The paper introduces the Rules-and-Facts (RAF) model, a minimal theoretical framework that enables the precise characterization of a neural network's dual ability to learn structured rules and memorize unstructured exceptions. By bridging teacher-student generalization and Gardner-style capacity analysis, the authors demonstrate that overparameterization is the key enabler for the simultaneous realization of both objectives.
Executive Summary
In the classical view of machine learning, generalization and memorization are often portrayed as bitter rivals. We are taught that a model that memorizes its training data too well will fail to generalize to new examples. Yet, modern Large Language Models (LLMs) contradict this daily: they follow complex grammatical rules (generalization) while accurately recalling specific, idiosyncratic facts like historical dates (memorization).
The "Rules-and-Facts" (RAF) model, recently introduced by researchers at EPFL, provides the first rigorous theoretical framework to analyze this coexistence. By utilizing the tools of statistical physics, the authors prove that overparameterization is not a bug, but a critical feature that allows a model to "compartmentalize" its capacity—using some dimensions to learn the underlying physics of the data and others to store exceptions.
The Core Conflict: Why is this hard?
Standard learning theory (e.g., Rademacher complexity) suggests that a model with the capacity to fit random labels is inherently prone to poor generalization. In the RAF task, the learner encounters a dataset where:
- Rules: Most labels follow a structured pattern (a hidden "teacher" vector).
- Facts: A fraction $\epsilon$ of the data is purely random—these are "exceptions" that the model must recall correctly.
Linear models (like the simple Perceptron) fail here because they lack the "internal room" to do both. If they focus on the rule, they miss the facts; if they fit the facts, their internal weights become "corrupted" by noise, destroying their ability to predict new data.
Methodology: Decomposing the Kernel
The authors analyze the high-dimensional limit ($n, d o \infty$) of Kernel Regression and Random Features. The breakthrough comes from looking at the Kernel Geometry. They show that any dot-product kernel can be reduced to two effective parameters:
- $\mu_1$: The linear component that captures the "Rule."
- $\mu_\star$: The aggregate nonlinear components that handle the "Facts."
By adjusting the ratio between these two (an angle they call $\gamma$), and the regularization strength ($\lambda$), they can precisely control how a model allocates its "brainpower."
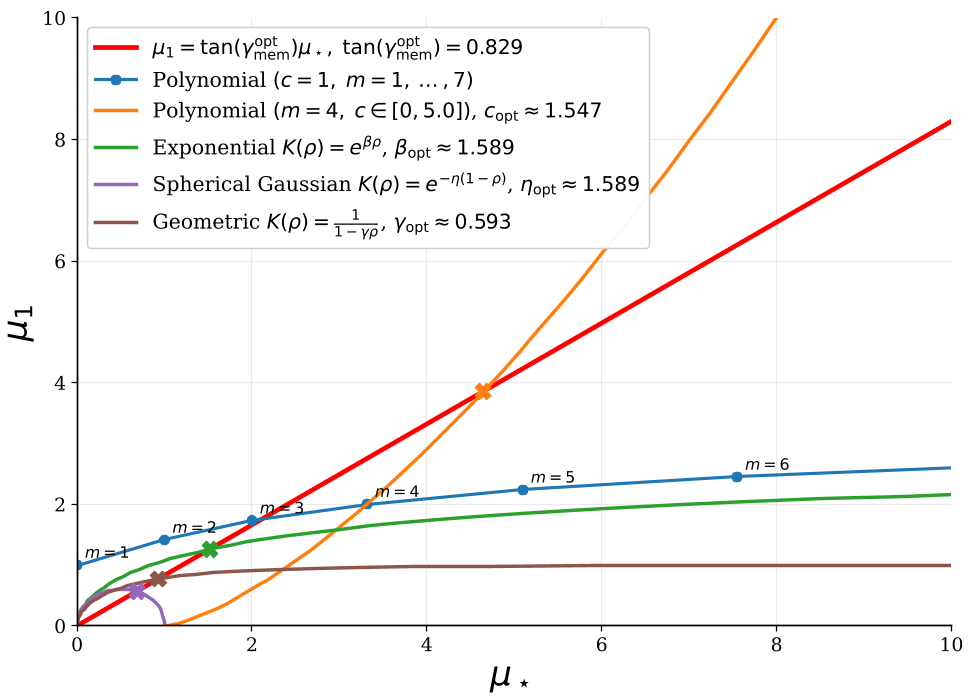 Figure 1: Kernel families in the $(\mu_\star, \mu_1)$ plane. Different kernels (RBF, Polynomial, ReLU) occupy different positions, determining their innate bias toward rules or facts.
Figure 1: Kernel families in the $(\mu_\star, \mu_1)$ plane. Different kernels (RBF, Polynomial, ReLU) occupy different positions, determining their innate bias toward rules or facts.
Key Findings: The Power of Overparameterization
The study reveals that overparameterized models (where the number of parameters $p \gg d$) can achieve a state of "Useful Benign Overfitting."
Whereas a linear model shows a sharp trade-off curve, kernel models with sufficient nonlinear capacity ($\mu_\star > 0$) can move toward the zero-memorization-error limit without a catastrophic loss in generalization. This is visualized in the "Generalization-Memorization trade-off" curves below.
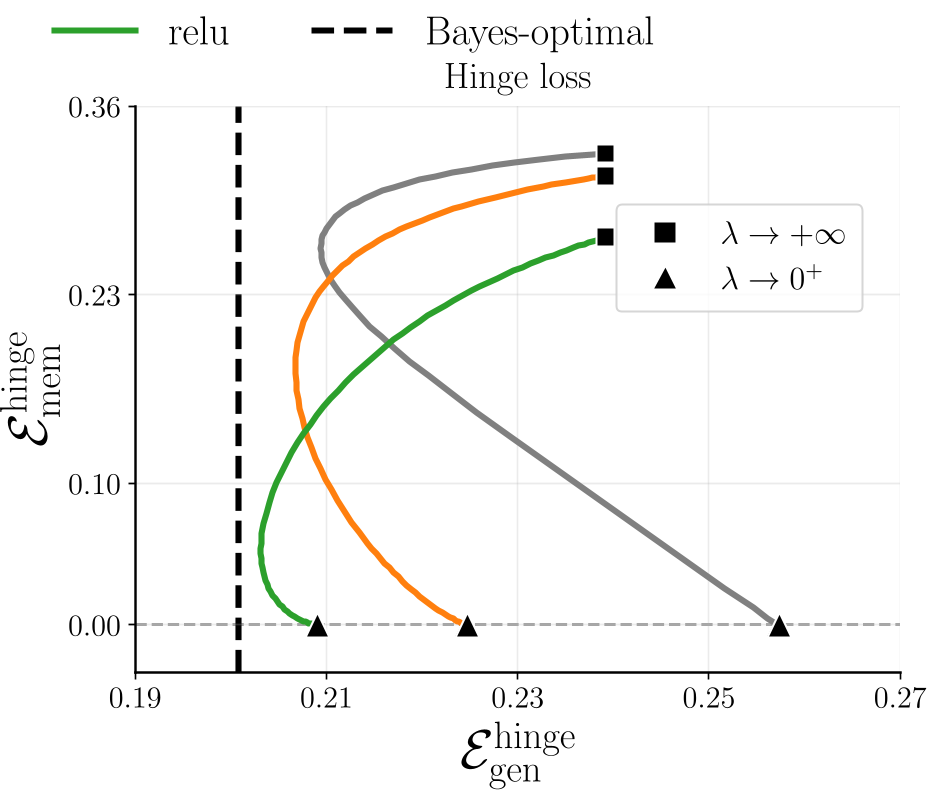 Figure 2: The trade-off induced by regularization $\lambda$. Notice how overparameterized models (ReLU, erf) reach much lower error pairs than the linear perceptron baseline (gray line).
Figure 2: The trade-off induced by regularization $\lambda$. Notice how overparameterized models (ReLU, erf) reach much lower error pairs than the linear perceptron baseline (gray line).
The Suboptimality Gap
One provocative finding is the Generalization Rate. The authors prove that for any fixed kernel method in the RAF model, the generalization error scales at a rate of $\alpha^{-1/2}$. However, the Bayes-optimal rate (the best possible theoretical performance) is $\alpha^{-1}$. This means current kernel-based "fixed-feature" models are fundamentally less efficient than the theoretical limit, suggesting that Feature Learning (where the model adapts its internal representation) is necessary to reach peak efficiency.
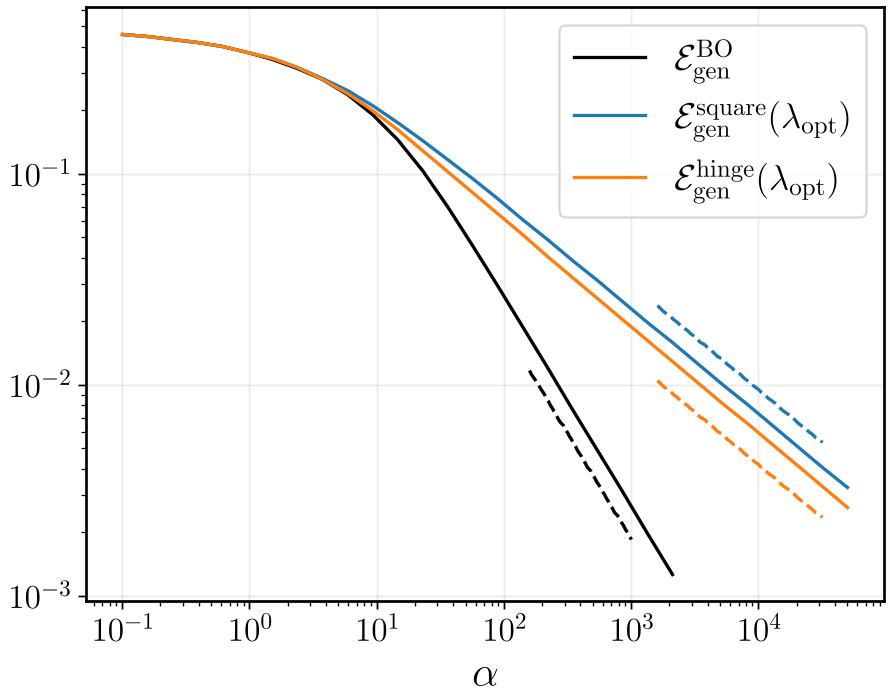 Figure 3: Log-log plot showing the alpha gap. The kernel methods (square/hinge) follow the -1/2 slope, while the Bayes-optimal limit follows a much steeper -1 slope.
Figure 3: Log-log plot showing the alpha gap. The kernel methods (square/hinge) follow the -1/2 slope, while the Bayes-optimal limit follows a much steeper -1 slope.
Deep Insights & Future Outlook
The RAF model proves that memorization is not the enemy of generalization—it is a parallel objective.
Takeaways for Practitioners:
- Kernel Choice Matters: Kernels with higher nonlinear "weight" ($\mu_\star$) are better at handling datasets with many eccentricities or exceptions.
- Regularization is the Dial: $\lambda$ acts as a knob that shifts the model's focus from being a "logical reasoner" (large $\lambda$) to a "perfect librarian" (small $\lambda$).
Limitations: The current model uses fixed features. In real-world Transformers, the "features" change during training. The authors point to this "Feature Learning" as the next frontier for the RAF model to explain how models might reach the $\alpha^{-1}$ efficiency limit.
In a charming post-script, the authors reveal that the initial idea for the RAF model was sparked by a conversation with ChatGPT-4o, which "hallucinated" a paper that didn't exist, leading the researchers to build the model for real. It seems the rule-following model was actually inspired by a factual exception!