The paper introduces INTRA (INTrinsic Retrieval via Attention), a framework that unifies retrieval and generation within a single pretrained encoder-decoder model. By leveraging the cross-attention mechanism as a natural retriever, the model directly scores and reuses pre-encoded evidence chunks, achieving SOTA performance on multi-hop QA benchmarks like HotPotQA and MuSiQue.
TL;DR
Current AI systems treat "finding information" (retrieval) and "using information" (generation) as two separate brains. INTRA (INTrinsic Retrieval via Attention)—newly proposed by NVIDIA and Technion researchers—proves that a single encoder-decoder model can do both. By hacking the cross-attention mechanism, INTRA retrieves information directly from its own internal representations, killing the "representation mismatch" and making generation 20x faster by reusing pre-encoded memories.
The Problem: The Modular RAG Tax
In a standard RAG pipeline, the system is fragmented:
- The Retriever (e.g., Pinecone, Faiss, BM25) finds relevant text.
- The Generator (e.g., Llama, GPT) reads that text and re-processes it.
This leads to two major inefficiencies. First, the Representation Mismatch: the retriever's idea of "relevance" might not align with what the generator actually needs to answer the question. Second, the Encoding Tax: every time a document is retrieved, the generator must re-encode those tokens into KV-caches, wasting massive amounts of GPU cycles.
Methodology: Mining the Cross-Attention
The researchers at NVIDIA realized that attention is already a retrieval operation. In an encoder-decoder model, the decoder "queries" the encoder's "keys" to find relevant info.
1. Reverse-QWK: The Key to Latent Scaling
A major technical hurdle was that standard Transformers use different projections for keys () at every single layer. This makes it impossible to build a single "search index" for the whole model. INTRA introduces Reverse-QWK (Query-Key Projection). It flips the math so that the complexity is moved to the query side, allowing the model to use one single, shared encoder representation across all layers.
2. MaxSim & Retrieval Tokens
To turn token-level attention into document-level scores, INTRA uses a MaxSim operator (popularized by ColBERT). It further augments the decoder with "Retrieval Tokens"—special learnable markers that act like specialized "search fingers" to probe the encoder’s memory.
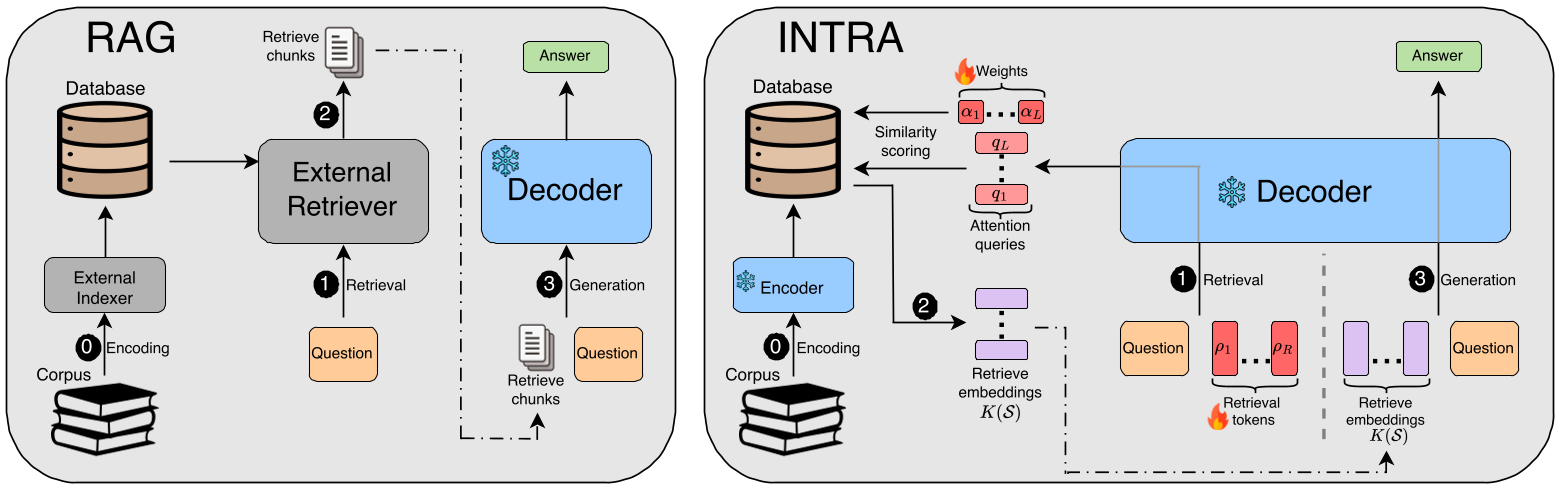 Figure 1: Comparison between standard RAG (modular) and INTRA (unified architecture).
Figure 1: Comparison between standard RAG (modular) and INTRA (unified architecture).
Experiments: Winning at Multi-Hop Reasoning
INTRA was tested on the toughest QA benchmarks like HotPotQA and MuSiQue, which require "multi-hop" reasoning (connecting A to B to C).
Key Findings:
- Superior Recall: INTRA outperformed strong engineered pipelines (BM25 + Rerankers) because its retrieval was perfectly "aligned" with its generator's needs.
- Efficiency Explosion: In tests with 500 chunks, INTRA's Time-to-First-Token (TTFT) was only 65.7ms, while standard RAG took 1.25 seconds. That's a ~19x speedup in responsiveness.
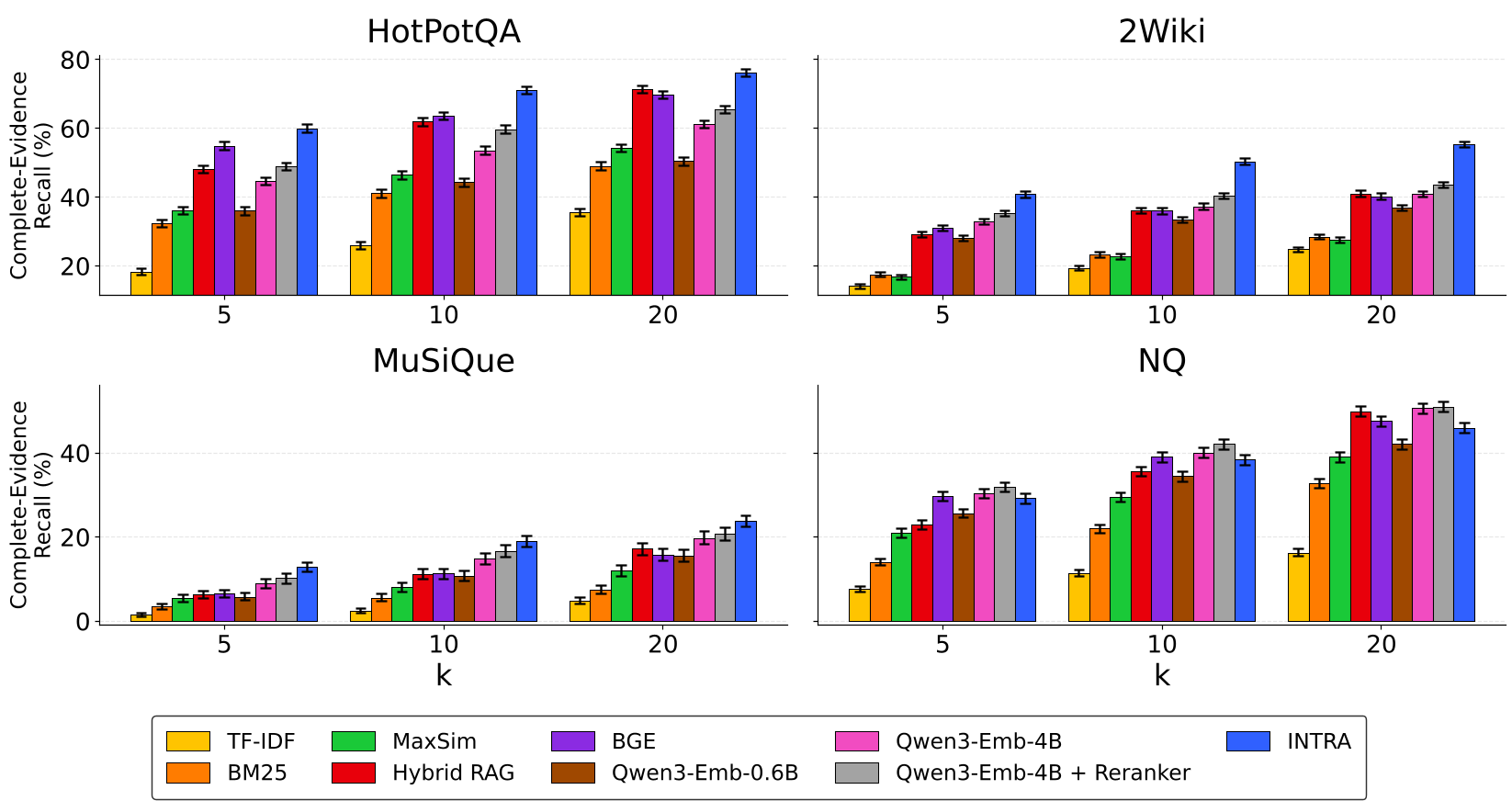 Figure 2: Complete-evidence recall on multi-hop benchmarks. Note the significant lead of INTRA in complex reasoning tasks.
Figure 2: Complete-evidence recall on multi-hop benchmarks. Note the significant lead of INTRA in complex reasoning tasks.
Critical Analysis: The End of Separate Retrievers?
By showing that retrieval is an intrinsic capability of attention, this work challenges the industry's obsession with external vector databases for every task. If we can store the "latent memories" of a model (which NVIDIA notes is around 2.5TB for a billion tokens), we effectively gain a retriever that "understands" the generator's internal logic.
Limitations to Consider:
- Encoder-Decoder Only: This method relies on cross-attention. Extending this to purely decoder-only models (like GPT-4 or Llama 3) requires new architectural thinking.
- Storage Overhead: Storing raw latent vectors is more memory-intensive than storing simple 1536-dimensional embeddings.
Conclusion
INTRA isn't just a new RAG algorithm; it’s a shift in philosophy. It suggests that if we build models with better internal memory access, the need for complex, multi-stage "Frankenstein" pipelines disappears. The model doesn't need to "look up" info in a separate database—it just needs to "remember" it from within.
Senior Editor's Take: INTRA is a brilliant manifestation of the 'Software 2.0' trend—replacing hand-engineered pipelines with differentiable, learned components that share a single latent language.