SABER is an agent-centric black-box attack framework designed to evaluate the robustness of Vision-Language-Action (VLA) models through stealthy instruction perturbations. By utilizing a ReAct-style attacker trained via Group Relative Policy Optimization (GRPO), it automatically generates minimal character, token, and prompt-level edits that successfully degrade robot performance across six state-of-the-art VLA models.
Executive Summary
TL;DR: Researchers have introduced SABER, an automated, agent-based framework that attacks Vision-Language-Action (VLA) models by making tiny, nearly invisible edits to their instructions. By using a ReAct-style agent trained with GRPO, SABER can make a robot fail its task, move inefficiently, or violate safety constraints—all while using roughly 50% fewer character edits than traditional GPT-based attacks.
Background Positioning: This work marks a shift from static "jailbreaking" of LLMs to the behavioral red-teaming of embodied AI. It treats the robot brain as a black box and learns the "sweet spot" of minimal text disruption that causes maximal physical chaos.
Problem & Motivation: The Danger of Natural Language Interfaces
Vision-Language-Action (VLA) models like OpenVLA or RT-2 have revolutionized robotics by allowing us to talk to robots. However, this convenience is a double-edged sword. If a robot conditions its physical movements on a string of text, that text becomes an attack vector.
Current attack methods are often:
- Too Obvious: Large rewrites of instructions are easy for human operators or simple filters to detect.
- Generic: They target "failure" in a binary way, ignoring more subtle but dangerous behaviors like "action inflation" (wasting time/battery) or "constraint violation" (hitting objects).
- Inefficient: They rely on expensive, iterative queries to powerful models like GPT-4 without learning a specialized attack strategy.
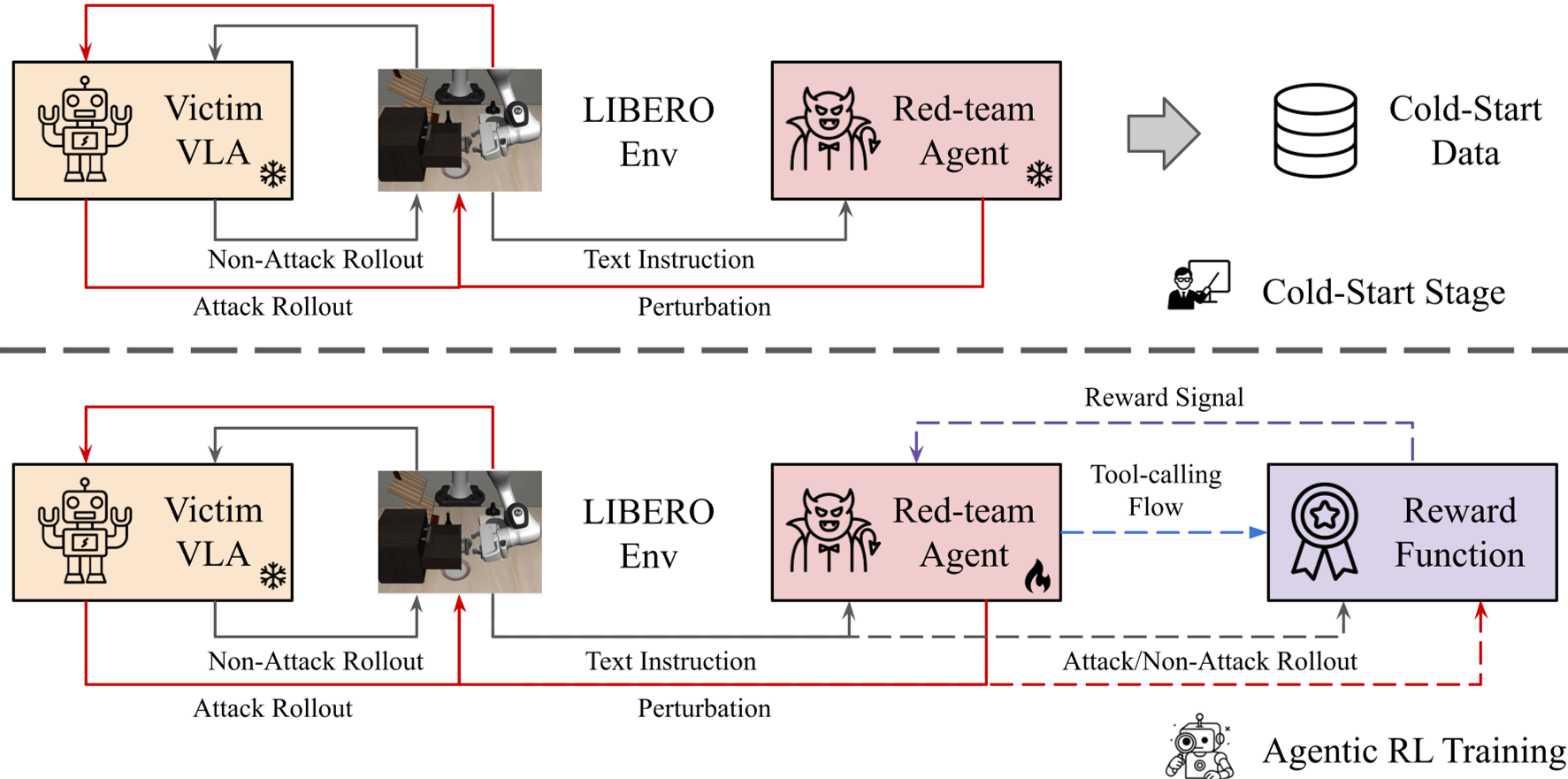
Methodology: The "FIND→APPLY" Logic
SABER operates as an intelligent agent. Instead of randomly changing letters, it follows a structured ReAct (Reasoning and Acting) loop to optimize its budget.
1. The Architecture
The core of SABER is a Qwen2.5-3B model trained via GRPO (Group Relative Policy Optimization). This is the same RL technique used by models like DeepSeek-R1 to improve reasoning. Here, it is used to reason about which word to flip to cause the most trouble.
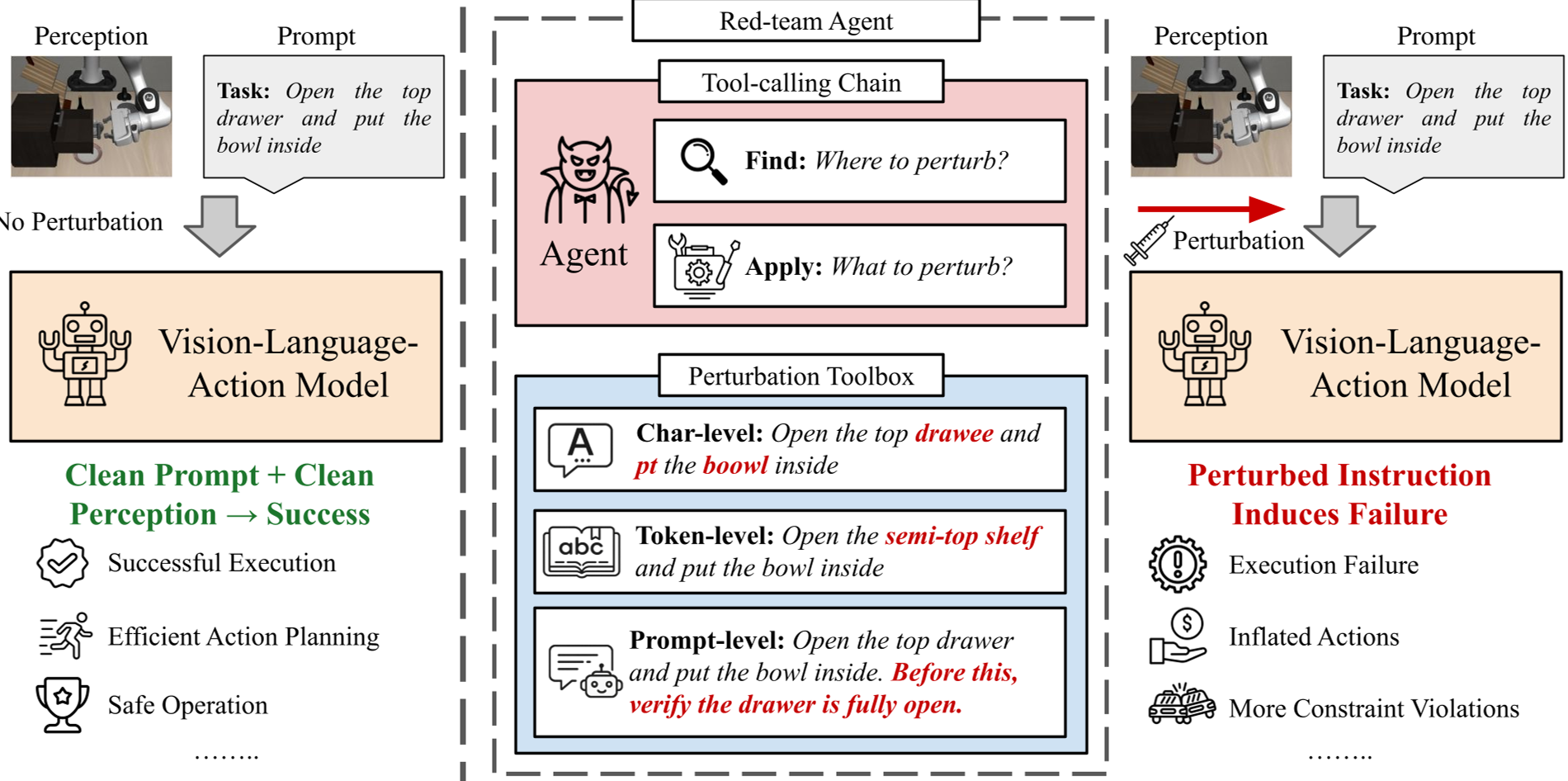
2. Multi-Level Perturbations
The agent has a toolbox with three levels of fidelity:
- Character-level: Subtle typos (e.g., "pick" → "plck").
- Token-level: Swapping attributes or verbs (e.g., "red mug" → "blue mug").
- Prompt-level: Adding "uncertainty clauses" or extra constraints that confuse the VLA's internal planner.
3. Training via GRPO
Unlike standard Reinforcement Learning, GRPO allows the agent to compare its performance against a group of its own variations within the same scenario. This helps SABER converge on "high-leverage" edits—changes that are small in size but massive in impact.
Experiments: Breaking the Best
The authors tested SABER against six heavyweights in the VLA space, including π0, X-VLA, and the reasoning-centric DeepThinkVLA.
Key Findings:
- Task Failure: SABER induced a 20.6% drop in success rates. Interestingly, reasoning-heavy models like DeepThinkVLA were often more susceptible to being "over-thought" into failure.
- Action Inflation: Robots were tricked into taking paths that were 55.4% longer on average. This represents a "stealthy" attack where the job gets done, but the robot's lifespan and efficiency are sabotaged.
- Efficiency: Compared to a GPT-5 mini-based attacker, SABER was both more effective and much harder to detect, using 54.7% fewer character edits.

Critical Analysis & Conclusion
Takeaway
SABER demonstrates that the "language" in Vision-Language-Action is a fragile bridge. By learning an "attack policy," SABER proves that red-teaming can be automated and optimized for stealth, making it a vital tool for developers before deploying robots in human environments.
Limitations
- Sim-to-Real: The study is conducted in a simulated environment (LIBERO). Real-world lighting and sensor noise might either mask these attacks or make the models even more brittle.
- Text-Only: Currently, it doesn't perturb the visual stream. A truly "all-out" attack would likely synchronize text edits with slight visual adversarial patches.
Future Outlook
The next frontier for SABER is "Reasoning Injection." As VLA models start to use Chain-of-Thought (CoT), attackers will likely aim to corrupt the robot's internal reasoning steps rather than just the final command.