The paper introduces a robust framework for 4D dynamic scene reconstruction built upon the Visual Geometry Grounded Transformer (VGGT). It achieves state-of-the-art performance on benchmarks like DyCheck and DAVIS, reducing Mean Accuracy error by 13.43% and improving segmentation F-measure by 10.49% without requiring task-specific fine-tuning.
TL;DR
Reconstructing dynamic 4D scenes from a single video is notoriously difficult because motion "breaks" the geometric rules (epipolar constraints) that most models rely on. This paper introduces a zero-shot, training-free enhancement for 3D foundation models (like VGGT) that uses hierarchical uncertainty modeling to separate moving objects from static backgrounds. By weighting attention heads by entropy and modeling depth as a probabilistic distribution, it achieves a 13.43% reduction in geometric error and significantly cleaner reconstructions.
Problem & Motivation: The "Static" Blind Spot of 3D Models
Modern 3D foundation models like DUSt3R and VGGT are masters of static scenes. They use global attention to find correspondences across views. However, they possess a fatal flaw: the rigidity assumption.
When an object moves, it introduces a geometric residual () into the epipolar constraint. For a transformer, this manifests as "diffuse attention"—the model tries to match a moving pixel to a static background, causing the camera pose to "drift" and the 3D points to appear as smeared "ghosts" or floaters. Previous attempts to fix this required heavy fine-tuning on dynamic datasets or slow per-video optimization. The authors of this paper ask: Can we detect and ignore these dynamic distractors purely through the lens of uncertainty?
Methodology: The Three Levels of Uncertainty
The framework addresses motion corruption at the feature, geometry, and constraint levels.
1. Feature Level: Entropy-Guided Subspace Projection
Not all attention heads in a transformer are created equal. Some focus sharply on objects (high information), while others are diffuse (noise). The authors use an information-theoretic approach, calculating the spatial variance of each head. By weighting heads with high variance (low entropy) more heavily, the model naturally amplifies genuine motion cues while suppressing the "background noise" that causes pose drift.
2. Geometric Level: Local-Consistency Purification
Even with better features, initial dynamic point clouds are noisy. The authors implement a radius-based neighborhood constraint. If a dynamic point doesn't have enough "neighbors" within a 2% radius of the scene's bounding box, it's discarded as a structural outlier. This ensures that only spatially continuous moving objects are preserved.
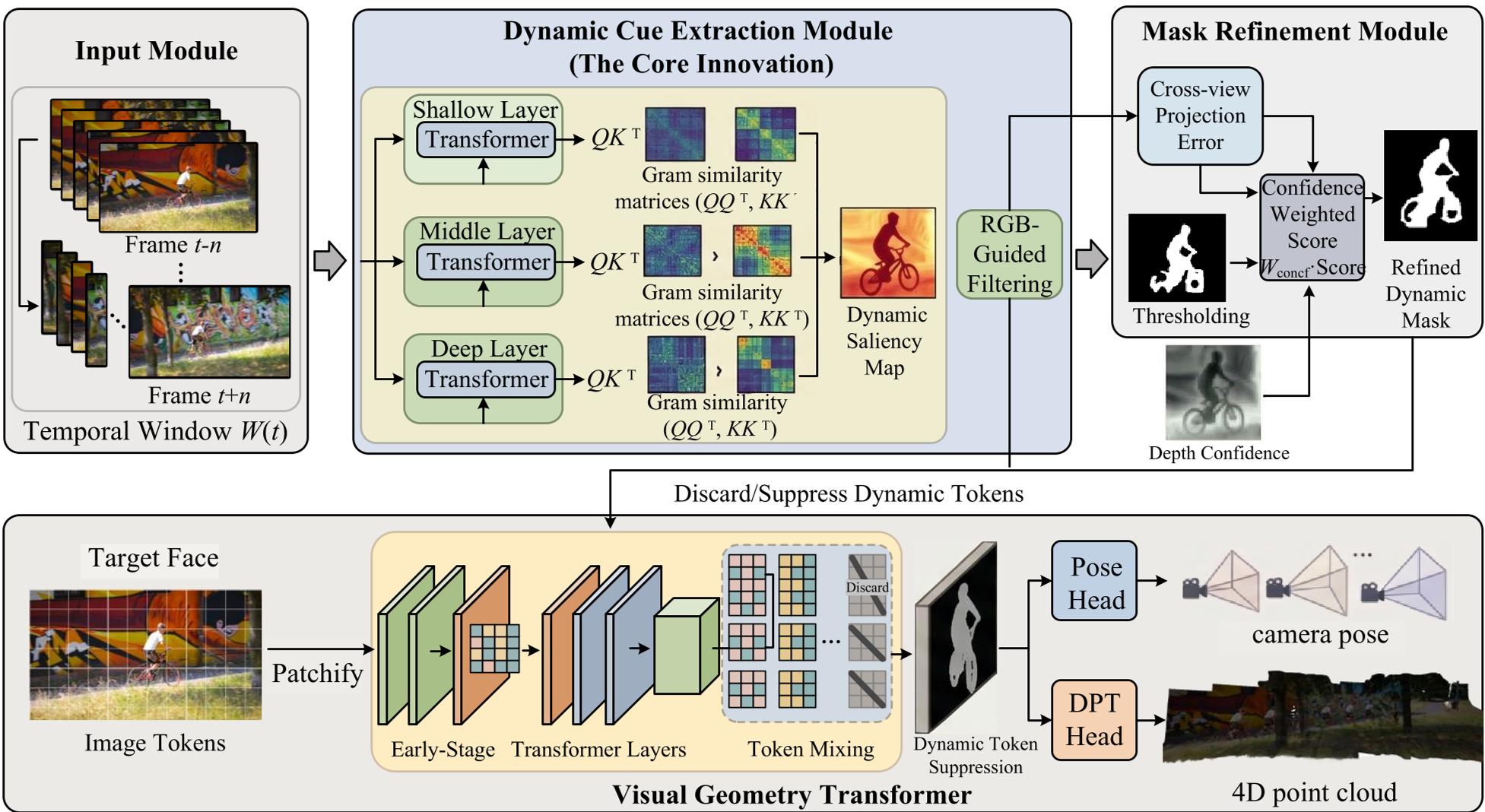
3. Constraint Level: Heteroscedastic MLE Refinement
This is the mathematical heart of the paper. Standard projection errors assume that all pixels are equally reliable. In reality, occlusions and textureless surfaces create massive uncertainty. The authors reformulate the projection loss as a heteroscedastic Maximum Likelihood Estimation (MLE) problem. They treat depth as a Gaussian distribution and learn a "confidence logit" to weight the residuals. Essentially, the model learns to "trust" certain views more than others during the final mask refinement.
Experiments & Results: SOTA without Fine-Tuning
The model was tested against top-tier baselines including MonST3R and VGGT4D.
- Geometric Precision: On the DyCheck dataset, the method reduced the Mean Accuracy error to 0.0303 (a ~13% improvement over the baseline).
- Segmentation: On DAVIS-2016, it achieved a Boundary F-measure of 55.47, highlighting much sharper object edges compared to previous methods.
- Robustness: As shown in the qualitative results, the framework keeps camera poses stable even when large objects occupy the frame, preventing the "catastrophic drift" common in vanilla VGGT.
 Figure: The proposed method (bottom) recovers clean, distinct moving objects with far fewer "floater" artifacts compared to the baseline VGGT4D.
Figure: The proposed method (bottom) recovers clean, distinct moving objects with far fewer "floater" artifacts compared to the baseline VGGT4D.
Critical Analysis & Conclusion
Takeaway
The genius of this work lies in its training-free nature. By identifying that dynamic objects inherently manifest as "high uncertainty" regions in a static-trained model, the authors turned a weakness into a diagnostic tool.
Limitations
While highly effective, the method still relies on the base VGGT model's ability to provide a reasonable initial guess. In extremely fast-moving scenes where motion blur is severe, the initial entropy-guided projection might struggle to find a stable subspace. Furthermore, the complexity of global attention in the backbone remains a bottleneck for very long sequences.
Future Outlook
This uncertainty-aware paradigm is likely to influence next-generation 4D foundation models. Moving beyond "training for dynamics" toward "modeling the uncertainty of dynamics" offers a more mathematically grounded and scalable path for autonomous robotics and immersive media.