SAMA (Factorized Semantic Anchoring and Motion Alignment) is a novel instruction-guided video editing framework that improves semantic precision and temporal coherence by disentangling structural planning from motion modeling using a Diffusion Transformer (DiT) backbone. It achieves state-of-the-art results among open-source models, rivaling commercial systems like Kling-Omni and Runway Gen-3.
TL;DR
Instruction-guided video editing often feels like a zero-sum game: you either get the edit right but lose the motion, or keep the motion but fail the instruction. SAMA (Semantic Anchoring and Motion Alignment) breaks this cycle. By factorizing video editing into two distinct capabilities—Semantic Anchoring for structural planning and Motion Alignment for temporal reasoning—SAMA achieves SOTA performance that rivals top-tier commercial engines like Runway and Kling.
Context: The Bottleneck of External Priors
Standard video editing pipelines often lean on "crutches" such as depth maps, Canny edges, or skeletal priors to keep frames aligned. While effective, these external conditions are expensive to compute and often fail in complex scenarios. SAMA’s authors argue that a truly robust editor should internalize these representations. The core challenge is the lack of factorization; the model tries to learn "what to change" and "how to move" simultaneously from limited paired data, leading to "texture popping" and identity drift.
Methodology: The Power of Factorization
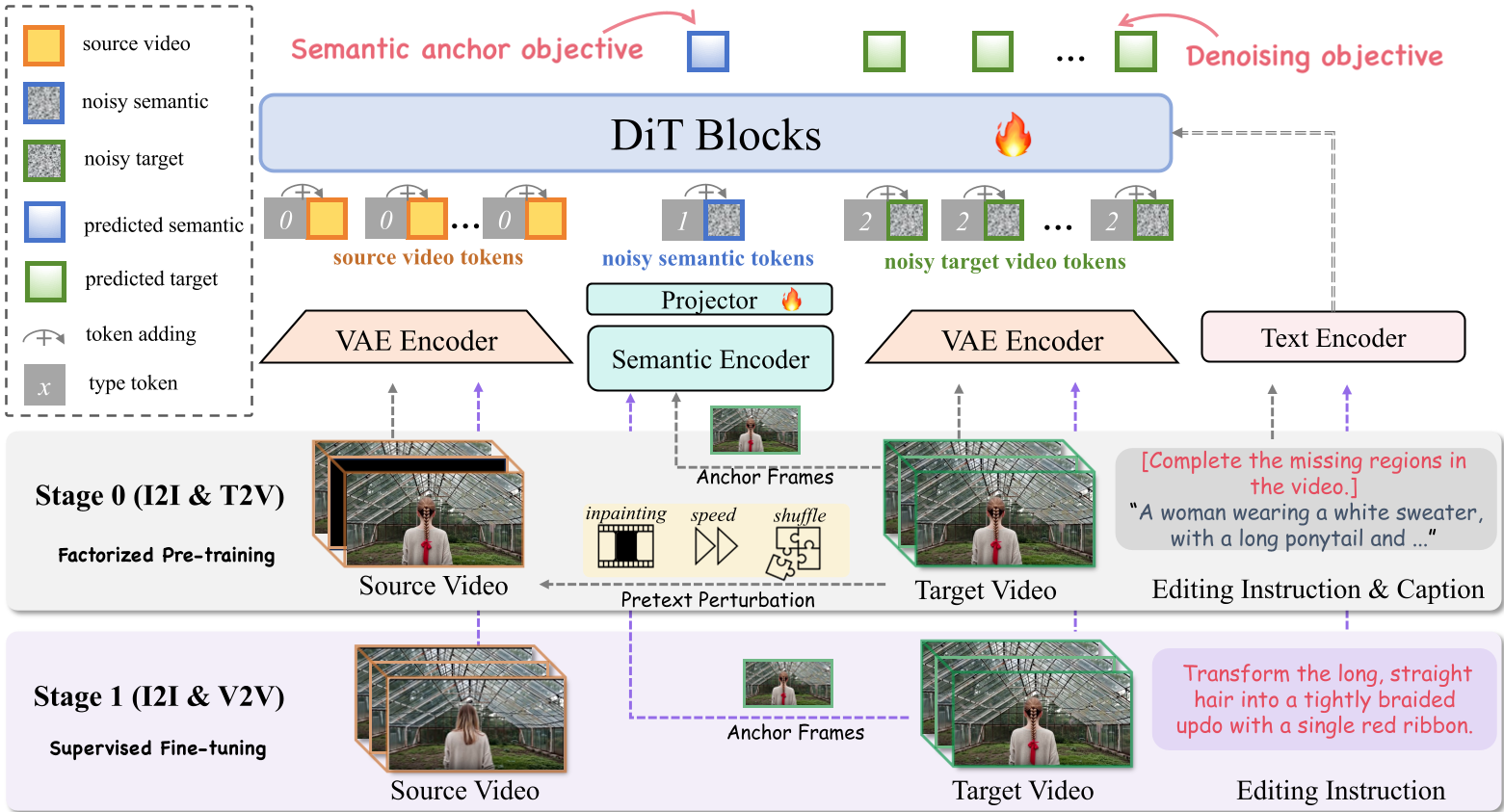
SAMA treats the Diffusion Transformer (DiT) as a dual-purpose engine. It employs a two-stage training strategy that begins with Factorized Pre-training (Stage 0) followed by Supervised Fine-tuning (Stage 1).
1. Semantic Anchoring (SA)
To fix the "what," SAMA uses sparse anchor frames. It doesn't just predict pixels; it jointly predicts high-level semantic tokens (extracted via a SigLIP encoder). This forces the DiT to perform instruction-aware structural planning in a semantic space before rendering the high-fidelity latent details.
2. Motion Alignment (MA)
To fix the "how," SAMA turns to self-supervised learning. By applying "disturbances" to raw videos—such as masking temporal blocks (Cube Inpainting), speeding up clips (Speed Perturbation), or shuffling spatial-temporal segments (Tube Shuffle)—the model learns to "heal" motion. This allows the backbone to understand physical dynamics without ever seeing a single human-authored edit.
Experiments: Breaking Records
The results are striking. Even in the Stage 0 (Zero-shot) phase, before seeing any paired video-editing data, SAMA already demonstrates a strong ability to follow instructions. Once fine-tuned (Stage 1), it dominates open-source leaderboards.
Key Quantitative Wins:
- Swap/Change Tasks: Achieved a 9.34 score, beating leading open-source models by a wide margin.
- Convergence: The Semantic Anchoring objective acts as a regularizer, leading to significantly faster convergence and more stable training compared to standard DiT baselines.

Visual Evidence:
As seen in the figure above, SAMA handles complex instructions like "changing a pigeon to a squirrel" while maintaining the background motion perfectly—a task where other models often blur the environment or fail to ground the squirrel correctly in the 3D space.
Critical Insights: Why it Works
The "Secret Sauce" of SAMA lies in its Type Embeddings. Instead of using complex positional shifts, the authors assigned unique IDs to source latents, target latents, and semantic tokens. This "Multi-modal In-context" approach allows the DiT to distinguish between the "reference" and the "output" while sharing the same weights, maximizing the transfer of knowledge from large-scale pre-training.
Conclusion & Limitations
SAMA represents a major step toward open-source parity with commercial video editors. It proves that we don't need more complex adapters; we need more intelligent training objectives that respect the natural factorization of video.
Limitations: Despite its power, SAMA still faces hurdles in extremely fast-motion scenarios and ultra-long video sequences where temporal drift can eventually accumulate. Future iterations will likely focus on even stronger semantic tokenization and long-context scaling.
Paper Title: SAMA: Factorized Semantic Anchoring and Motion Alignment for Instruction-Guided Video Editing Key Contributions: Factorized pre-training, Semantic Anchoring, Motion-centric restoration tasks.