The paper introduces MOSAIC, a scaling-aware data selection framework designed for End-to-End (E2E) autonomous driving. It combines data clustering, importance ranking, and neural scaling laws to optimize training mixtures, achieving SOTA performance on NAVSIM and OpenScene benchmarks while using up to 80% less data.
Executive Summary
Large-scale deep learning for Physical AI—such as End-to-End (E2E) autonomous driving—is a data-hungry endeavor. However, blindly collecting millions of hours of driving footage is computationally prohibitive and often leads to diminishing returns.
The core challenge is "Metric Competition." An autonomous vehicle isn't just trying to minimize a single loss function; it must simultaneously comply with traffic laws, ensure passenger comfort, and maintain progress. A specific dataset might help the model handle roundabouts better while inadvertently making its braking behavior more erratic.
In this work, researchers from NVIDIA and NYU present MOSAIC (Mixture Optimization via Scaling-Aware Iterative Collection). MOSAIC treats data selection not as a simple search for "diversity," but as a mixture optimization problem guided by the mathematical "scaling laws" of different data domains.
Perspective: This paper shifts the paradigm from "Maximum Diversity" (Coreset) or "Maximum Uncertainty" to "Maximum Utility Gain per Sample."
The Motivation: Why Random Sampling Fails Physical AI
In Large Language Models (LLMs), "Scaling Laws" have successfully predicted how performance improves with more tokens. However, Physical AI introduces three complications:
- Conflicting Metrics: Models are evaluated on an aggregate of many scores (e.g., the 9 metrics of EPDMS).
- Heterogeneous Influence: A clip of a busy intersection impacts collision avoidance more than a clip of a desert highway.
- Partition Ambiguity: Unlike "Code" vs "English" in LLMs, driving scenes aren't always naturally separated into clean domains.
Current SOTA methods like Chameleon or Coreset ignore these scaling dynamics, often selecting redundant data that doesn't move the needle on the metrics that actually need improvement.
Methodology: The MOSAIC Pipeline
MOSAIC solves the data selection problem in three distinct stages, as illustrated in the architecture below:
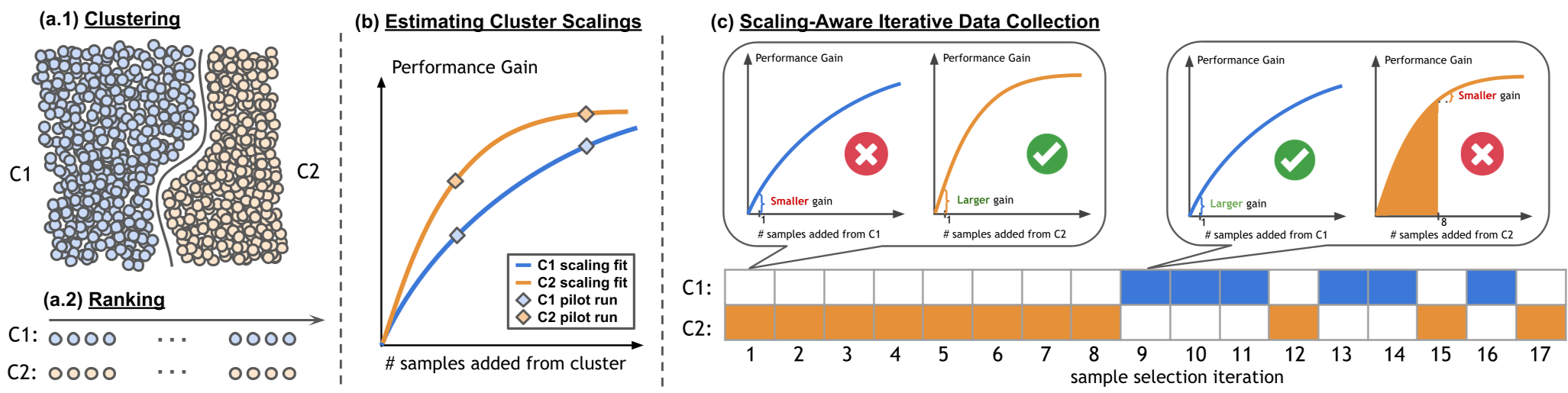
1. Clustering & Ranking
The data pool () is first partitioned into domains (e.g., by city or semantic captions). Within each cluster, samples are ranked using an Importance Score (), defined by how much the current model struggles with that specific sample.
2. Modeling Scaling Laws
This is the "brain" of the method. The authors fit a saturating exponential scaling law for each domain: By running small "pilot runs," they determine (the potential total improvement a domain can offer) and (how quickly that domain's benefit saturates).
3. Iterative Collection
Instead of picking all data at once, MOSAIC adds samples one-by-one. It selects the next sample from the domain that currently has the highest marginal gain—the steepest part of its scaling curve. As a domain's curve flattens (saturates), MOSAIC automatically pivots to another domain that still offers high growth.
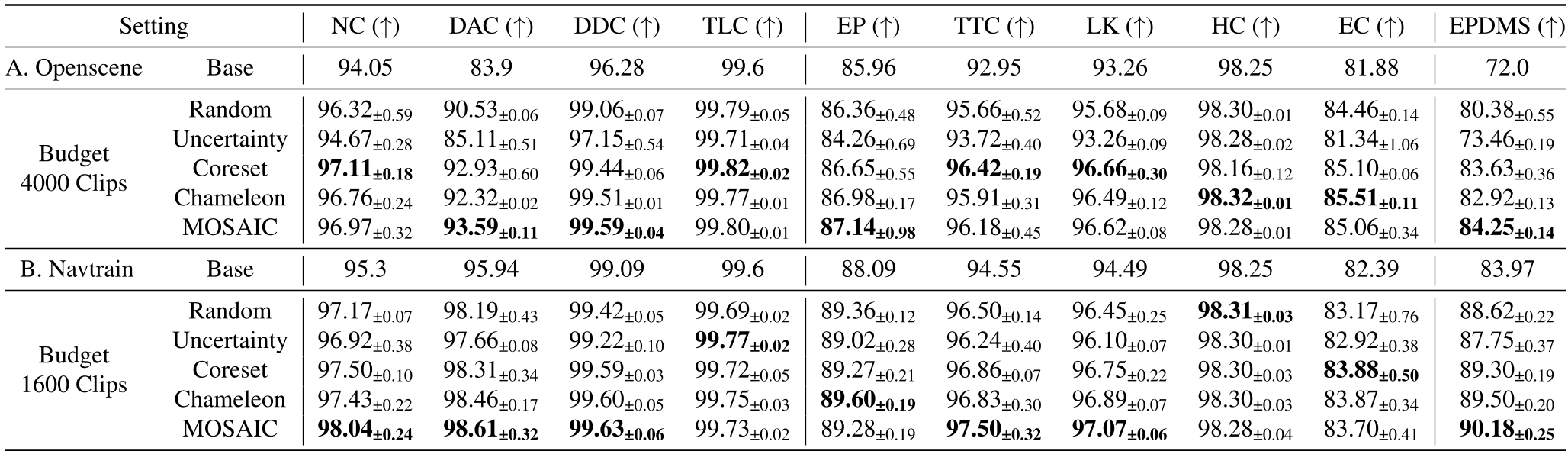
Experiments: Massive Efficiency Gains
The framework was tested using the Hydra-MDP model on the OpenScene and Navtrain datasets, evaluating it on the Extended Predictive Driver Model Score (EPDMS).
SOTA Comparison
MOSAIC outperformed all baselines (Random, Uncertainty, Coreset, Chameleon) across every budget. In the OpenScene experiment, it achieved superior driving performance with 82% less data than random sampling.
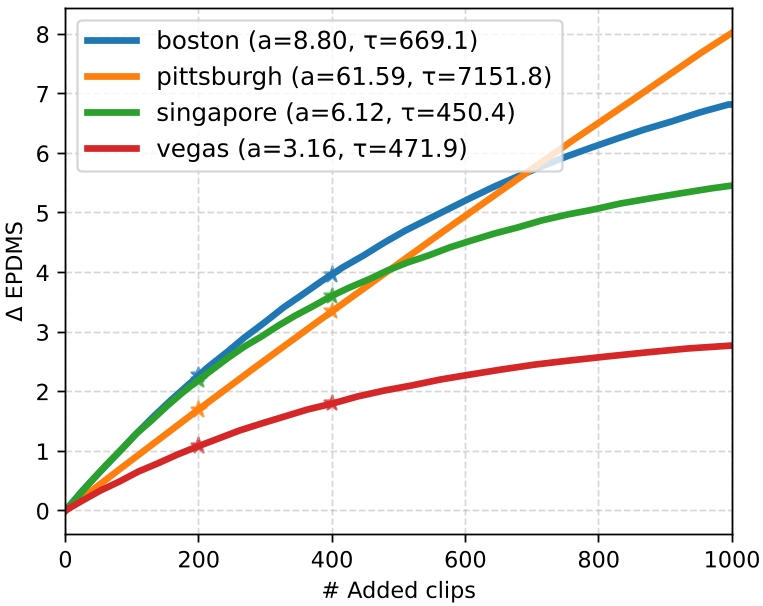
Visualizing the Selection Strategy
One of the most insightful findings is how MOSAIC shifts its attention over time. In OpenScene, it initially mines heavily from Boston and Singapore because those domains offer high initial gains (steep curves). Once those are exhausted, it pivots to Pittsburgh, which has a steadier, long-term improvement rate.
Critical Analysis & Insights
Why does it work?
MOSAIC's success stems from its ability to disentangle domain local effects. Most active learning methods try to find "globally difficult" samples. MOSAIC realizes that difficulty is domain-specific and that some metrics saturate faster than others. By modeling this saturation explicitly, it avoids wasting the compute budget on "more of the same."
Limitations
- Linear Separability Assumption: The method assumes that the total utility is roughly the sum of individual domain effects. If there are massive cross-domain interactions, the model might over-allocate data.
- Pilot Run Overhead: You need to train several small proxy models to fit the scaling laws. However, the authors show this cost is amortized quickly in large-scale training.
Conclusion
MOSAIC provides a principled blueprint for the "Data Era" of Autonomous Driving. It proves that by understanding the physics of scaling, we can build safer, more competent AI systems while significantly reducing the environmental and financial cost of large-scale deep learning.
Key Takeaway: Don't just collect more data—collect data that maximizes your marginal utility along the scaling curve.