This paper introduces the Expected Safety Impact (ESI) framework, a novel method for identifying and intervening in safety-critical parameters within Large Language Models (LLMs). By quantifying parameter sensitivity through a differentiable judge-guided strategy, the authors achieve State-of-the-Art (SOTA) safety alignment and preservation across various architectures, reducing attack success rates by over 50% with minimal parameter updates.
TL;DR
As LLMs become more integrated into specialized workflows, their safety alignment remains notoriously fragile—often "washing away" during task-specific fine-tuning. This paper introduces the Expected Safety Impact (ESI) framework, a surgical approach to locate and protect the specific parameters responsible for an LLM's refusal behaviors. By updating or freezing as little as 1% of the model, researchers can significantly boost safety or prevent its degradation without sacrificing performance.
Background: The Fragility of Alignment
The industry currently relies on RLHF (Reinforcement Learning from Human Feedback) to bake safety into models. However, this safety is "skin-deep." When a developer fine-tunes a safe model for a specific task (like medical QA or coding), the new gradients often overwrite the safety-critical weights, causing the model to become "unaligned."
The authors argue that the problem isn't the fine-tuning itself, but our blindness to where safety actually lives inside the billions of parameters.
Methodology: The ESI Metric
To find the "moral neurons," the authors developed the Expected Safety Impact (ESI). Unlike previous methods that looked at raw gradients or weight magnitudes, ESI uses the standard deviation of weights as a proxy for how much a parameter actually changes during tuning.
Breaking the Non-Differentiable Barrier
One major technical hurdle in calculating safety gradients is that text generation is discrete (choosing one token at a time), making it non-differentiable. The authors solved this using:
- Gumbel-Softmax Relaxation: Turning discrete token choices into a continuous, differentiable vector.
- Differentiable Judge: Using a secondary model (like Llama-Guard) to score safety and backpropagate that score through a Projection Matrix that bridges the vocabulary gap between the two models.
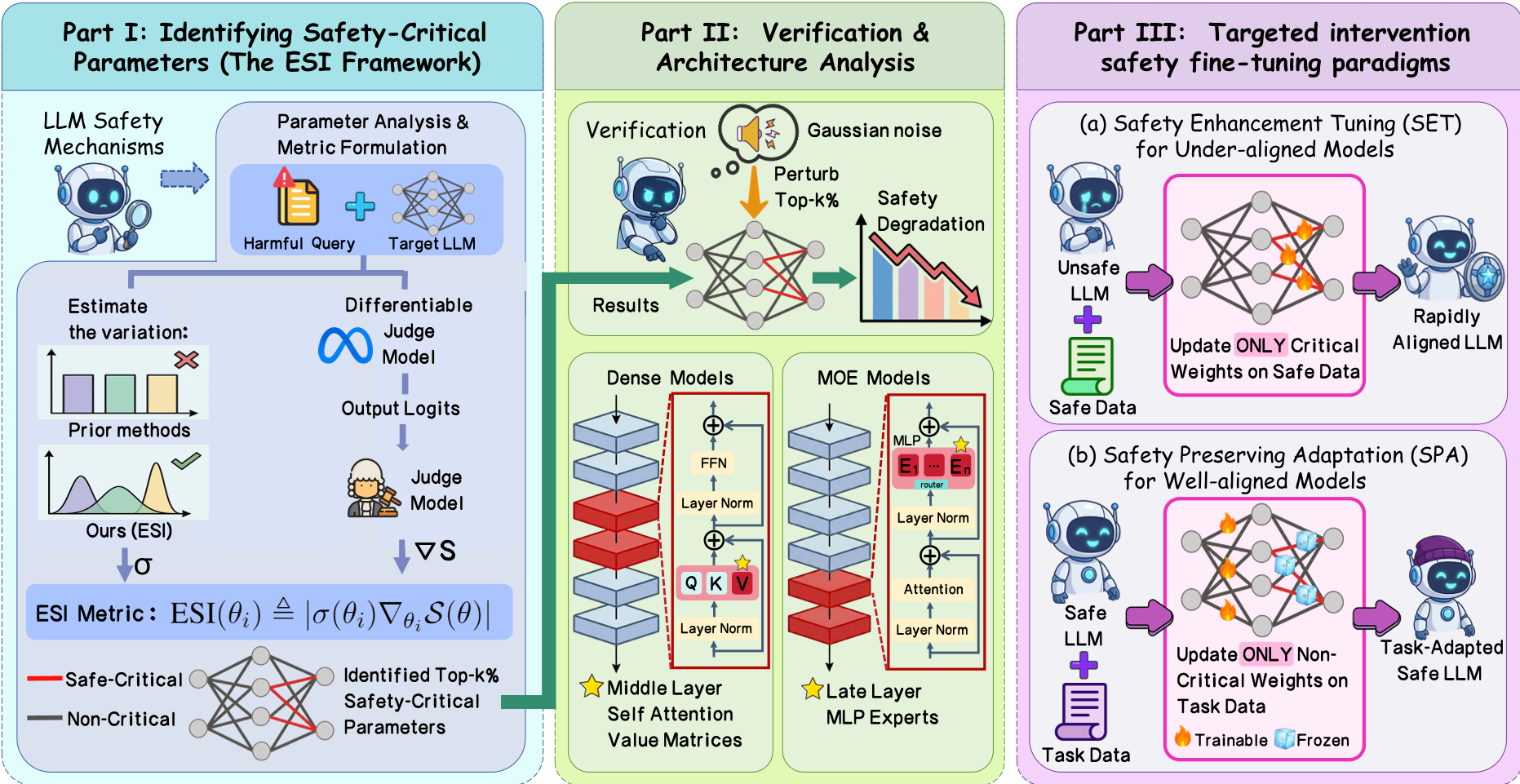 Figure 1: The ESI framework identifies critical weights, reveals architectural patterns, and enables targeted intervention.
Figure 1: The ESI framework identifies critical weights, reveals architectural patterns, and enables targeted intervention.
Key Insight: Dense vs. MoE Architectures
Perhaps the most fascinating discovery in the paper is that safety "migrates" depending on the model's architecture:
- Dense Models (e.g., Llama-3): Safety-critical parameters are concentrated in the middle layers, specifically within the Attention Value (V) matrices.
- Mixture-of-Experts (MoE) Models (e.g., Mixtral, Qwen3): Safety shifts toward the late-layer MLPs, primarily within the specific experts.
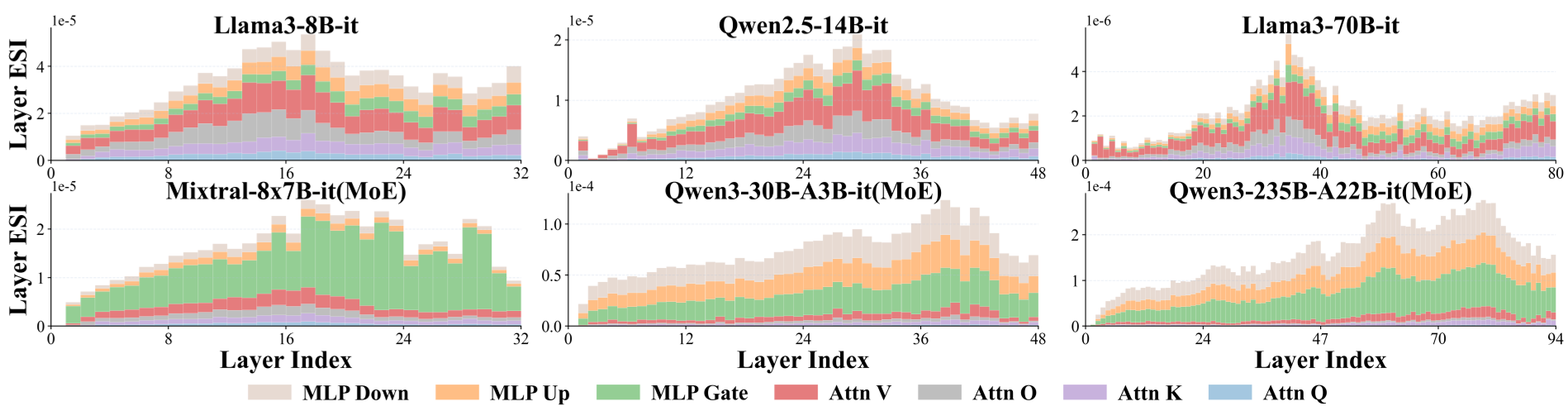 Figure 2: Aggregated ESI scores show how safety focus shifts from middle layers in dense models to late layers in MoE models.
Figure 2: Aggregated ESI scores show how safety focus shifts from middle layers in dense models to late layers in MoE models.
Targeted Intervention Paradigms
Armed with this map of safety-critical parameters, the authors proposed two workflows:
1. Safety Enhancement Tuning (SET)
For models that are inherently unsafe (base models), SET tunes only the top 1% of safety-critical parameters. This results in a massive drop in Attack Success Rate (ASR) while leaving the model's core knowledge (math, coding, logic) untouched.
2. Safety Preserving Adaptation (SPA)
When adapting a safe model to a new task, SPA freezes the identified safety parameters and only allows the model to learn on non-sensitive weights.
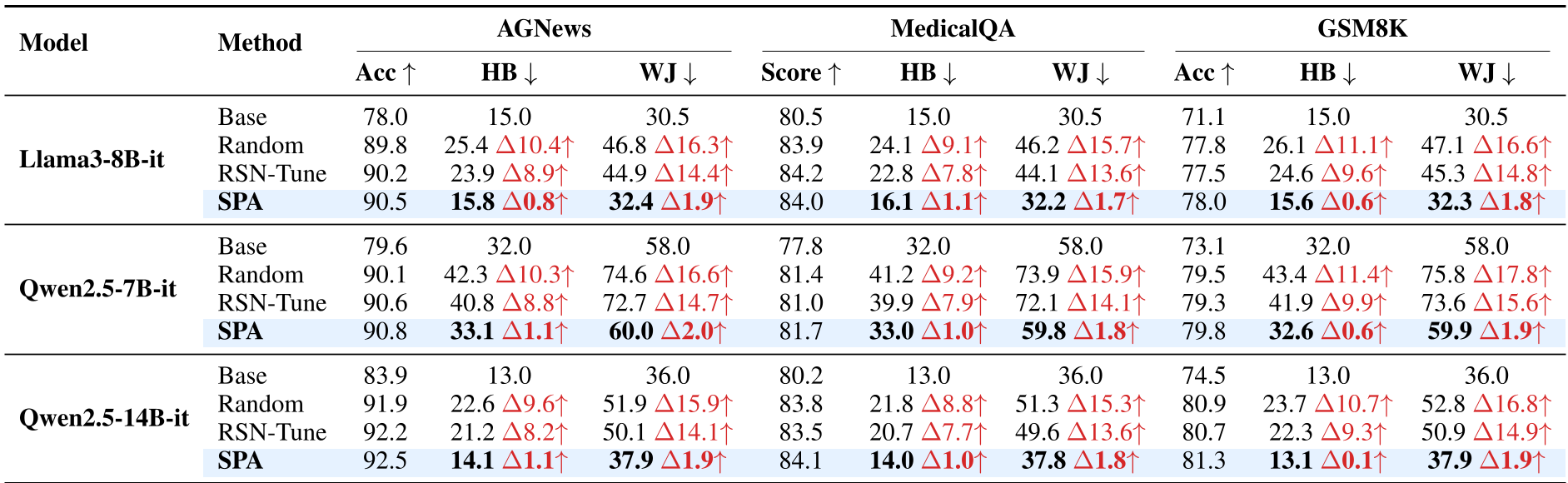 Table 1: SPA maintains safety (ASR remains low) while achieving utility scores comparable to standard fine-tuning.
Table 1: SPA maintains safety (ASR remains low) while achieving utility scores comparable to standard fine-tuning.
Critical Analysis & Conclusion
This work represents a move away from "brute-force" alignment toward "surgical" alignment. By proving that we only need to protect a tiny fraction of weights to maintain a model's integrity, this research paves the way for highly specialized yet robustly safe AI agents.
Limitations: The current framework requires access to model weights and gradients, meaning it cannot yet be applied to closed-source APIs like GPT-4o (except as a reference for open-source distillation).
Future Outlook: We expect to see "Safety Masks" become a standard part of LLM fine-tuning kits, ensuring that as models learn new skills, they don't lose their moral compass.