RLDX-1 is a general-purpose Vision-Language-Action (VLA) model designed for dexterous robotic manipulation, built upon a Multi-Stream Action Transformer (MSAT) and a Qwen3-VL backbone. It achieves state-of-the-art performance across diverse embodiments (humanoid, single-arm, dual-arm), notably outperforming frontier models like π0.5 and GR00T N1.6 in complex real-world tasks.
Executive Summary
RLDX-1 is a technical breakthrough in the field of Vision-Language-Action (VLA) models. While the industry has been obsessed with "versatile intelligence"—the ability of a robot to understand a scene and a command—RLDX-1 argues that this is not enough for human-level dexterity. For a robot to catch a moving object or insert a plug into an occluded socket, it needs functional capabilities: motion awareness, long-term memory, and physical sensing.
By introducing the Multi-Stream Action Transformer (MSAT) and a sophisticated three-stage training regimen, RLDX-1 sets new records across both simulation (LIBERO, RoboCasa365) and real-world humanoid platforms (ALLEX, OpenArm), doubling the success rates of top-tier baselines like π0.5 and GR00T N1.6 in high-DoF tasks.
Problem & Motivation: The "Versatility" Trap
Current VLAs often rely on frozen or fine-tuned Vision-Language Models (VLMs) to generate actions. The problem is that these models are essentially "blind" to the physical nuances of time and touch.
- Lack of Motion Awareness: Static frames can't distinguish between a conveyor belt moving at 5cm/s vs 20cm/s.
- Short-Term Memory: Most models only look at a few recent frames, failing at tasks like the "Shell Game" where an object is hidden under a cup several seconds ago.
- Physics Blindness: Vision cannot see the torque required to twist a bulb or the tactile feedback needed to grip an egg without breaking it.
Methodology: The Multi-Stream Action Transformer (MSAT)
The core of RLDX-1 is the Multi-Stream Action Transformer (MSAT). Unlike architectures that flatten all inputs into a single sequence, MSAT maintains separate "streams" for Cognition (Vision+Language), Action, and Physics.
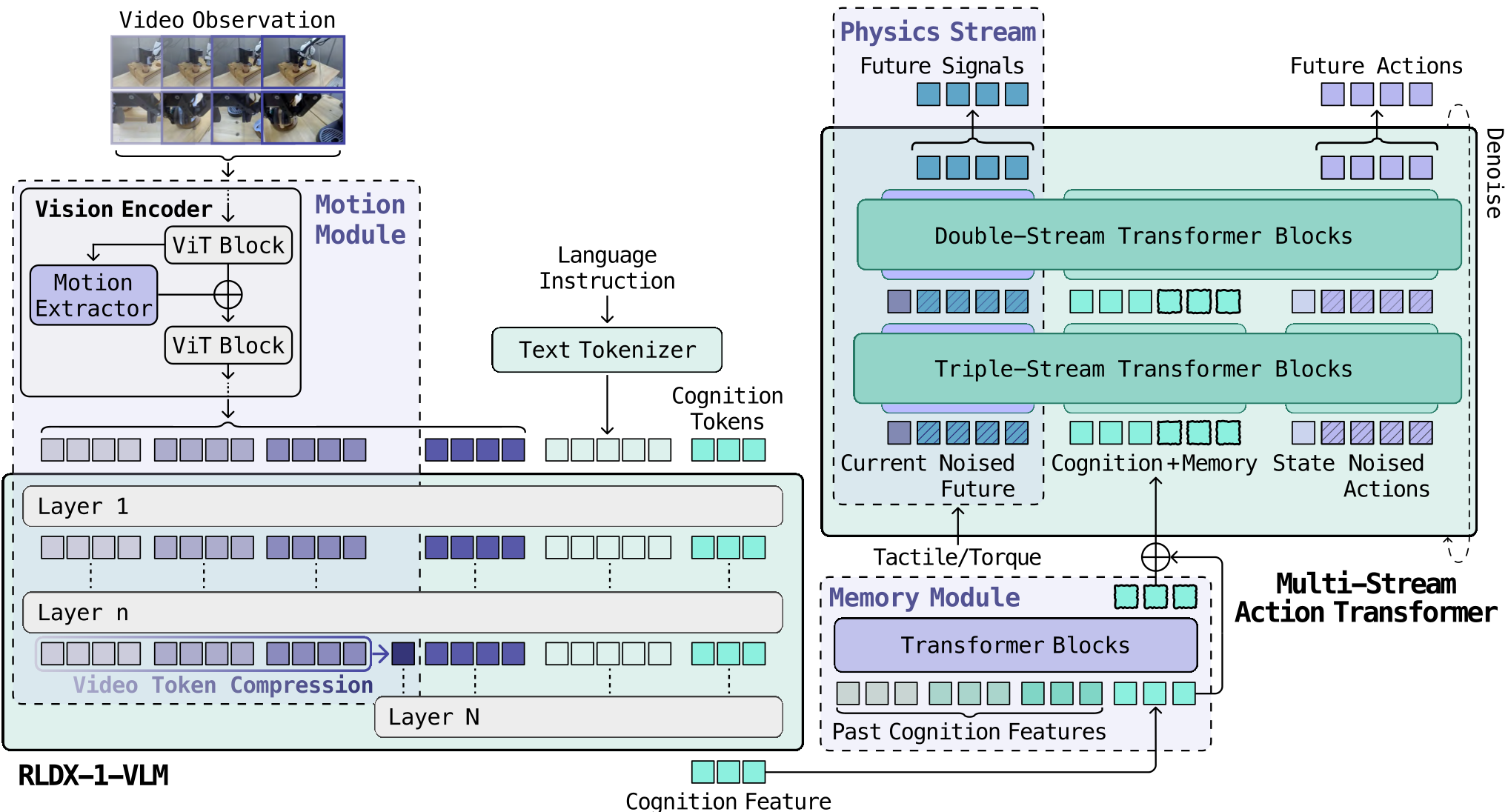
Key Architectural Pillars:
- Motion Module: Uses space-time self-similarity (STSS) to capture temporal dynamics within the vision encoder.
- Memory Module: A dedicated Transformer queue that caches cognition tokens from past timesteps, enabling reasoning across several seconds.
- Physics Stream: Explicitly processes joint torque and tactile signals (e.g., AnySkin), treating them as equal citizens to visual tokens.
- Flow-Matching: Instead of simple regression, it uses a Diffusion-style flow-matching objective to denoise action trajectories.
Training a Humanoid Expert
RLDX-1's path to intelligence involves a three-stage specialized pipeline:
- Pre-training: 1.5M episodes of diverse multi-embodiment data to learn general action priors.
- Mid-training: This is where the magic happens. The model is trained on embodiment-specific data (ALLEX/Franka) to inject the new functional capabilities (memory, physics, motion).
- Post-training: Utilizing RECAP (Reinforcement Learning from Experience). It uses a VLM-based critic to provide advantage-conditioned supervision, allowing the model to refine its "last-mile" precision in tasks like Light Bulb Twisting.
Experiments: Real-World Superiority
The results on the ALLEX humanoid are particularly striking. In the "Object-in-Box Selection" task—a trial of memory—RLDX-1 achieved 91.7% success, while π0.5 collapsed to 33.3%.
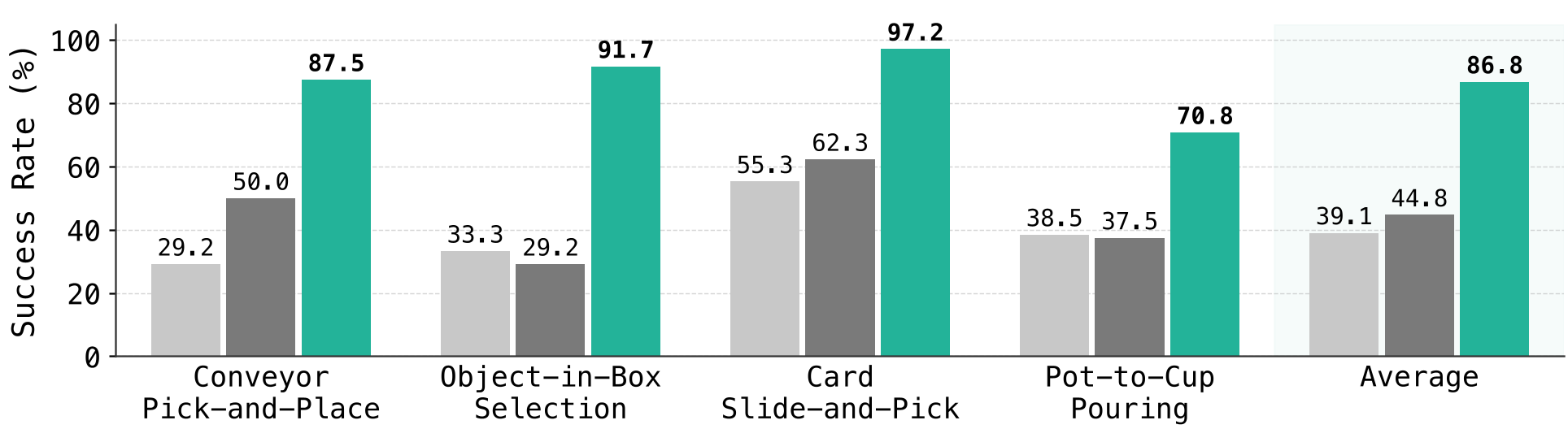
In "Conveyor Pick-and-Place," RLDX-1 demonstrated its motion awareness by successfully interpolating its movements for unseen conveyor speeds, whereas baselines failed to adapt their tempo.
Inference: Built for Real-Time
High latency equals robot failure. RLDX-1’s team didn't just stop at a good model; they optimized the inference stack. By using Static Graph Conversion and Custom Kernel Fusion, they bypassed the overhead of PyTorch Eager execution and Torch Compile's fragmentation. This reduced per-step latency to just 43.7ms, enabling the high-frequency control loops necessary for fluid humanoid motion.
Critical Analysis & Conclusion
RLDX-1 is a seminal work because it shifts the conversation from "how big can our VLM be?" to "how can our VLA be more physically grounded?". Its use of synthetic data via video generative models also provides a roadmap for scaling robotics data without expensive manual teleoperation.
Limitations: While powerful, the model still requires embodiment-specific mid-training to unlock its full potential. Future work should look toward "Zero-shot Functionality"—enabling a model to use a new sensor (like a new tactile skin) without retraining.
The Takeaway: RLDX-1 proves that for robots to truly enter our homes and factories, they need to do more than see and speak; they need to feel, remember, and move with the rhythm of the physical world.