novel Multi-modal Large Language Model (MLLM) framework that achieves high-quality image segmentation without any specialist mask decoders or multiple tokens. By leveraging a single [SEG] token and internal feature refilling, it establishes a new SOTA for decoder-free segmentation across RefCOCO, ReasonSeg, and Open-Vocabulary tasks.
Executive Summary
TL;DR
SELF1E (Unlocking Segmentation from MLLM itSELF with 1 Embedding) is a breakthrough in Multi-modal Large Language Model (MLLM) architecture. It proves that we don't need external "specialist" decoders like SAM or complex multi-token schemes to perform precise segmentation. By refilling semantic residuals into high-resolution visual features and redesigning token interactions, SELF1E achieves SOTA performance on benchmarks like RefCOCO and ReasonSeg while being significantly faster and more lightweight.
Background Positioning
In the landscape of MLLM-based segmentation, the field has been split between Decoder-heavy models (LISA, GLaMM) and Multi-token models (UFO). SELF1E creates a third path: Single-token Decoder-free segmentation. It is a refinement of the MLLM's internal representation power, moving toward a truly unified vision-language architecture.
Problem & Motivation: The Resolution Bottleneck
Modern MLLMs (like Llama or InternVL) typically use Pixel-Shuffle to compress high-resolution images into fewer tokens to save computational costs. For example, a 1024x1024 image might be compressed by a factor of 4. While this works for text-based VQA, it is catastrophic for segmentation, where pixel-level precision is required.
Previous works tried to solve this by:
- External Decoders: Plugging in SAM to "upscale" the MLLM's low-res output (High latency).
- Multiple Tokens: Using 16+ [SEG] tokens to represent different parts of a mask (High complexity).
The Insight: The problem isn't the number of tokens; it's the information loss during compression. If we can "refill" the missing spatial details back into the LLM's final features, a single token is enough.
Methodology: Higher Resolution through Residuals
The core of SELF1E consists of two ingenious modules that restore the lost pixels without adding a heavy decoder.
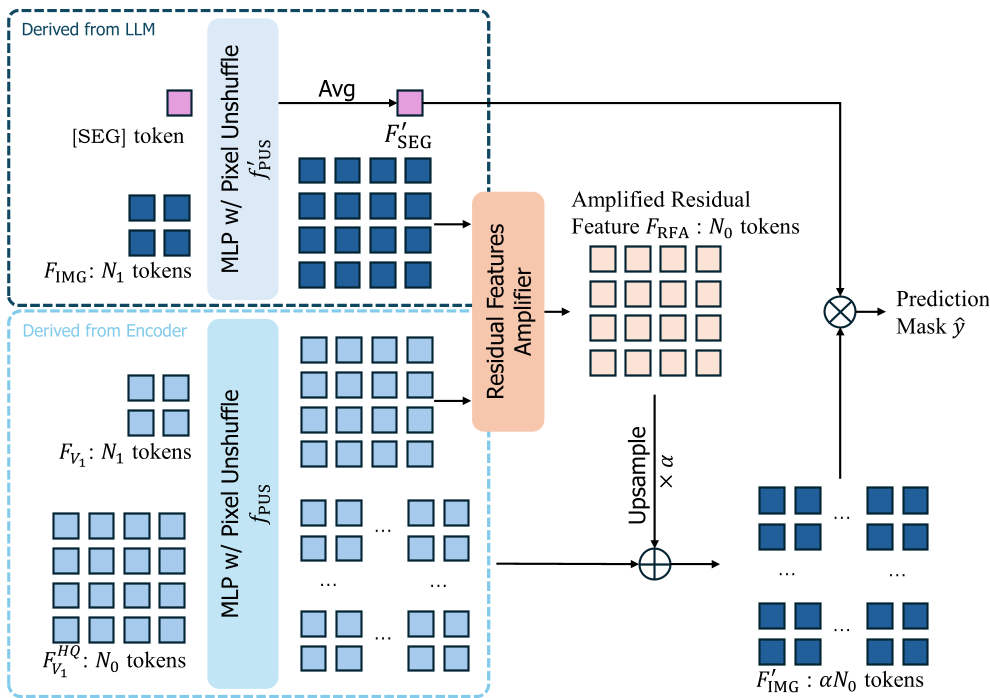
1. Residual Features Refilling (RFR)
The encoder produces high-resolution features (), but the LLM processes low-resolution ones (). SELF1E keeps a "fast-track" for the high-res features by self-replication. It then calculates the "Residual" ()—the difference between what the LLM learned and what the encoder originally saw—and injects this "intelligence" back into the high-res map.
2. Residual Features Amplifier (RFA)
To ensure the fusion is seamless, RFA uses Pixel-Unshuffle operations. This allows the model to align the semantic depth of the LLM with the spatial sharpness of the raw encoder features at an even higher resolution level.
3. Bidirectional Token Interaction
Standard LLMs use Causal Masking (tokens only look backward). SELF1E introduces a Dual Perception Pathway. The [IMG] tokens and the [SEG] token can "talk" to each other bidirectionally. This allows the segmentation token to "probe" the image tokens for spatial boundaries more effectively.
Experiments & Results: Speed Meets Precision
SELF1E was tested against the heavyweights (LISA) and the newcomers (UFO).
- Referring Expression Segmentation: On RefCOCO, SELF1E-8B hits 86.2% cIoU, outperforming models that use a full SAM decoder.
- Reasoning Segmentation: In tasks requiring complex world knowledge (e.g., "Segment the thing that helps me wake up"), it surpassed LISA by 2.7%.
- Inference Efficiency: This is the "killer app." SELF1E hits 9.52 FPS, making it nearly 10x faster than multi-token models and significantly leaner in memory usage.

Visual Evidence
As seen below, the inclusion of RFR and PUS (Pixel-Unshuffle) allows the model to distinguish fine structures, such as the gap between a person's legs, which base MLLMs completely miss.

Critical Analysis & Conclusion
Takeaway
SELF1E proves that the "specialist decoder" era of MLLMs might be coming to an end. By treating segmentation as a resolution-recovery problem rather than a decoding problem, we can simplify the vision-language pipeline significantly.
Limitations
- VQA Trade-off: The authors honestly note a slight degradation in OCR and complex knowledge tasks. The model becomes "spatially biased" after heavy segmentation training.
- Autoregressive Obstacle: The redesign of the attention mask makes multi-round dialogue slightly more complex to implement.
Future Outlook
The "Residual Refilling" concept is powerful. Future iterations might apply this to video segmentation or 3D scene understanding, where the computational savings of a decoder-free approach are even more critical.
Senior Editor's Note: SELF1E is a masterclass in "less is more." By rethinking the intrinsic bottleneck of sequence compression, the authors have delivered a SOTA segmenter that is production-ready for real-time applications.