The paper introduces RPiAE (Representation-Pivoted Autoencoder), a novel visual tokenizer that enhances both image generation and editing for latent diffusion models. By utilizing a representation-initialized encoder governed by Pivot Regularization, it achieves a 2.25 gFID on ImageNet-1K and superior reconstruction fidelity compared to previous representation-based methods.
TL;DR
RPiAE (Representation-Pivoted Autoencoder) solves a major bottleneck in Latent Diffusion Models (LDMs): the trade-off between generative tractability (easy training) and reconstruction fidelity (detailed editing). By unfreezing a DINOv2-based encoder and applying a "Pivot Regularization" loss, RPiAE creates a latent space that is both semantically rich for generation and structurally precise for editing.
The Core Conflict: Why Existing Tokenizers Fail
Most LDMs rely on a VAE to compress images into a latent space. However, this creates a dilemma:
- Vanilla VAEs: Great for reconstruction, but the latent space is unorganized, making the diffusion model work harder to learn "what" it is drawing.
- Frozen Representation Models (e.g., RAE): By using frozen DINOv2 features, the diffusion model learns quickly due to the strong semantic geometry. However, because the encoder can't adapt, the "reconstruction ceiling" is low—leading to artifacts in image editing and loss of identity.
RPiAE argues that we shouldn't have to choose. We can have an encoder that "understands" like DINOv2 but "sees" fine details like a VAE.
Methodology: Pivot Regularization & Three-Stage Training
The secret sauce of RPiAE is its training architecture, which employs a Pivot Replica Encoder (PRE). This is a frozen copy of the pretrained model that acts as a "semantic anchor."
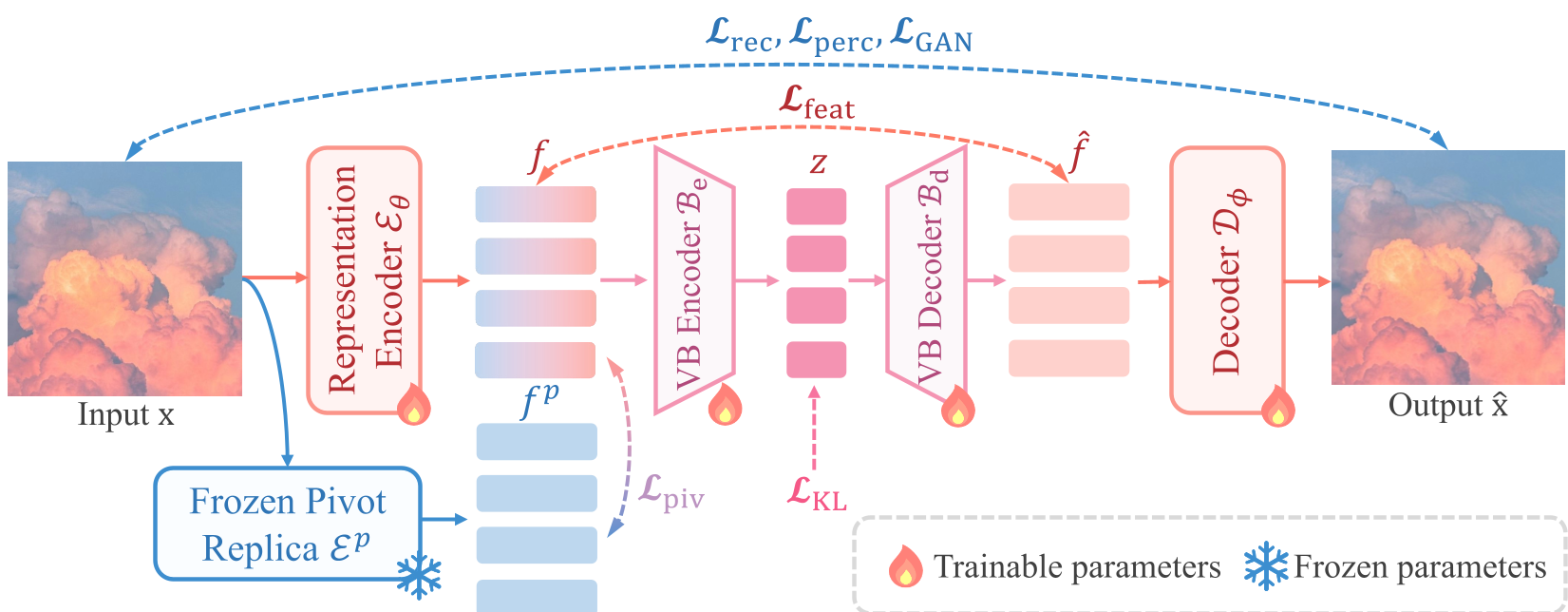
1. Pivot Regularization
Unlike previous methods that freeze the encoder, RPiAE unfroze it. To prevent the encoder from "forgetting" its semantic knowledge (semantic drift) while chasing pixel-perfect reconstruction, the authors introduce a Pivot Regularization Loss (). This loss ensures the trainable encoder's features stay close to the frozen PRE features.
2. The Variational Bridge (VB)
Representation models like DINOv2-B output high-dimensional features ( channels). This is too "heavy" for diffusion. RPiAE introduces a Variational Bridge—a Transformer-based encoder-decoder pair that compresses these features into a compact 64-channel latent space () regularized by a KL-divergence term.
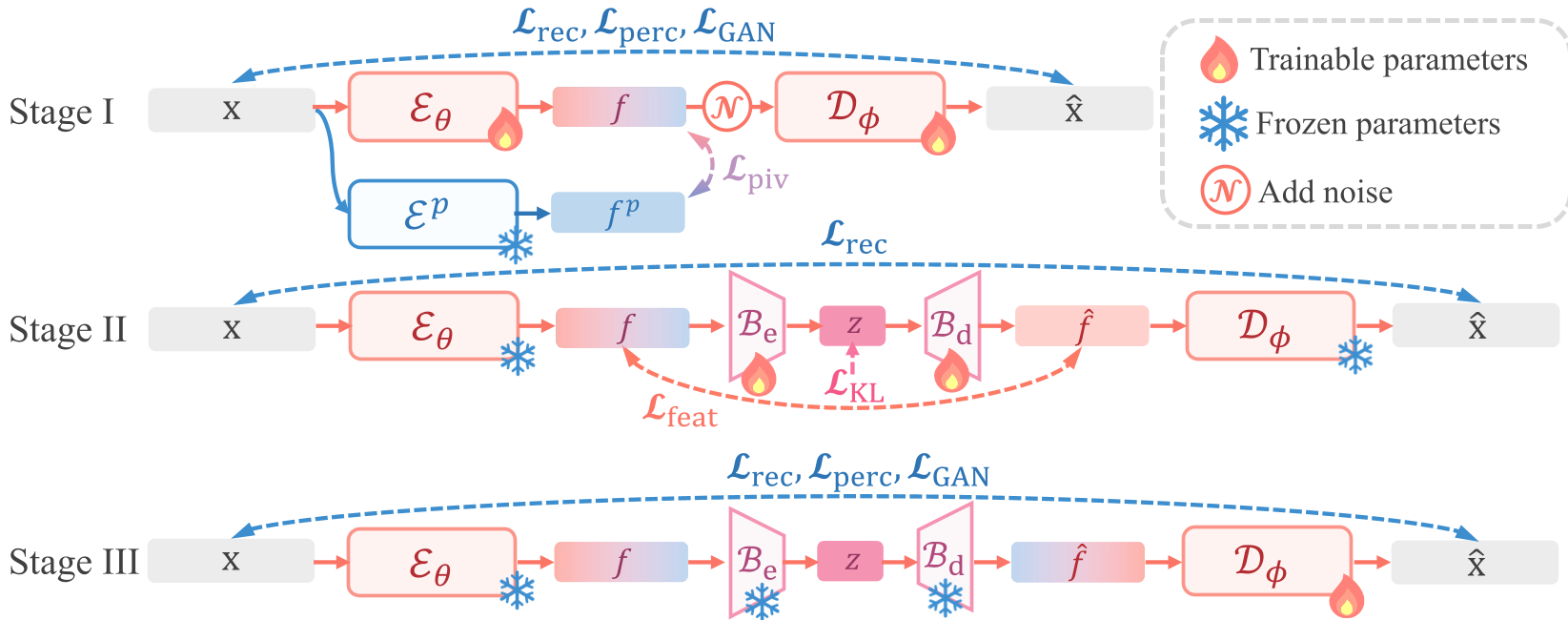
3. Objective-Decoupled Strategy
To avoid optimization instability, the authors propose a three-stage training pipeline:
- Stage I: Tune the Encoder and Decoder for reconstruction under Pivot Regularization.
- Stage II: Freeze the ends and train the Variational Bridge for compression.
- Stage III: Freeze everything except the Decoder to polish the final pixel output.
Experimental Results: The Best of Both Worlds
RPiAE was tested on ImageNet-1K and several text-to-image/editing benchmarks (GenEval, DPG-Bench).
- Reconstruction: It achieved an rFID of 0.50, significantly better than the RAE-B baseline (0.57) and approaching specialized reconstruction models.
- Generation: On class-conditional generation, it reached a gFID of 1.51 (with CFG), outperforming both frozen-encoder models and standard VAE models.
The qualitative results (Figure 6 in the paper) show that RPiAE is far better at recovering complex geometric textures—like fences and honeycombs—where previous representation-based models produced blurry or hallucinatory results.

Deep Insight: Does the Encoder Lose its "Brain"?
A critical question for any "unfrozen" model is whether it loses its original purpose. The authors tested the RPiAE encoder on Linear Classification. The original DINOv2-B gets 84.56% accuracy; the RPiAE version (after being pushed to favor reconstruction) still maintains 84.18%. This suggests that Pivot Regularization successfully "pivots" the model without destroying its underlying understanding.
Summary & Future Outlook
RPiAE proves that the "frozen vs. trainable" debate for tokenizers is a false dichotomy. By using a replica as a semantic anchor, we can achieve high-fidelity editing without sacrificing the generative speed and quality that semantic priors provide.
Limitations: The three-stage training adds complexity to the pipeline, and the reliance on a specific representation model (DINOv2) means the tokenizer's quality is still somewhat tied to the quality of the pretrained "pivot."
Future work could involve extending this to video tokenization, where temporal consistency is even harder to balance with per-frame semantic understanding.