SAM 3D Animal is the first promptable framework designed for multi-animal 3D reconstruction from a single image. It utilizes the SMAL+ parametric model and a DETR-style set prediction paradigm to jointly reconstruct multiple instances, achieving state-of-the-art results on benchmarks like Animal3D, APTv2, and Animal Kingdom.
TL;DR
Reconstituting the 3D geometry of animals in the wild is a "Grand Challenge" due to occlusions and diverse species. SAM 3D Animal is the first end-to-end framework capable of reconstructing multiple animals simultaneously from a single image. By incorporating a promptable Transformer architecture and a dedicated multi-animal dataset (Herd3D), it achieves massive performance leaps—up to 80% mAP improvement on complex, out-of-distribution datasets.
Context: Why Animal 3D Vision is Lagging
While human mesh recovery (HMR) has reached a high level of maturity, animal 3D reconstruction has been stuck in the "single-object crop" era. Most current SOTA methods assume a single, centered animal with minimal occlusion. In reality, animals often appear in herds, interacting or obscuring one another. The lack of multi-instance 3D datasets and the inherent ambiguity of animal poses under occlusion have been the primary bottlenecks.
Methodology: Promptable Multi-Instance Transformers
The authors solve this by moving away from the "crop-and-reconstruct" pipeline towards a Set Prediction paradigm.
1. The Architecture
The model uses a ViT-Huge encoder and a SAM-style promptable Transformer decoder. Instead of predicting one subject, it generates 30 possible animal hypotheses in a single forward pass.
- Prompt Integration: It accepts 2D/3D keypoints and masks as "hints" to guide the attention mechanism towards specific instances.
- Bipartite Matching: Using the Hungarian algorithm, the model matches predictions to ground truth without needing NMS (Non-Maximum Suppression).
- Recursive Feedback: A layer-wise keypoint feedback loop allows the model to refine its geometric estimates across six decoder layers.
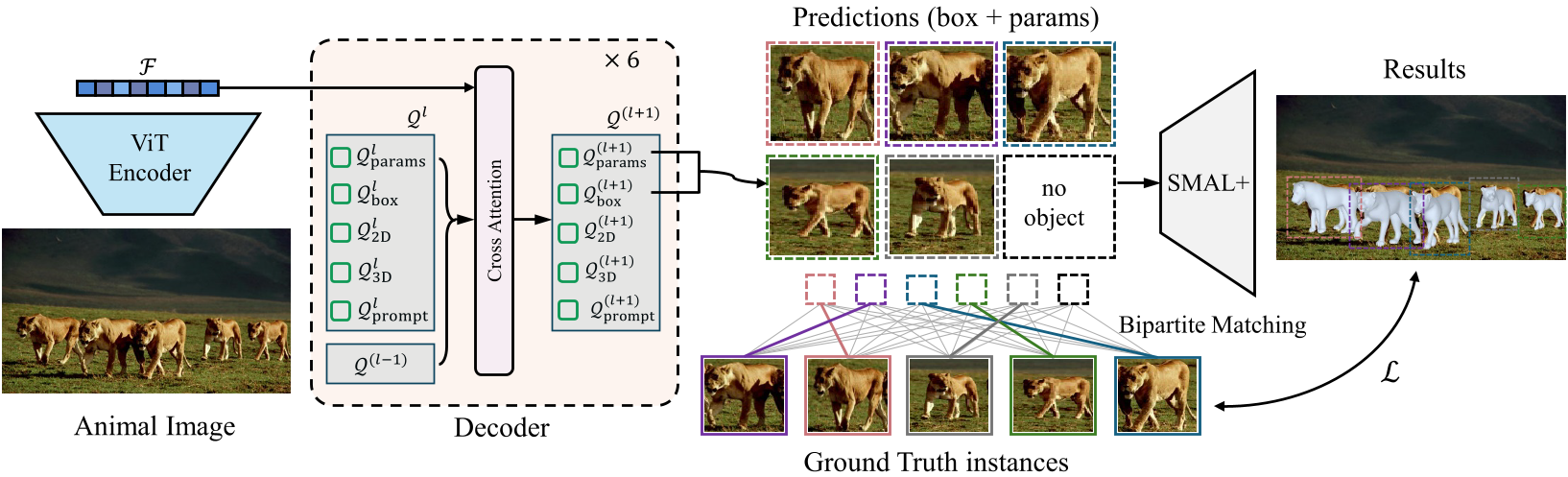 Figure 1: The SAM 3D Animal architecture, showcasing the promptable query tokens and the iterative refinement layers.
Figure 1: The SAM 3D Animal architecture, showcasing the promptable query tokens and the iterative refinement layers.
2. Herd3D: The Synthetic Solution
To train a multi-instance model, you need multi-instance data. The authors created Herd3D, a dataset of 5,000+ images. They used a sophisticated pipeline involving SMAL+ mesh sampling and Qwen-Image-ControlNet to generate realistic images of diverse species in group layouts with accurate occlusion ordering.
Experimental Results: Scaling with Prompts
The model was evaluated against baselines like AniMer and GenZoo. The results reveal a clear hierarchy of effectiveness:
- Zero-Prompt Power: Even without prompts, the model is SOTA on the OOD Animal Kingdom dataset (mAP 12.6 vs 10.4).
- The "Prompt Bonus": Adding detected keypoints (via ViTPose) or ground-truth keypoints pushes performance even higher. On APTv2, AP jumps from 49.4 to 57.4.
- Robustness to Occlusion: A key insight from the paper is that prompts matter most when visibility is low. In high-occlusion scenarios, prompts provide the necessary spatial prior to "guess" the invisible parts of the animal correctly.
 Figure 2: Qualitative comparison showing SAM 3D Animal's superior alignment and multi-instance handling compared to previous model-based and model-free methods.
Figure 2: Qualitative comparison showing SAM 3D Animal's superior alignment and multi-instance handling compared to previous model-based and model-free methods.
Deep Insights & Takeaways
- Keypoint over Mask: Ablation studies show that keypoint prompts are significantly more effective than masks. This makes physical sense: keypoints define the internal skeletal structure (the "Why" of the pose), whereas masks only provide the silhouette (the "Where").
- Monotonic Scaling: Performance increases linearly with the number of provided keypoints. This allows the model to be used flexibly in "Human-in-the-loop" scenarios where a user can add a few dots to fix a difficult reconstruction.
- Inductive Bias: By utilizing the SMAL+ parametric model, the network maintains a strong anatomical prior, preventing the "geometric melting" often seen in model-free approaches under heavy occlusion.
Conclusion and Future Work
SAM 3D Animal represents a significant step towards "Animal 3D in the Wild." While it currently excels at quadrupeds, the reliance on the SMAL+ template means it struggles with birds or non-mammalian shapes. Future iterations that incorporate more flexible representations (like 3D Gaussians or Neural Radiance Fields) within this promptable framework could truly revolutionize wildlife monitoring and digital media creation.
Takeaway: If you have limited data and complex occlusions, don't just build a bigger model; build a model that knows how to listen to external prompts.