本文提出了 VisPrompt,一个针对带噪声标签环境的轻量级视觉引导 Prompt Learning 框架。该方法通过跨模态注意力机制将图像语义注入 Prompt,在保持剪裁好的 VLM(如 CLIP)参数冻结的同时,显著提升了模型在标签污染下的鲁棒性,并在多个基准数据集上达到 SOTA。
TL;DR
在视觉语言模型(VLM)的微调中,标签噪声一直是导致模型性能崩溃的“杀手”。本文提出的 VisPrompt 框架,打破了传统“只听标签,不看图像”的更新模式。它利用 Cross-modal Attention 将图像本身的语义作为锚点,通过 FiLM 调制 自适应地将可靠的视觉信息注入到 Prompt 中。实验证明,即便在高达 75% 的极高噪声下,VisPrompt 依然能保持惊人的稳健性。
背景定位:由于 Prompt 太“瘦”,所以它很“怕”噪声
Prompt Learning(如 CoOp)近年来因其极高的参数效率(PEFT)大火。然而,它的优势也是它的弱点:由于预训练的视觉和文本编码器都是冻结的,所有的下游任务适配压力全部压在了那几个可学习的 Context Tokens 上。
在存在 Label Noise 的场景下,这些稀少的 Prompt 参数会直接暴露在错误的梯度下,迅速向错误的类语义发生“漂移(Drift)”。
核心洞察:图像才是最稳的“锚”
作者认为,虽然标签(Label)可能会错,但图像(Image)内容是实打实存在的。如果让 Prompt 在更新时,不仅看标签给了什么目标,还要看图像里到底有什么,就能有效地纠正噪声导致的偏差。
这一直觉催生了 VisPrompt 的架构设计。
方法论详解:从“标签驱动”到“视觉引导”
VisPrompt 的核心架构分为两个关键阶段:
-
跨模态视觉 Prompt 调节 (Cross-modal Visual Prompt Conditioning): 模型不再直接优化静态向量,而是使用 Cross-modal Attention。将 Prompt Tokens 作为 Query,去检索图像编码器输出的局部 Patch 嵌入。这样,训练得到的 Prompt 实际上是“看图说话”,它的表达被限制在了当前实例的视觉语义范围内。
-
基于 FiLM 的鲁棒调制 (FiLM-based Robust Modulation): 图像信息的质量并非千篇一律。为了防止低质量或无关的视觉特征干扰,作者引入了 FiLM (Feature-wise Linear Modulation) 机制。通过一个轻量级的门控网络,模型可以自适应地决定:对于这个特定样本,我应该吸纳多少视觉信息?哪些维度的特征需要放大或抑制?
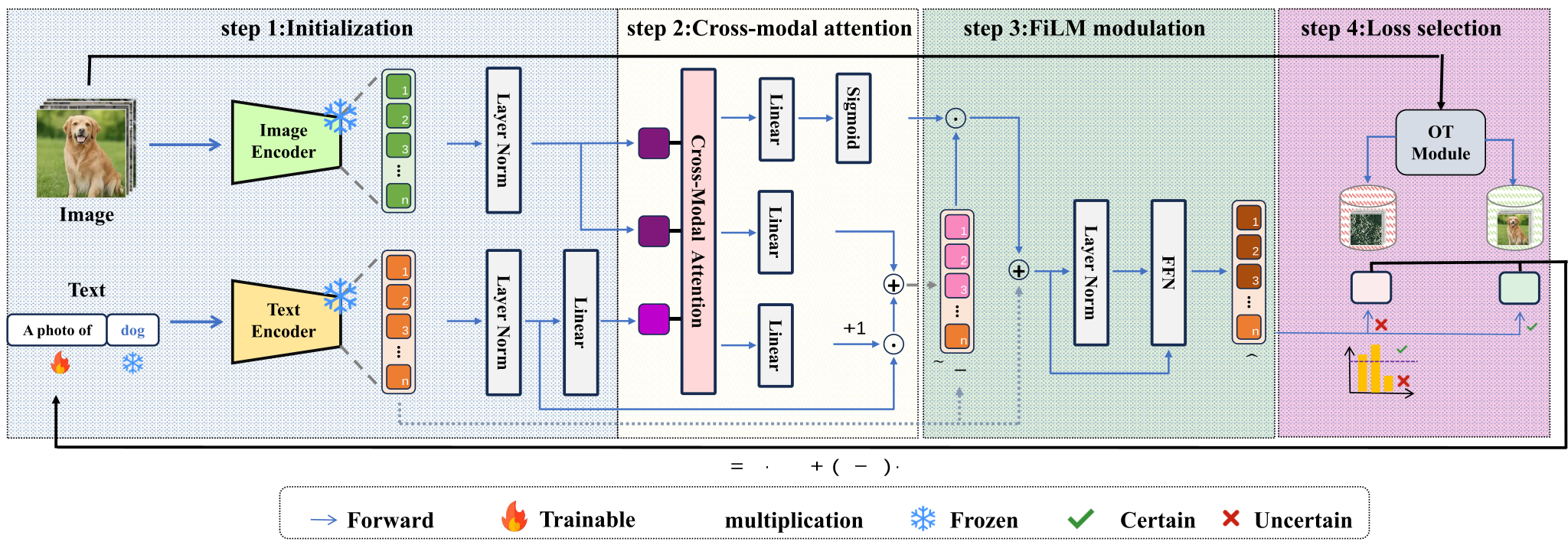 图 1: VisPrompt 总体架构,展示了从视觉特征投影到 FiLM 调制的完整流程。
图 1: VisPrompt 总体架构,展示了从视觉特征投影到 FiLM 调制的完整流程。
此外,为了进一步纯化训练过程,作者还利用 最优传输 (Optimal Transport) 理论对样本进行可靠性预测,将样本分为“可信”和“不可信”两类,分别施加标准 CE Loss 和鲁棒的 GCE Loss。
实验与结果:即便 75% 标签全错,我也能 hold 住
VisPrompt 在六个合成噪声数据集和一个真实噪声数据集(Food101N)上进行了严苛的测试。
- 极高噪声下的统治力: 在 EuroSAT 等数据集上,当噪声率达到 75% 时,传统的 CoOp 甚至其他鲁棒方法(如 JoAPR)性能大幅跳水,而 VisPrompt 依旧能保持极高的准确率。
- 参数效率高度优化: 虽然引入了注意力机制和 FiLM 模块,但新增的可训练参数量仅占总体的不到 1%,完美契合了提示学习的轻量化初衷。
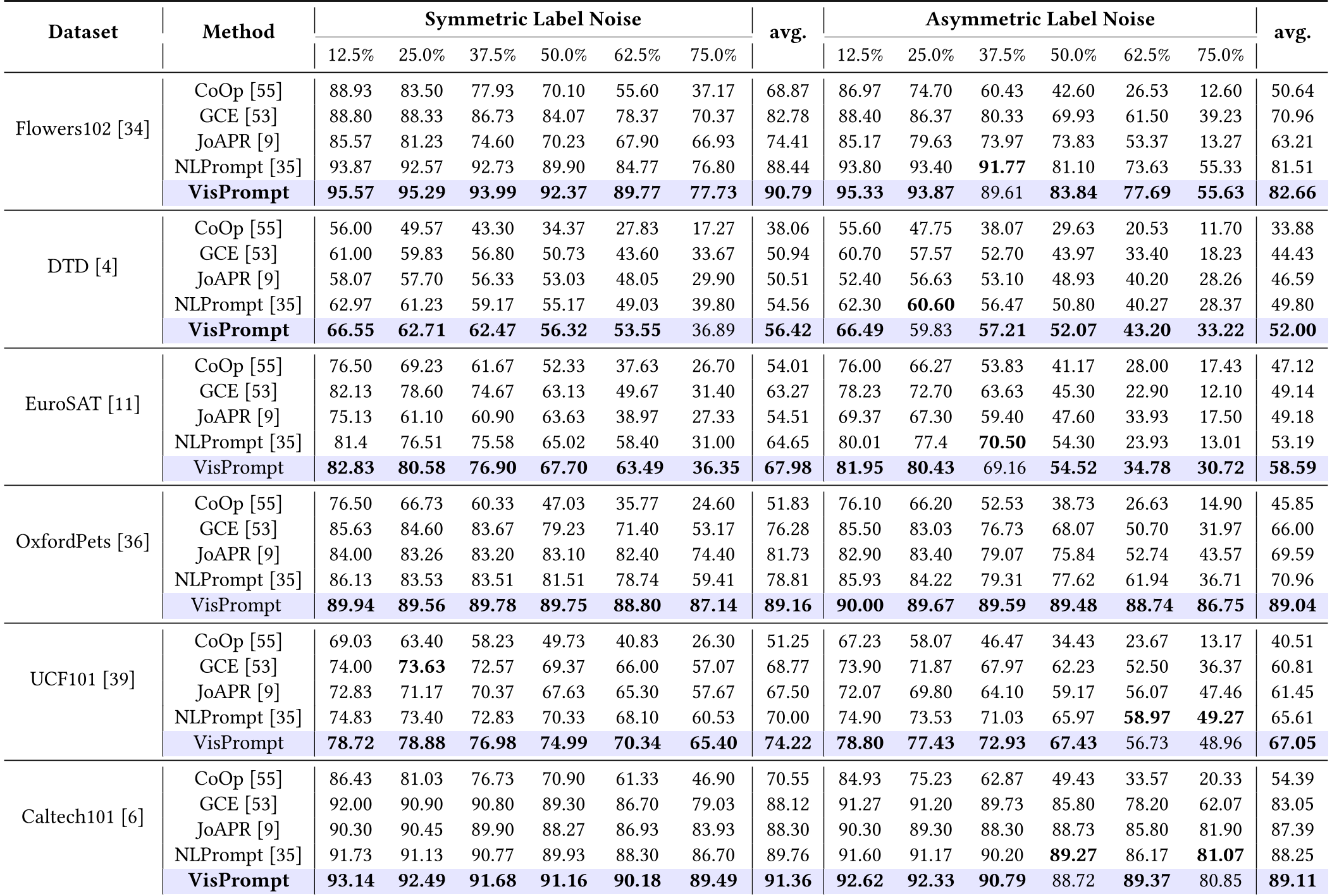 表 1: 在对称和非对称噪声下的详细准确率对比,VisPrompt 在几乎所有配置下均位居 SOTA。
表 1: 在对称和非对称噪声下的详细准确率对比,VisPrompt 在几乎所有配置下均位居 SOTA。
深度洞察与总结 (Critical Analysis)
为什么 VisPrompt 比前人更强? 以前的方法大多在做“样本清洗”——试图猜哪些标签是错的。一旦猜错,模型就会陷入死循环。而 VisPrompt 走的是“语义增强”的路线。即使模型没发现这个标签是错的,视觉引导的 Prompt 也会因为它与错误标签语义的不匹配(Visual-Label Dissimilarity)而产生一种内在的抵抗力(Resistance)。
局限性与展望: 目前的 VisPrompt 主要是在 CLIP 架构上进行验证,未来是否能推广到更复杂的视频理解或多模态大模型(MLLM)中值得关注。此外,跨模态注意力虽然有效,但也带来了一定的推理计算开销,如何在边缘端进一步优化是下一点优化的目标。
总结: VisPrompt 告诉我们:在多模态时代,解决单模态(标签)的缺陷,最好的武器往往藏在另一个模态(视觉)之中。