本文提出了 SAVOIR,一种基于合作博弈论的社会化强化学习(Social RL)框架。该方法通过引入 Expected Utility 进行前瞻性估值,并利用 Shapley Value 实现公平的信用分配(Credit Assignment),在 SOTOPIA 基准测试中刷新了 SOTA 纪录,其 7B 模型性能甚至比肩 GPT-4o 和 Claude-3.5-Sonnet。
1. 核心速览 (Executive Summary)
TL;DR:提升 AI 的社交“情商”不应只靠模仿人类对话。本文提出的 SAVOIR (ShApley Value fOr SocIal RL) 框架,首次将合作博弈论中的 Shapley Value 引入社交强化学习。它不仅看一句对话在当下“好不好听”,更通过前瞻性模拟(Future Rollout)看它是否“铺好了路”。
背景定位:这是社交 Agent 领域的一个重要突破。它证明了通过严谨的数学归约(而非仅仅靠提示词工程),可以让 7B 的小模型在复杂的谈判、说服和协作任务中,战胜参数量巨大的 GPT-4o 和专门的推理模型(如 DeepSeek-R1)。
2. 痛点深挖:为什么社交智能很难? (Problem & Motivation)
当前的社交智能体训练通常面临两个瓶颈:
- 回顾式偏见(Retrospective Bias):现有的奖励模型往往在对话结束后才给出评分。这就像是在事后诸葛亮,无法识别出对话中那些“虽然现在看起来平淡,但却在几轮后反杀”的关键伏笔。
- 信用分配(Credit Assignment)的随意性:当一场谈判成功时,到底是因为第一句的礼貌,还是最后一句的让步?如果只是简单地让 LLM 凭感觉分摊奖励,缺乏公平性和准确性。
作者由此产生直觉:社交互动本质上是一场合作博弈。每一句对话都是一个“玩家”,它们共同协作来最大化最终的社交收益。我们需要一种方法,能准确量化每一句话对未来成功可能性的真实边际贡献。
3. 方法论详解:SAVOIR 的核心机制 (Methodology)
SAVOIR 框架的核心可以概括为两步:“看远一点”和“分细一点”。
A. 前瞻性估值 (Expected Utility)
SAVOIR 不再单纯评估对话的历史,而是计算预期效用。给定当前的一个话语子集,它会进行多次 Monte Carlo 模拟(Rollouts),模拟从这一步开始,未来可能的对话走向。 这种做法捕捉了一句话的“战略潜力”——即使现在还没达成协议,但如果它让未来的协商空间变大了,它的价值就应该更高。
B. 基于 Shapley 值的公平分配
有了估值函数后,关键是如何分配奖励。SAVOIR 采用了 Shapley Value,这是博弈论中唯一满足效率、对称性、零贡献和加性四大公理的分配方法。
 图 1: SAVOIR 框架流程。从对话中采样话语联盟,通过 Rollout 评估预期价值,最后解加权线性回归得到 Shapley 值。
图 1: SAVOIR 框架流程。从对话中采样话语联盟,通过 Rollout 评估预期价值,最后解加权线性回归得到 Shapley 值。
为了解决计算量随话语数量指数增长的问题,作者引入了 KernelSHAP。它通过优先采样极小规模(评估独立影响)和极大规模(评估协同效应)的话语子集,极大地提高了计算效率。
4. 实验与结果 (Experiments & Results)
SAVOIR 在 SOTOPIA 基准测试中展现了统治级的性能:
- 超越巨头:其 7B 模型在 SOTOPIA-Hard 任务中,Goal 评分(目标达成率)达到了 7.18,显著超过了 GPT-4o 的 6.97。
- 推理模型的滑铁卢:有趣的是,像 OpenAI-o1 或 DeepSeek-R1 这样擅长数学和逻辑的推理模型,在社交任务上表现欠佳(例如 o3-mini 的 Goal 评分仅为 5.14)。
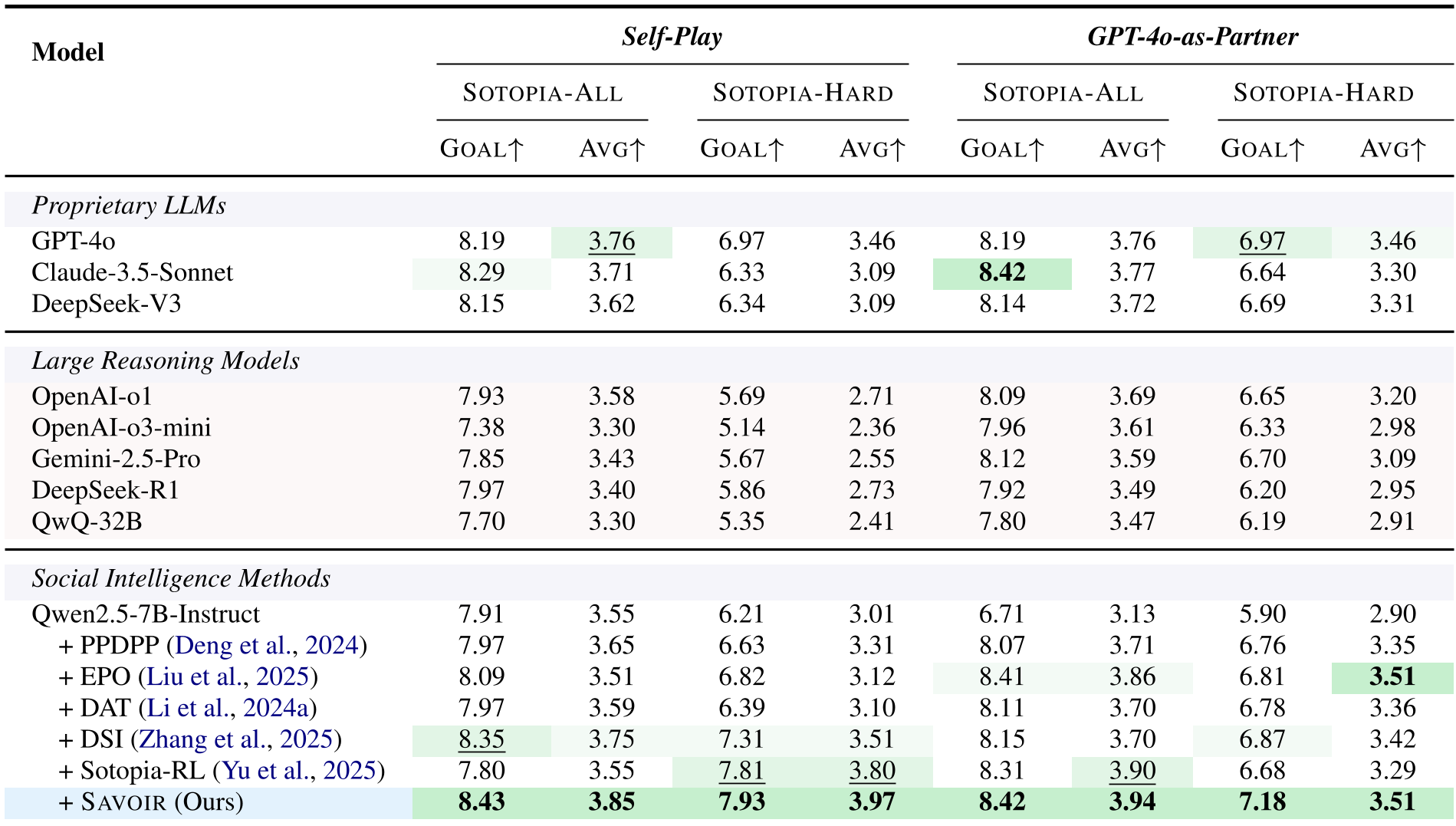 表 1: 不同模型在 SOTOPIA 上的表现对比。SAVOIR(最底行)在所有指标上均处于领先地位。
表 1: 不同模型在 SOTOPIA 上的表现对比。SAVOIR(最底行)在所有指标上均处于领先地位。
消融实验 (Ablation Study): 实验证明,Expected Utility (EU) 和 Shapley Value 缺一不可。只用 EU 提升了 3.1%,只用 Shapley 提升了 4.2%,而两者的组合(SAVOIR)则实现了 7.5% 的跨越式增长,证明了前瞻视野与公平归因的互补性。
5. 深度洞察:为什么推理模型社交不行? (Critical Analysis)
论文中一个非常深刻的观察是:社交智能与分析性推理是质性不同的能力。 推理模型倾向于冗长的思维链(CoT)和严密的逻辑推导,但在社交场合,过度思考可能导致反应迟钝或缺乏直觉。真正的社交高手往往依赖于一种“社交直觉”(Social Savoir-Faire),这种直觉在 SAVOIR 中被数学化地表达为对话语边际贡献的敏感度。
案例研究:诚实的推销
在一个家具销售案例中,SAVOIR 奖励了那些愿意诚实交代缺陷并主动提供解决方案的智能体。这比单纯的礼貌(Surface Politeness)更高一级,体现了战略透明性。
6. 总结与展望 (Conclusion)
Takeaway: SAVOIR 的成功告诉我们,AI 的社交能力不必仅仅依赖于“多读人类剧本”,通过博弈论引导的强化学习,可以在更小的参数量下实现更高级的战略行为。
局限性与未来: 虽然 SAVOIR 很强,但它在面对 Gemini-3-Pro 等顶级对手时性能仍有下降。未来的方向可能在于“课程学习”(Curriculum Learning),通过不断提升对手的社交段位来训练 AI 的极限博弈能力。此外,跨文化社交的复杂性也是该研究下一步需要攻克的堡垒。
本文主编评论:SAVOIR 的核心意义在于,它将“社交智慧”这一感性概念拆解成了“预期效用”和“边际贡献”这两个理性维度。这不仅是学术上的 SOTA,更为未来开发具备谈判和协作能力的商业 Agent 提供了坚实的底层方法论。