Scal3R is a scalable 3D reconstruction framework designed for kilometer-scale scenes from long RGB video sequences. It introduces a neural global context representation and a test-time training (TTT) mechanism to achieve state-of-the-art accuracy in both camera pose estimation and geometric reconstruction.
TL;DR
Reconstructing a kilometer-long scene from a simple RGB video is a nightmare for standard Transformer-based models due to memory constraints. Scal3R breaks this barrier by introducing "Adaptive Memory Units" that learn from the scene during the reconstruction process (Test-Time Training). This allows it to maintain global consistency over thousands of frames, achieving SOTA pose accuracy and dense 3D maps where previous models simply "drifted away."
The Problem: The "Short-Sightedness" of Chunk-based Models
Recent 3D foundation models like DUSt3R and VGGT have moved us toward "feed-forward" reconstruction—directly regressing 3D points from pixels. However, they face a fundamental trade-off:
- Full Attention: Quadratic cost means you can only process a few dozen frames.
- Divide-and-Conquer: Breaking the video into chunks saves memory but loses global context. Without knowing what happened 500 meters ago, the model cannot correct local errors, leading to catastrophic trajectory drift in large-scale scenes.
Methodology: Test-Time Training as Infinite Memory
The core innovation of Scal3R is treating the Global Context not as a fixed vector (like in RNNs), but as a set of weights in a lightweight neural network.
1. Global Context Memory (GCM)
Instead of discarding information from previous chunks, Scal3R uses Adaptive Memory Units (AMUs). During inference, the model performs a "fast update" (an inner-loop optimization) to encode the current chunk's geometry into these weights. This effectively creates a high-capacity, non-linear memory bank that informs the reconstruction of subsequent frames.
2. Global Context Synchronization (GCS)
To make this scalable across multiple GPUs, the authors utilize a "context parallelism" strategy. Each GPU handles a different chunk but synchronizes its "learned memory" through gradient summation (All-Reduce). This ensures that a landmark seen on GPU 1 can help GPU 8 align its local points correctly.
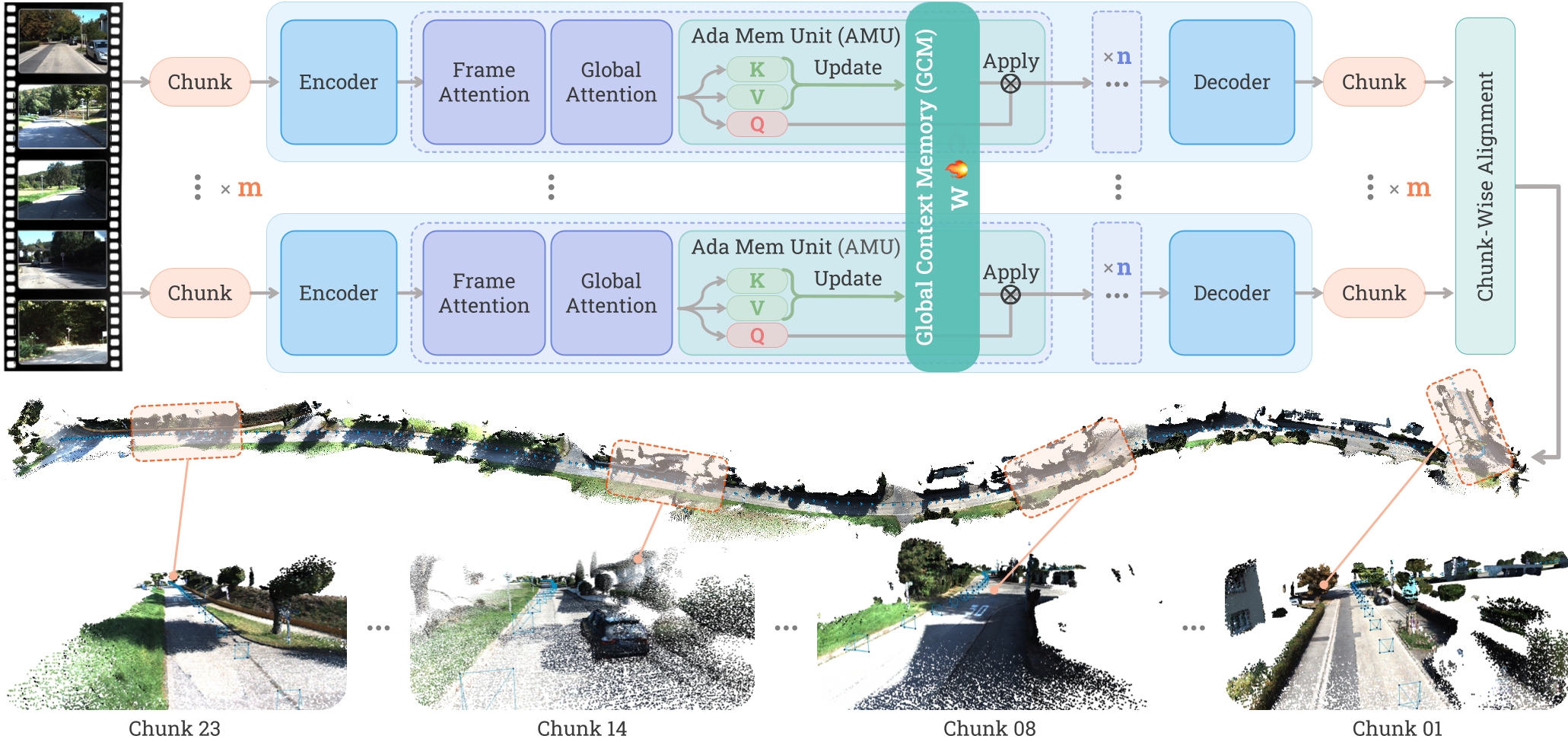 Figure 1: The Scal3R pipeline divides the sequence into overlapping chunks, using the GCM module to synchronize global context across GPUs.
Figure 1: The Scal3R pipeline divides the sequence into overlapping chunks, using the GCM module to synchronize global context across GPUs.
Experiments: Breaking the KITTI Benchmark
Scal3R was tested on massive datasets including KITTI Odometry (urban driving) and Oxford Spires (complex loops).
- Pose Accuracy: In the KITTI benchmark, Scal3R achieved an ATE of 14.55, nearly doubling the accuracy over the competitive VGGT-Long (25.94).
- Geometric Fidelity: On ETH3D, Scal3R reached an F1-score of 0.91, outperforming traditional SLAM systems and earlier learning-based models that often fail in textureless or large-scale environments.
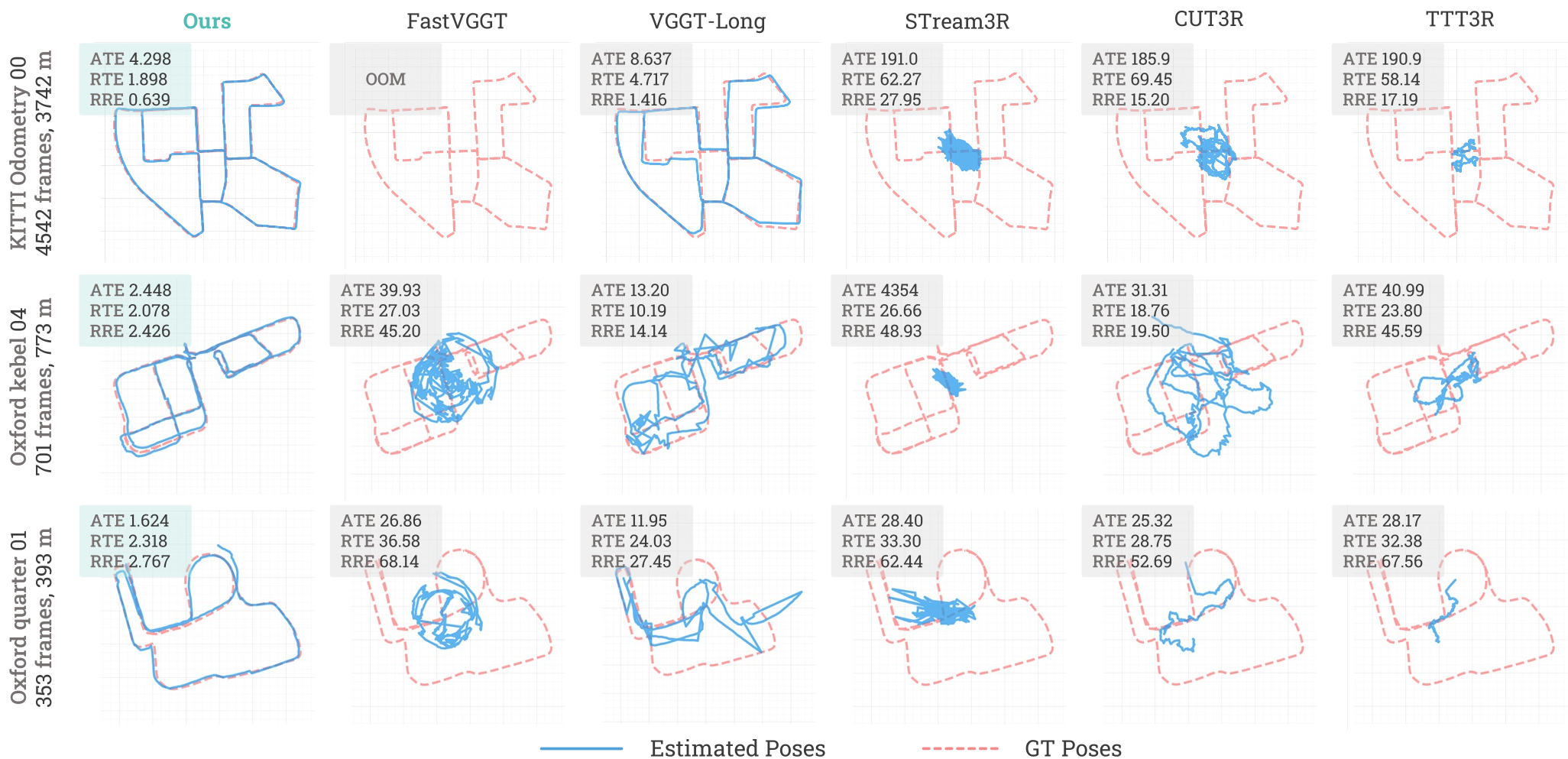 Figure 2: Trajectory comparison on KITTI. Note how Scal3R (red) maintains the global structure with minimal drift compared to baselines.
Figure 2: Trajectory comparison on KITTI. Note how Scal3R (red) maintains the global structure with minimal drift compared to baselines.
Critical Insights: Why it Works
The success of Scal3R lies in its Inductive Bias. By combining a strong pre-trained geometry backbone (VGGT/DINOv2) with a dynamic adaptation layer (TTT), it mirrors human perception: we maintain a "rough global map" while focusing on "fine local details."
The ablation studies prove that State Size matters—increasing the AMU parameters from 1M to 4M consistently improved pose accuracy, confirming that 3D scenes require more representational "surface area" than simple language tasks.
Conclusion & Future Look
Scal3R represents a shift from "static" foundation models to "adaptive" ones. While it still struggles with abrupt lighting changes (appearance inconsistency), it paves the way for autonomous agents that can map kilometer-wide cities using nothing but a standard camera and a few GPUs.
Key Takeaway: Don't just increase the context window; increase the memory's intelligence through Test-Time Training.