The paper introduces a novel framework for grounding fragmented, non-overlapping partial 3D reconstructions to a complete pseudo-synthetic reference model. By leveraging 3D Gaussian Splatting (3DGS) and semantic feature-based optimization, the method achieves globally consistent alignment for "in-the-wild" imagery where traditional SfM fails, establishing a new SOTA on the proposed WikiEarth benchmark.
Executive Summary
TL;DR: The researchers propose a system to unify disjoint 3D reconstructions of landmarks using "oracle" reference models from Google Earth. By embedding DINOv2 semantic features into 3D Gaussian Splatting (3DGS), they can align real-world "in-the-wild" photos to synthetic-looking reference models, even when the image sets have zero visual overlap.
Background Positioning: This work addresses a fundamental limitation of Structure-from-Motion (SfM). While SfM excels at local geometry, it struggles with "unconnected" sets of images. This paper provides the "glue" that connects these islands of 3D data, positioning itself as a robust refinement and registration layer for large-scale scene understanding.
The Problem: The "Disconnected Islands" of SfM
Current reconstruction pipelines (like COLMAP) rely heavily on visual overlap. If you have 500 photos of the front of the Milan Cathedral and 50 of the back, SfM often produces two separate 3D models with no way to know their relative positions. Modern transformer-based methods (DUSt3R, VGGT) often try to "guess" the relative pose but frequently fail or produce "ghosting" artifacts in large-scale outdoor environments.
The technical challenge is twofold:
- Lack of Overlap: There is no visual bridge between image sets.
- Domain Gap: Reference models (like those from Google Earth) are "pseudo-synthetic"—they have the correct geometry but look nothing like a high-res iPhone photo taken at sunset.
Methodology: Semantic-Aware Inverse Optimization
The core insight is that while a synthetic rendering and a real photo look different (photometrically), they are semantically identical (a window is a window).
1. Semantic 3D Gaussian Splatting
The authors represent the reference model using 3D Gaussian Splatting (3DGS). Each Gaussian is augmented with a semantic feature vector distilled from DINOv2. This allows the model to "render" not just colors, but high-dimensional semantic signatures.
2. Inverse Optimization with LTS
Instead of adjusting the model, they keep the reference model fixed and optimize the 6DoF pose + scale (7 parameters) of the partial reconstruction. To handle the messy nature of internet photos (people, cars, occlusion), they use Least Trimmed Squares (LTS). This robust optimization selectively ignores images that don't match the model well, preventing outliers from pulling the registration off-target.
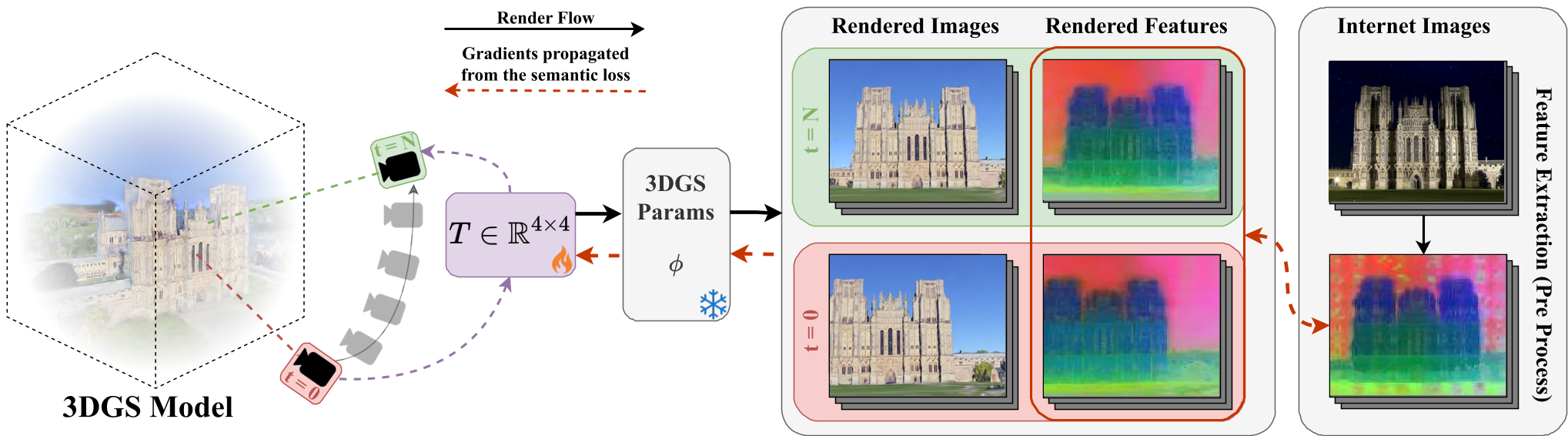 Caption: The Scene Grounding framework optimizing the alignment T by minimizing semantic feature loss between rendered views and internet images.
Caption: The Scene Grounding framework optimizing the alignment T by minimizing semantic feature loss between rendered views and internet images.
Experiments and Results
The authors introduced WikiEarth, a benchmark pairing WikiScenes internet data with Google Earth reference models.
- Quantitative Boost: When initialized with COLMAP, the method improved the Mean Transformation Accuracy (MTA) from 66% to 81%.
- Robustness: Unlike feed-forward models (MASt3R, π3) that collapsed in these tests, the proposed method maintained structural integrity.
- Generalization: The method also worked using reference models built from YouTube drone videos, proving it isn't limited to Google Earth data.
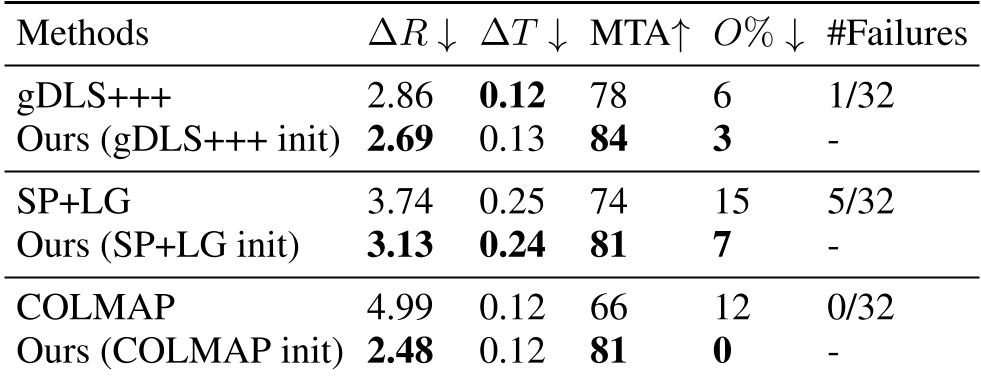 Caption: Comparison across various initializations. Note the significant reduction in Outlier % for our method.
Caption: Comparison across various initializations. Note the significant reduction in Outlier % for our method.
Critical Analysis & Conclusion
Takeaway
The paper successfully argues that semantics are the bridge across domain gaps. By moving from pixel-matching to feature-matching in 3D space, we can ground fragmented data into a unified global coordinate system.
Limitations
- Initialization Sensitivity: Like most inverse optimization tasks, if the starting "guess" is too far off, the optimizer might get stuck in a local minimum.
- Sparse Data: Alignment becomes less reliable with very small sets (under 6 images).
Future Outlook
This approach paves the way for "World-Scale" digital twins. Imagine a future where every tourist photo is automatically "grounded" into a global 3D semantic map, allowing for seamless updates to the world model in real-time. Integrating language-based features (e.g., CLIP) could further allow users to navigate these 3D scenes using natural language queries like "Find the Gothic windows on the north side."