本文推出了 SEMANTICQA,这是一个专门用于评估语言模型 (LMs) 处理语义短语(如习语、搭配、名词复合词等)能力的基准测试套件。该套件集成了多种多词表达式 (MWE) 资源,涵盖提取、分类及解释等多维度任务,旨在诊断模型在非平凡语义理解方面的真实水平。
TL;DR
尽管大语言模型(LMs)在数学和逻辑竞赛中屡创佳绩,但在处理“kick the bucket”(去世)这类字面意思与实际含义脱节的**语义短语(Semantic Phrases)**时,依然显得力不从心。本文推出 SEMANTICQA 基准测试,通过提取、分类、解释三大原子操作,深度诊断了包括 GPT-5, DeepSeek-R1 在内的顶尖模型的语义一致性,揭示了模型在结构化语义 grounding 上的本质脆弱。
背景:被忽视的“眼中钉”
早在 2002 年,NLP 大牛 Ivan Sag 就将多词表达式(MWE)称为 NLP 领域的“眼中钉”(Pain in the Neck)。这些词组的含义往往无法通过其组成部分简单推导。在 LLM 时代,我们习惯于用复杂的数学题和代码库来衡量模型,却忽略了模型是否真的理解了“Silver Lining”背后的语义逻辑。
目前的评估存在两个严重问题:
- 任务混淆:把识别和解释混在一起,分不清模型是懂了语义,还是猜中了套路。
- 虚假繁荣:基于 BERTScore 等指标的解释任务得分很高,但这可能只是因为模型擅长说“漂亮话(Fluent Paraphrasing)”,而非具备稳健的语义表征。
核心方法:操作对齐与顺序组合
为了拆解这些难题,作者设计了一个**操作对齐(Operation-aligned)**的框架:
- 提取 (Extraction):在句子中精准框选出短语(要求 Exact Match)。
- 分类 (Classification):判断短语的语义关联,如“Magn”(如 heavy rain 中的 heavy 起加强作用)。
- 解释 (Interpretation):生成上下文相关的改写。
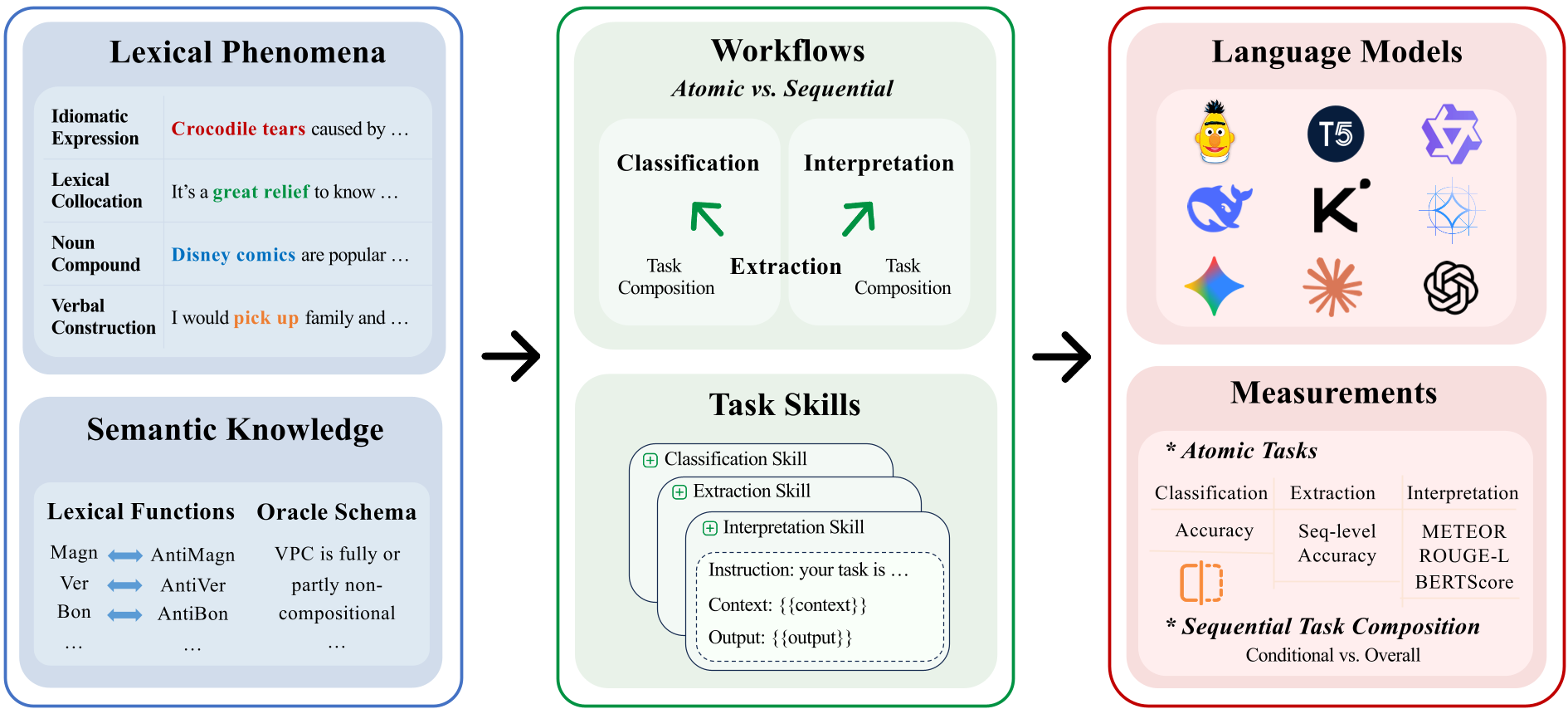
文章独具匠心地引入了顺序任务组合(Sequential Task Compositions):先提取(Where),再解释(What)。这种设计模仿了人类处理复杂语义的真实流程,也成了检测模型瓶颈的利器。
实验发现:谁才是真正的语义王者?
1. 提取任务是“阿喀琉斯之踵”
实验显示,即使是 GPT-5 这样级别的模型,在没有任何显式定义的情况下,提取变体短语的准确率也并不理想。
2. 只有流畅度,没有稳定性
当模型被要求执行“提取+解释”的组合任务时,其表现显著下降。数据显示,模型在独立测试中能够写出不错的解释,但一旦依赖于自己提取的短语,错误逻辑便会迅速传播。
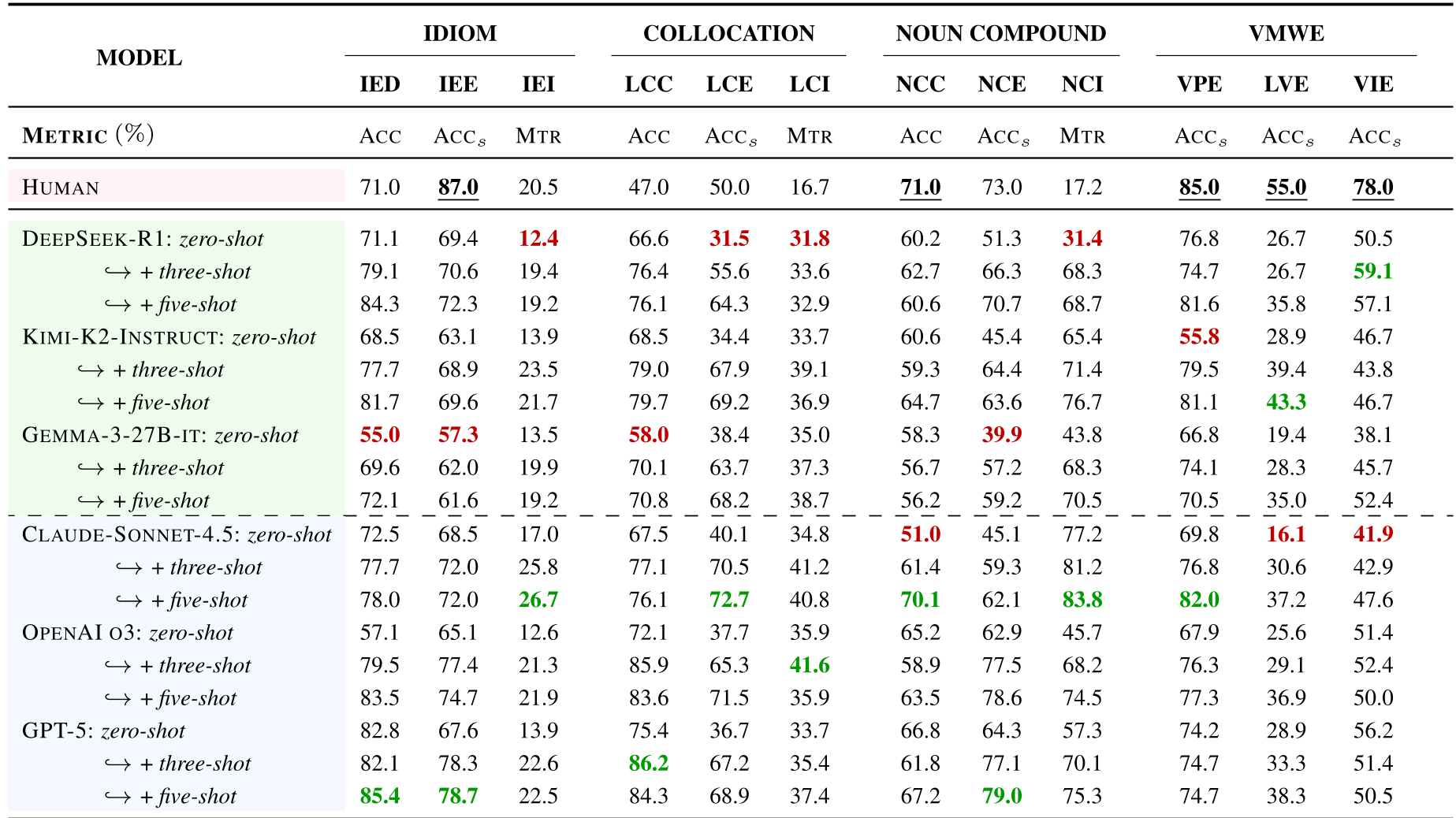
3. Oracle Schema 的魔力
有趣的是,当作者在提示词中加入短语的**语义定义(Oracle Schema)**后,所有模型的提取性能都迎来了爆发式增长(如 DeepSeek-R1 提升了 12.5%)。这说明当前模型极其依赖外部显式引导,其内在的“常识性理解”依然单薄。
深度洞察
- 指标的陷阱:在解释任务中,高度的 embedding 相似度往往掩盖了语义支柱的缺失。我们需要更加严格的 Exact Match 或结构化约束。
- 分类尺度的挑战:随着语义分类(如 Lexical Functions)从 2 类扩展到 16 类,LLM 的表现呈现断崖式下跌,而传统的监督学习基线却表现平稳。这表明 LLM 在处理极细粒度、专业性强的语义关系时,仍然无法完全取代专门的微调模型。
总结与未来
SEMANTICQA 为我们提供了一面镜子,映照出 LLM 在流利表达背后的语义理解断层。未来的研究不应仅追求任务层面的 SOTA,更应探索如何构建具有结构化 Grounding 能力的统一语义空间,让模型不仅能“吟诗作赋”,更能真正理解那句“Pain in the Neck”到底有多痛。