ByteDance introduces Seed1.8, a generalized real-world foundation model designed for agency. It integrates robust LLM and VLM capabilities with multi-step execution, achieving SOTA performance on tasks like GUI navigation (OSWorld, AndroidWorld) and complex agentic search while maintaining competitive reasoning benchmarks.
TL;DR
ByteDance has unveiled Seed1.8, a foundation model explicitly engineered for Generalized Real-World Agency. Moving beyond simple text generation, Seed1.8 unifies multimodal perception, multi-step planning, and tool execution. It doesn't just "talk"; it operates GUI interfaces, solves graduate-level science via visual input, and scales its "thinking" based on task complexity. It notably outperforms GPT-5-high and Gemini-3-pro in key agentic benchmarks like GAIA and OSWorld.
The Motivation: Why Reasoning Isn't Enough
The "bottleneck" in current AI development isn't just a lack of parameters; it's the Agency Gap. While models can pass the Bar Exam or solve IMO math problems, they often struggle to book a flight across three different websites or debug a complex scientific codebase. ByteDance identifies that real-world utility requires three pillars:
- Unified Interaction: Moving away from task-specific pipelines to a single model that sees, thinks, and acts.
- Inference Scaling: The ability to trade-off latency for solution quality via "Thinking Modes."
- Economic Utility: Aligning evaluation with professional workflows (Law, Finance, Education) rather than just academic trivia.
Methodology: Perception Meets Multi-Step Execution
1. Thinking Modes & Inference Efficiency
Seed1.8 introduces a spectrum of Thinking Modes (no_think, low, medium, high). This allows the model to allocate more test-time compute to "hard" problems. For instance, on the Mathvision benchmark, the model's performance peaks at 81.3, showing a steep scaling trajectory compared to its predecessor.
2. Native Multi-Modal Grounding
Unlike models that use external OCR, Seed1.8 utilizes native visual perception. This is critical for GUI Agents. By interpreting screenshots directly, the model can operate browsers and mobile apps where programmatic APIs are non-existent.
3. Video Agency with "VideoCut"
To handle the temporal complexity of video, Seed1.8 uses a tool called VideoCut. It can specifies timestamps and FPS to "replay" specific segments in high detail—essentially giving the model a "slow-motion" look at specific events to solve multi-hop reasoning questions.
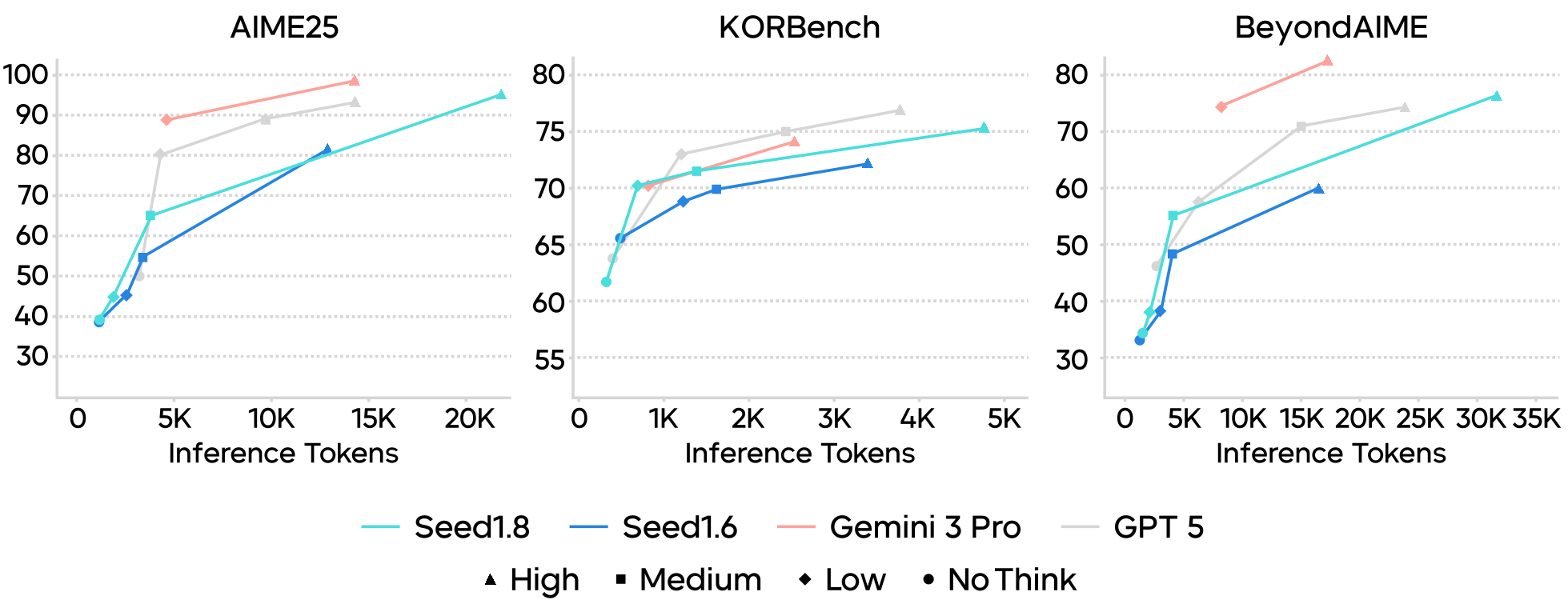 Figure 1: Thinking efficiency comparison on textual reasoning tasks reveals that Seed1.8 dominates the Pareto frontier of performance vs. compute.
Figure 1: Thinking efficiency comparison on textual reasoning tasks reveals that Seed1.8 dominates the Pareto frontier of performance vs. compute.
Experiments: Dominating the Agency Benchmarks
Seed1.8 was put through a gauntlet of "Agentic" benchmarks that simulate real work:
- GAIA: Scored 93.2, significantly ahead of GPT-5-high (76.7).
- GUI Operation: Reached 61.9 on OSWorld and 85.9 on Online-Mind2web, establishing it as one of the most capable "Computer Use" models currently available.
- Economic Fields: It achieved the highest scores in Education and Customer Support Q&A internal benchmarks, proving it can follow complex Standard Operating Procedures (SOPs).
Multimodal Token Efficiency
One of the most impressive technical feats is its token efficiency. In long-video understanding (CGBench, LVBench), Seed1.8 achieves higher accuracy with a 32K token budget than Seed1.5-VL did with 80K tokens.
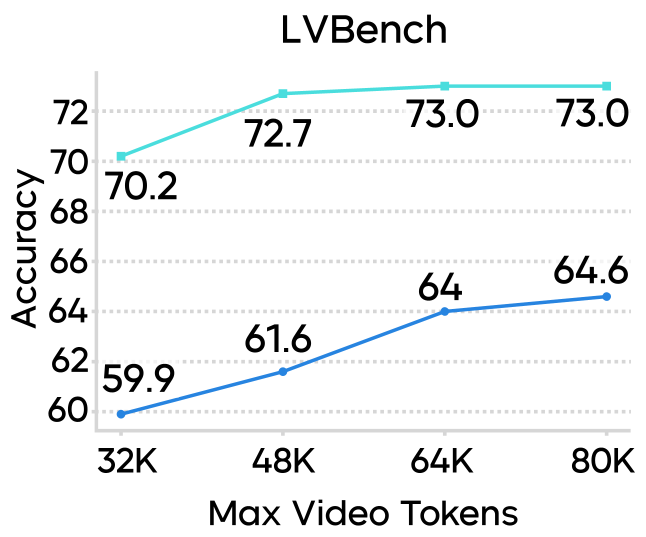 Figure 2: Comparison of accuracy across various video benchmarks as the token budget scales.
Figure 2: Comparison of accuracy across various video benchmarks as the token budget scales.
Critical Insights: The "High-Value" Pivot
The most significant takeaway from the Seed1.8 report is the shift in Evaluation Philosophy. ByteDance isn't just chasing MMLU scores. They are building benchmarks like XpertBench (expert-level law/finance) and World Travel (multi-constraint optimization).
For example, in a Scientific Software Engineering task, the model didn't just generate code; it diagnosed a missing file in a Docker container, recovered the mathematical conformal factor for a black hole simulation, and implemented a numerically stable C++ solution. This level of cross-domain synthesis is the true hallmark of generalized agency.
Conclusion & Future Outlook
Seed1.8 proves that the future of AI is not just "chat," but "action." By integrating Thinking Modes and Native Multimodal perception, ByteDance has created a model that can feasibly automate expert-level workloads.
Limitations: While powerful, there is still a gap between AI and human performance in high-frame-rate motion perception (e.g., the TOMATO benchmark). Additionally, long-horizon tasks (100+ steps) still face stability challenges that require further "thinking" refinement.
Final Takeaway: Seed1.8 is a blueprint for the next generation of productive AI—one that prioritizes ROI and professional utility over simple conversational fluency.